Python自动化之数据驱动让你的脚本简洁10倍【推荐】

前言
数据驱动是一种思想,让数据和代码进行分离,比如爬虫时,我们需要分页爬取数据时,我们往往把页数 page 参数化,放在 for 循环 range 中,假如没有 range 这个自带可以生产数字序列的方法可以用,我们是不是得手动逐个添加?

现实场景中就存在大量这样的例子,比如我之前写的爬取上海各地区房租情况的时候,对地区进行遍历的时候,为了偷懒,我直接把这些地区的拼音全称放在了列表里,组合成各地区房源的链接。最后文章写完了,有读者反馈,少了徐汇区的统计数据。这种小数量的数据都出现了纰漏,可想而知,对于大量的数据,怎么保证数据的完整和准确性?我们需要把两者分离,数据专门储存在特定文件(比如 Excel 文件)。

举一个小栗子:登录流程,在测试的时候,除了测试登录成功的场景,我们往往需要测到各种登录异常的场景。
写几条很常见的案例如下:
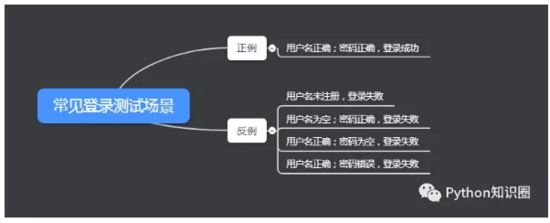
比如上面写了 5 条案例,数据和脚本不做分离的话,我们写自动化测试脚本需要写 5 条。

5 条案例中,脚本都是基本一样的,只是输入框输入的数据不一样罢了。
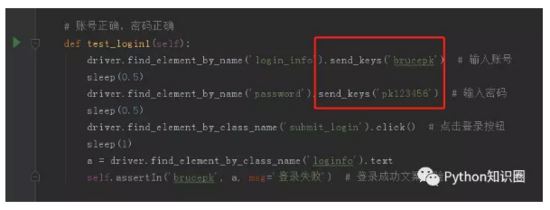
数据分离
我们完全可以把数据存储在 Excel 表中,我们通过循环读取 Excel 表中的数据来实现一条脚本执行多条数据。
我们先封装一个操作 Excel 文件的类,需要先安装导入包 openpyxl。
我们用这个库可以做一下功能:读取表格数据、保存执行结果。
我们先在类下写一个打开 Excel 文件的初始化方法,构造方法的作用是,当类被实例化后,会立即调用构造方法。

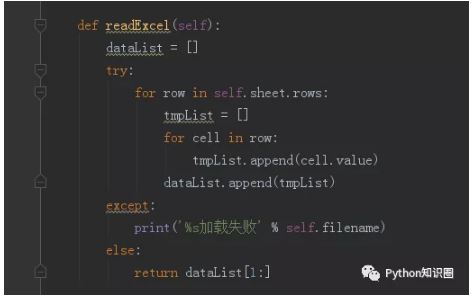
读取表格数据
然后我们写一个读取 Excel 数据的方法,读取数据后返回数据列表,以便之后调用获取对应的数据,因为第 1 列数据是序号,所以直接返回第 2 列之后的数据。
保存执行结果
实际结果和预期结果对比后,我们需要标记执行结果是 pass 或者 fail,我们需要保存结果,保存到对应的单元格中。

我们看看我们的案例格式:
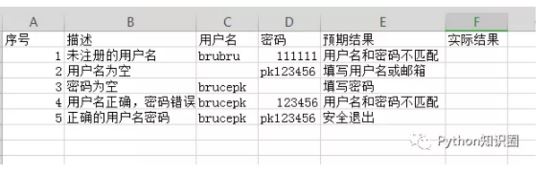
这样的话,我们脚本就不用写 5 条了,调用 Excel 文件的数据,循环执行案例即可,不仅逻辑清晰,还方便了后期的维护。
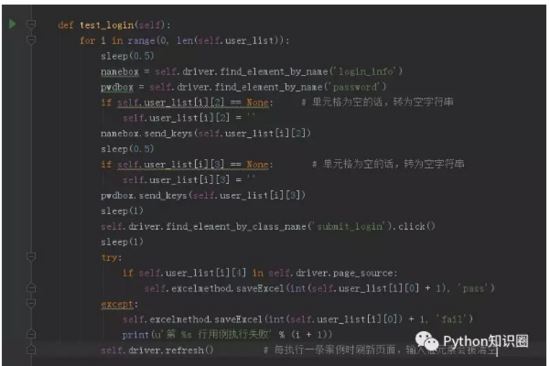
这样,测试数据和脚本分离后,不同的测试数据用不同的 Excel 文件保存即可。
吃饭时或者下班时执行下测试脚本,吃完饭后或者第二天上班时,查看下 Excel 里的执行结果,有 fail 再手动看看能否复现,是不是很高效?
总结
以上所述是小编给大家介绍的Python自动化之数据驱动让你的脚本简洁10倍,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对【听图阁-专注于Python设计】网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!