selenium跳过webdriver检测并模拟登录淘宝
简介
模拟登录淘宝已经不是一件新鲜的事情了,过去我曾经使用get/post方式进行爬虫,同时也加入IP代理池进行跳过检验,但随着大型网站的升级,采取该策略比较难实现了。因为你使用get/post方式进行爬取数据,会提示需要登录,而登录又是一大难题,需要滑动验证码验证。当你想使用IP代理池进行跳过检验时,发现登录时需要手机短信验证码验证,由此可以知道旧的全自动爬取数据对于大型网站比较困难了。
selenium是一款优秀的WEB自动化测试工具,所以现在采用selenium进行半自动化爬取数据,支持模拟登录淘宝和自动处理滑动验证码。
编写思路
由于现在大型网站对selenium工具进行检测,若检测到selenium,则判定为机器人,访问被拒绝。所以第一步是要防止被检测出为机器人,如何防止被检测到呢?当使用selenium进行自动化操作时,在chrome浏览器中的consloe中输入windows.navigator.webdriver会发现结果为Ture,而正常使用浏览器的时候该值为False。所以我们将windows.navigator.webdriver进行屏蔽。
在代码中添加:
options = webdriver.ChromeOptions()
# 此步骤很重要,设置为开发者模式,防止被各大网站识别出来使用了Selenium
options.add_experimental_option('excludeSwitches', ['enable-automation'])
self.browser = webdriver.Chrome(executable_path=chromedriver_path, options=options)
同时,为了加快爬取速度,我们将浏览器模式设置为不加载图片,在代码中添加:
options = webdriver.ChromeOptions()
# 不加载图片,加快访问速度
options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2})
至此,关键的步骤我们已经懂了,剩下的就是编写代码的事情了。在给定的例子中,需要你对html、css有一定了解。
比如存在以下代码:
self.browser.find_element_by_xpath('//*[@class="btn_tip"]/a/span').click()
taobao_name = self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '.site-nav-bd > ul.site-nav-bd-l > li#J_SiteNavLogin > div.site-nav-menu-hd > div.site-nav-user > a.site-nav-login-info-nick ')))
print(taobao_name.text)
第1行代码指的是从根目录(//)开始寻找任意(*)一个class名为btn_tip的元素,并找到btn_tip的子元素a标签中的子元素span
第2行代码指的是等待某个CSS元素出现,否则代码停留在这里一直检测。以.开头的在CSS中表示类名(class),以#开头的在CSS中表示ID名(id)。A > B,指的是A的子元素B。所以这行代码可以理解为寻找A的子元素B的子元素C的子元素D的子元素E出现,否则一直在这里检测。
第3行代码指的是打印某个元素的文本内容
使用教程
点击这里下载下载chrome浏览器
查看chrome浏览器的版本号,点击这里下载对应版本号的chromedriver驱动
pip安装下列包
[x] pip install selenium
点击这里登录微博,并通过微博绑定淘宝账号密码
在main中填写chromedriver的绝对路径
在main中填写微博账号密码
#改成你的chromedriver的完整路径地址 chromedriver_path = "/Users/bird/Desktop/chromedriver.exe" #改成你的微博账号 weibo_username = "改成你的微博账号" #改成你的微博密码 weibo_password = "改成你的微博密码"
演示图片
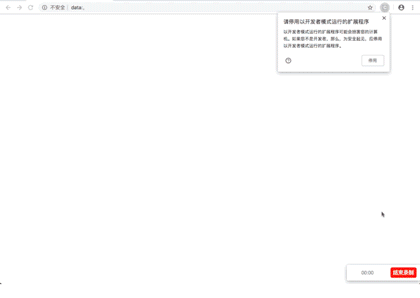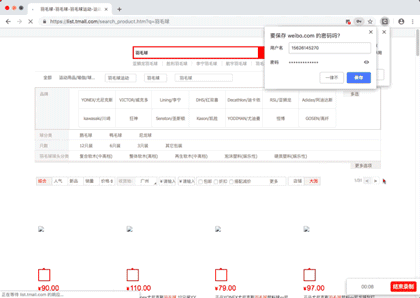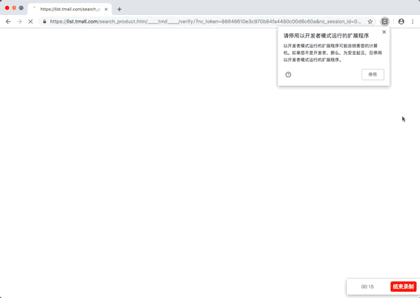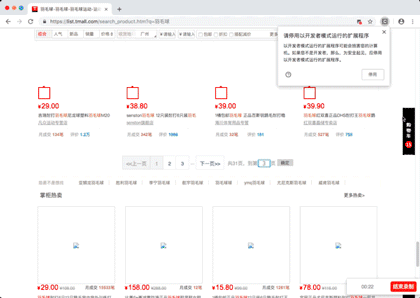
源代码
项目源代码在GitHub仓库
项目持续更新,欢迎您star本项目
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】