python处理“&#”开头加数字的html字符方法
python如何处理“&#”开头加数字的html字符,比如:风水这类数据。
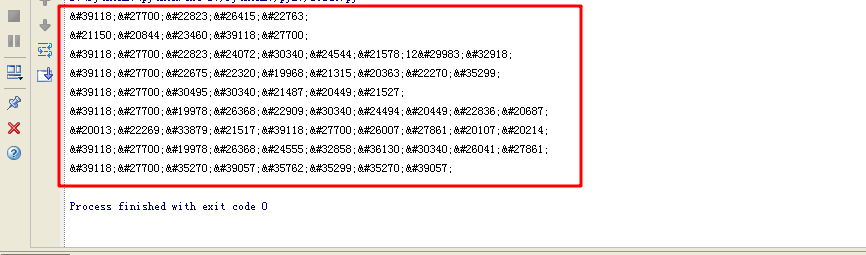
用python抓取数据时,有时会遇到想要数据是以“&#”开头加数字的字符,比如图中所示的这些:
风水大术士

这些字符需要再次转换才能变回中文内容。这些字符需要再次转换才能变回中文内容。
Python2.7版本
在python2.7版本中,使用import HTMLParser
定义变量,再定义转换代码。
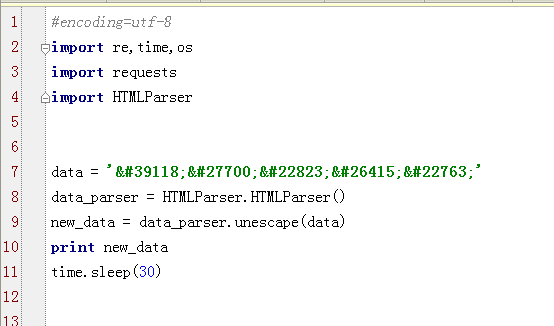
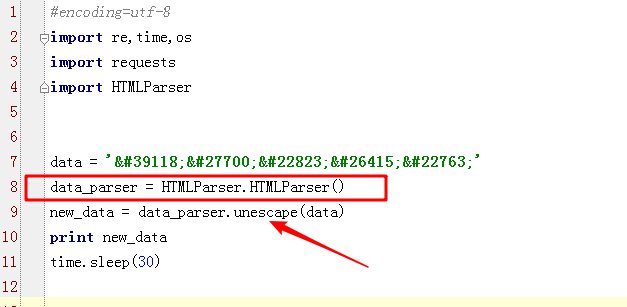
代码中最重要的是“data_parser = HTMLParser.HTMLParser()”,通过此才能用“.unescape()”方法。
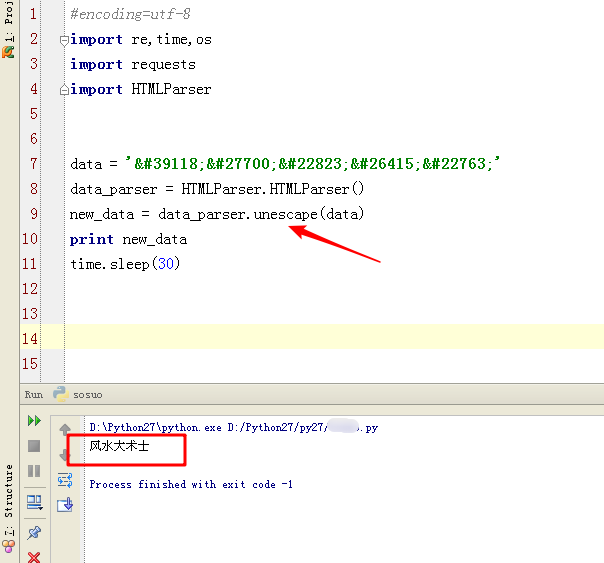
测试运行,这串字符串正常输出了中文。
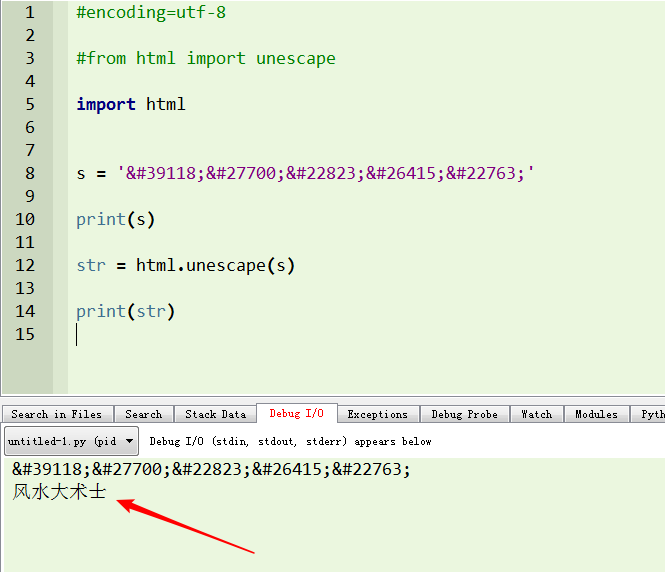
Python3.7+版本
在最新python版本中,不能用上面的导入方法。可以用"import html"或者“from html import unescape”。这里使用"import html"做测试。
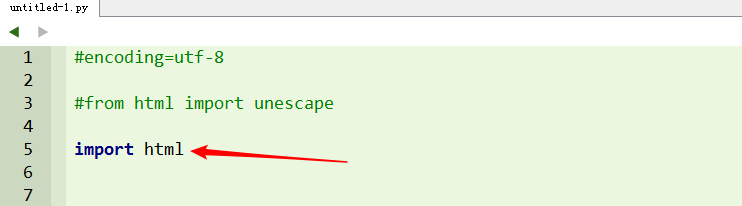
导入html后,直接用".unescape()"来处理字符串。
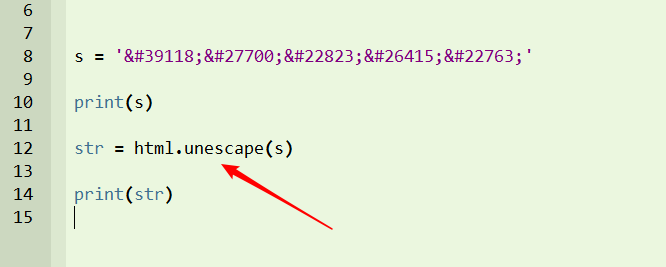
运行后,正常转换成了中文字符。
感谢大家的阅读和对【听图阁-专注于Python设计】的支持。