selenium获取当前页面的url、源码、title的方法
此篇博客学习的api如标题,分别是:
current_url 获取当前页面的url;
page_source 获取当前页面的源码;
title 获取当前页面的title;
将以上方法按顺序练习一遍,效果如GIF:
from selenium import webdriver
from time import sleep
sleep(2)
driver = webdriver.Chrome()
driver.get("https://www.baidu.com/")
# 移动浏览器观看展示
driver.set_window_size(width=500, height=500, windowHandle="current")
driver.set_window_position(x=1000, y=100, windowHandle='current')
sleep(2)
# 获取当前页面title并断言
title = driver.title
print("当前页面的title是:", title, "\n")
assert title==u"百度一下,你就知道","页面title属性值错误!"
sleep(2)
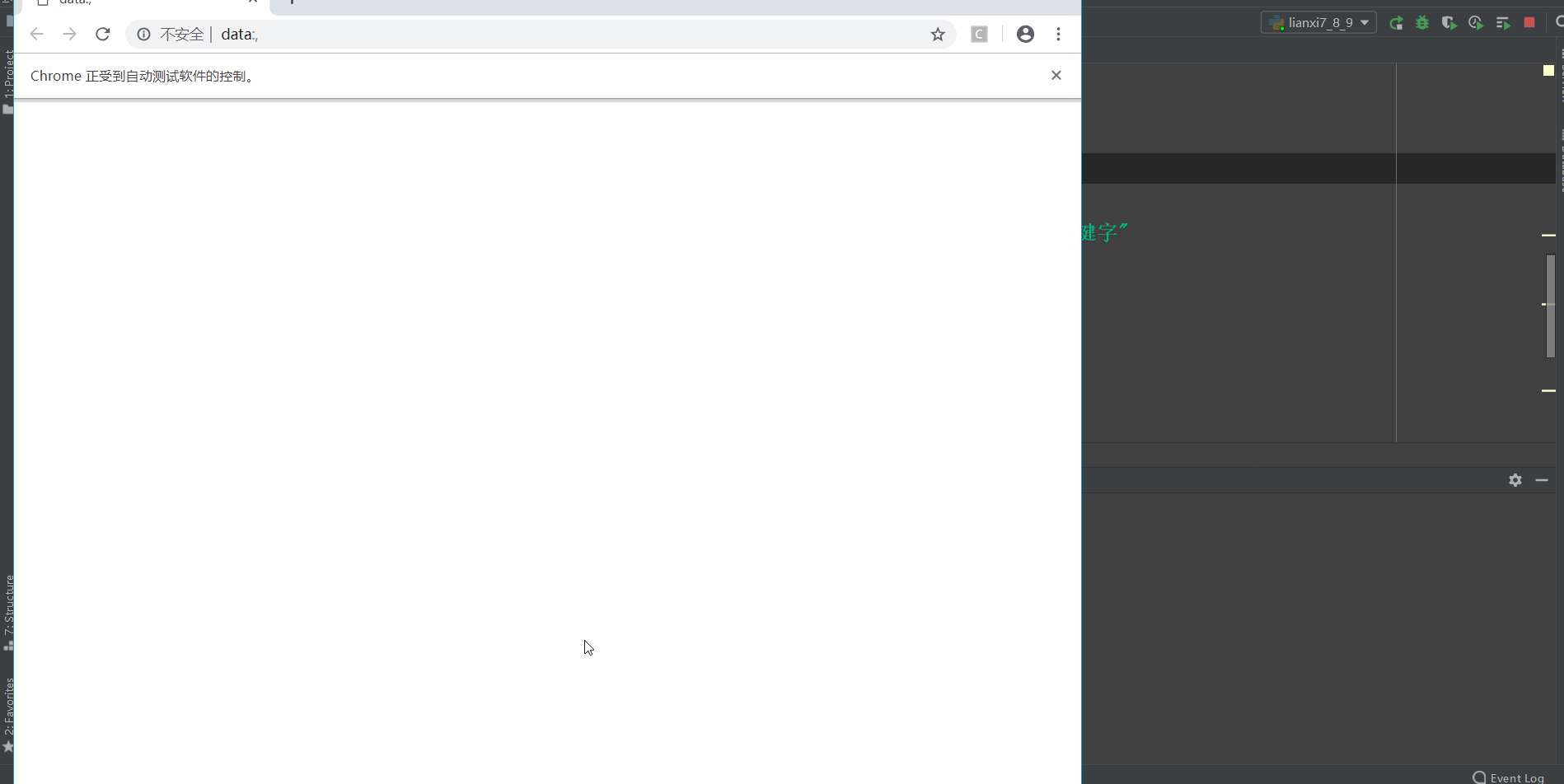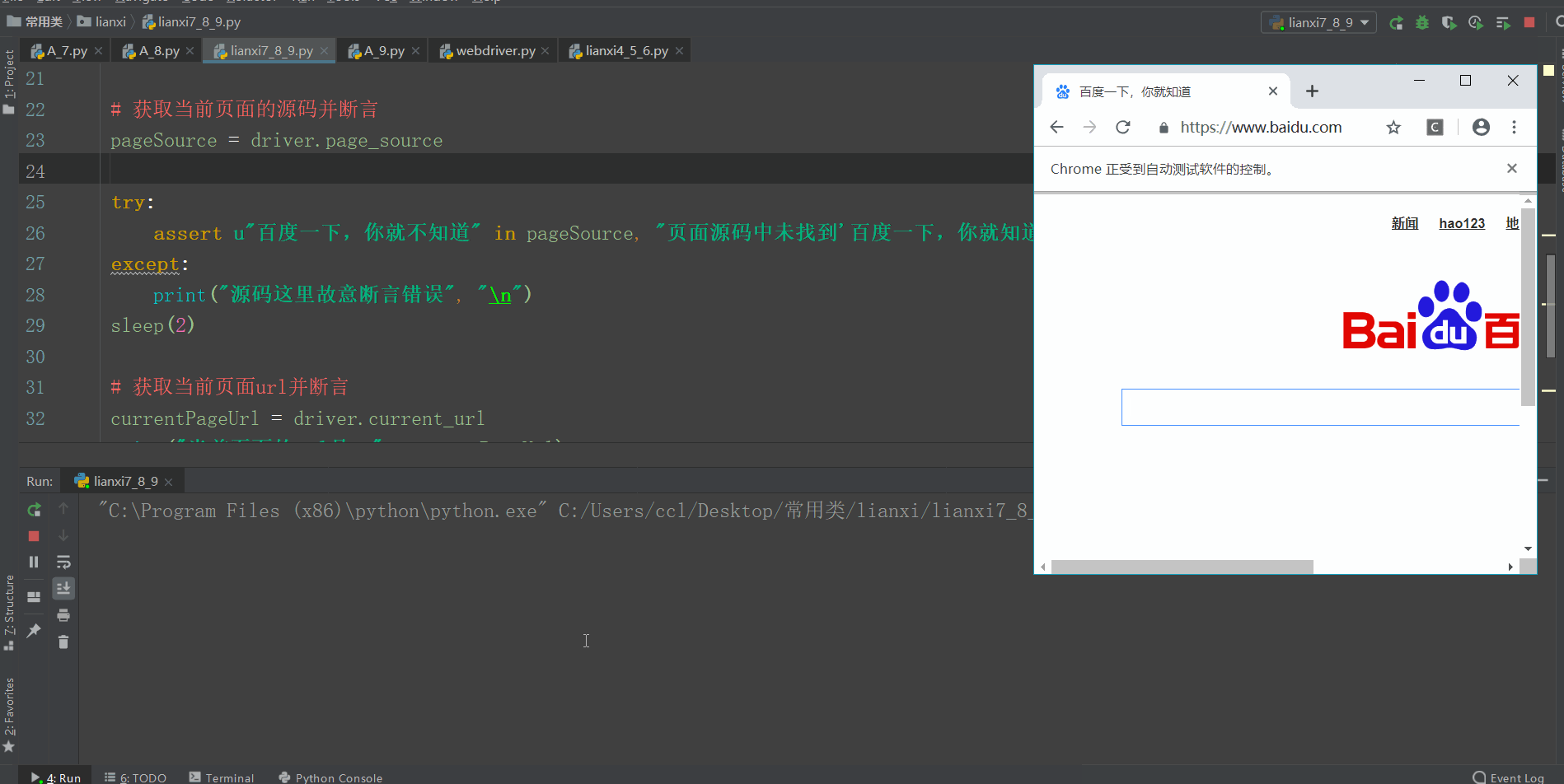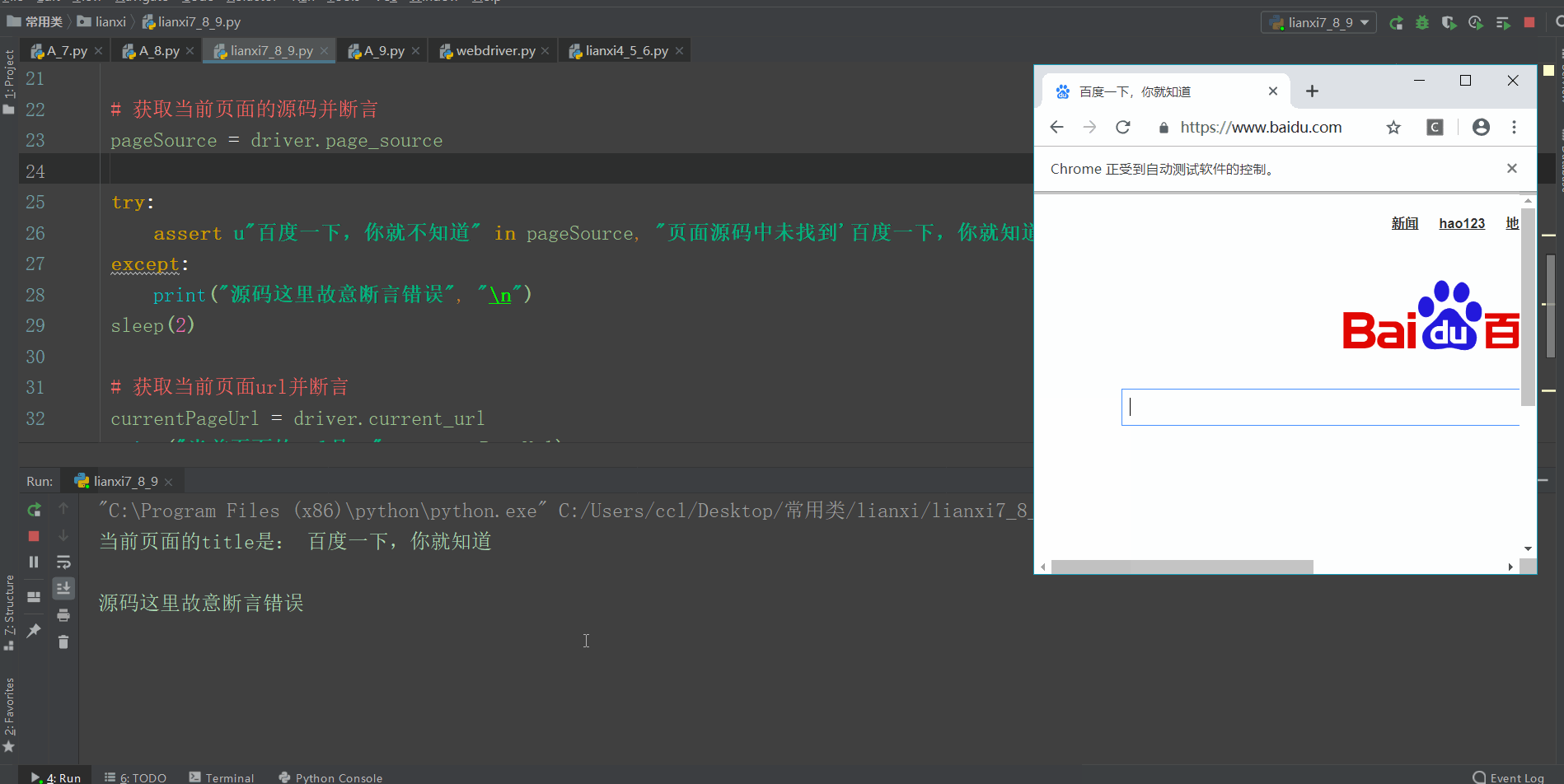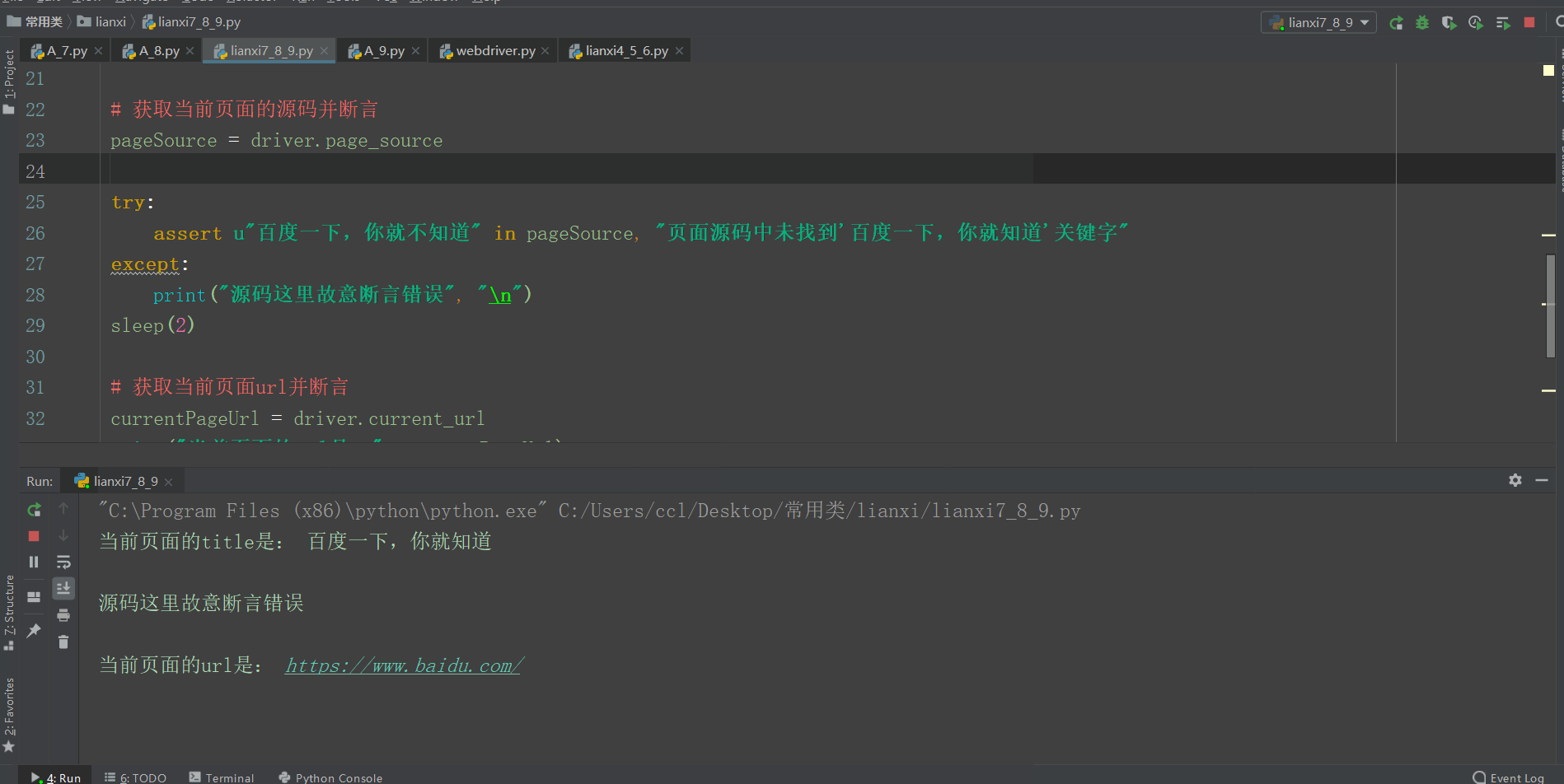
# 获取当前页面的源码并断言
pageSource = driver.page_source
try:
assert u"百度一下,你就不知道" in pageSource, "页面源码中未找到'百度一下,你就知道'关键字"
except:
print("源码这里故意断言错误", "\n")
sleep(2)
# 获取当前页面url并断言
currentPageUrl = driver.current_url
print("当前页面的url是:", currentPageUrl)
assert currentPageUrl == "https://www.baidu.com/", "当前网页网址非预期!"
sleep(2)
driver.quit()
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。