python文本数据处理学习笔记详解
最近越发感觉到限制我对Python运用、以及读懂别人代码的地方,大多是在于对数据的处理能力。
其实编程本质上就是数据处理,怎么把文本数据、图像数据,通过python读入、切分等,变成一个N维矩阵,然后再带入别人的模型,bingo~跑出来一个结果。结果当然也是一个矩阵或向量的形式。
所以说,之所以对很多模型、代码束手无策,其实还是没有掌握好数据处理的“屠龙宝刀”,无法对海量数据进行“庖丁解牛”般的处理。因此,我想以一个别人代码中的一段为例,仔细琢磨文本数据处理的精妙之处,争取能够加深对这方面的运用与理解。
1) 问题描述
数据:某个区域181天内的访客数据,格式如下,第一列代表访客的名称,第二列代表这位访客在181天内到达这片区域的时刻:
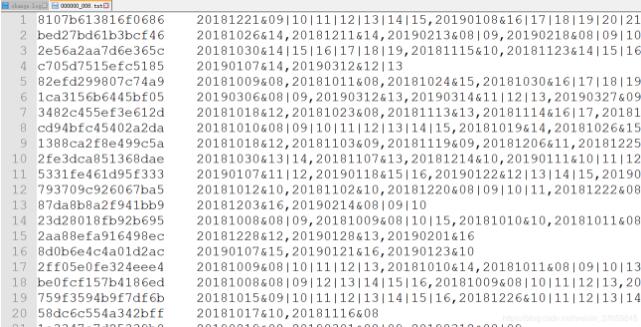
目的:将访客数据进行统计,并时间离散化,按照天 /周/小时处理为72624的三维矩阵。
也就是说,矩阵中的每一个值,代表该区域 周X、第几周、几点 的到访人数,如
[1,5,19]=100,代表第5周的周一晚上7点的人数为100。
2)难点
当然是对我的难点。
2.1)怎么按行统计
2.2)怎么进行时间离散化(存为天、周、时刻的矩阵)
3)代码
import time
import numpy as np
import sys
import datetime
import pandas as pd
import os
#用字典查询代替类型转换,可以减少一部分计算时间
date2position = {}
datestr2dateint = {}
str2int = {}
for i in range(182):
date = datetime.date(day=1, month=10, year=2018)+datetime.timedelta(days=i)
#print(i,":",date)
date_int = int(date.__str__().replace("-", ""))
date2position[date_int] = [i%7, i//7]
datestr2dateint[str(date_int)] = date_int
#print(datestr2dateint)
#
for i in range(24):
str2int[str(i).zfill(2)] = i
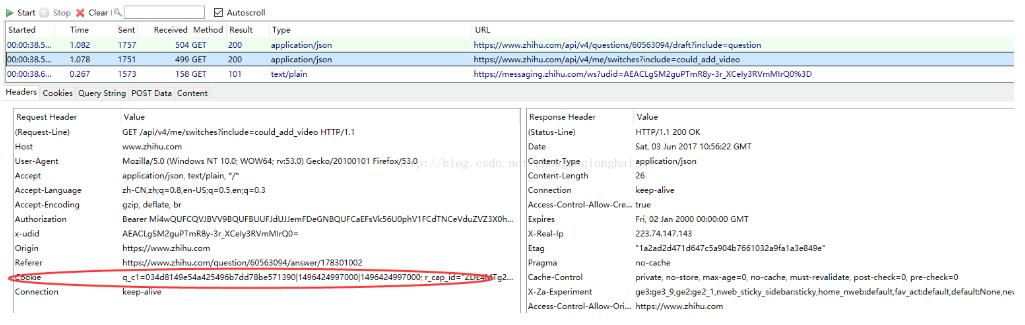
f=open("D:\BaiDuBigData19-URFC-master\\UrbanRegionFunctionClassification-master\data\\train_visit\\000000_008.txt")
#table = pd.read_csv(f, header=None,error_bad_lines=False)
table = pd.read_csv(f, header=None,sep='\t')
#print(table.shape)
#print(table.ix[1])
strings = table[1]
#print(strings)
init = np.zeros((7, 26, 24))
for string in strings:
temp = []
for item in string.split(','):
temp.append([item[0:8], item[9:].split("|")])
for date, visit_lst in temp:
# x - 第几周
# y - 第几天
# z - 几点钟
# value - 到访的总人数
# print(visit_lst)
print(date)
x, y = date2position[datestr2dateint[date]]
for visit in visit_lst: # 统计到访的总人数
init[x][y][str2int[visit]] += 1
#print(init[x][y][str2int[visit]])```
3.1)创建字典,时间离散化,节省时间
此处创建了三个字典,让我们看一下代码实现以及打印结果:
date2position = {}
datestr2dateint = {}
str2int = {}
for i in range(182):
date = datetime.date(day=1, month=10, year=2018)+datetime.timedelta(days=i)
#print(i,":",date)
date_int = int(date.__str__().replace("-", ""))
date2position[date_int] = [i%7, i//7]
datestr2dateint[str(date_int)] = date_int
for i in range(24):
str2int[str(i).zfill(2)] = i
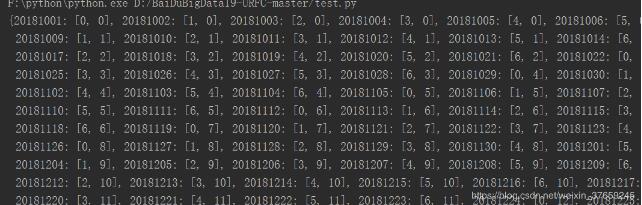
打印一下 date2position:
打印一下 datestr2dateint:

打印str2int:

可以看出,datestr2dateint是将str的日期,转换为了int的日期。
而date2position 才是计算出的每一个具体的日期,代表了第几周、第几天。
str2int代表了一天中的24个时刻。
3.2)读取文件,按行获取字符串
注意到文本的分隔符为\t(区分用户名与到访信息的分割),于是采用
f=open("D:\BaiDuBigData19-URFC-master\\UrbanRegionFunctionClassification-master\data\\train_visit\\000000_008.txt")
#table = pd.read_csv(f, header=None,error_bad_lines=False)
table = pd.read_csv(f, header=None,sep='\t')
然后用strings读取到访信息,也就是table的第二列:
strings = table[1]
3.3)切分字符串
首先,strings为:
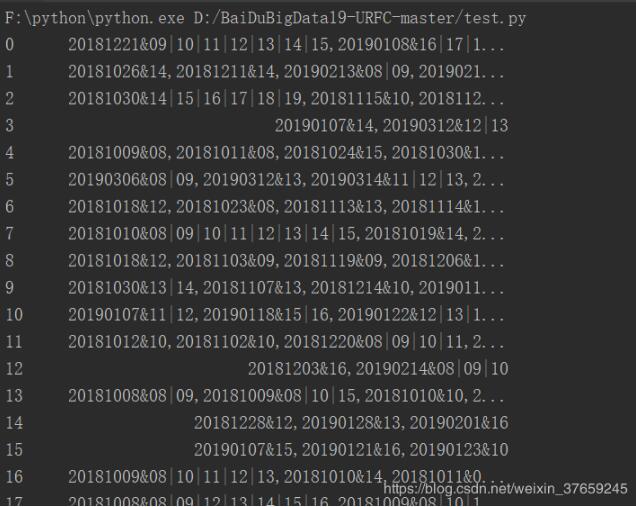
可以看到每一行string,为一个用户的到访记录,循环读取。其中,不同日期的到访是用“,”隔开,故要使用:
for string in strings:
temp = []
for item in string.split(','):
item就可以分开每一个日期的到访记录了:
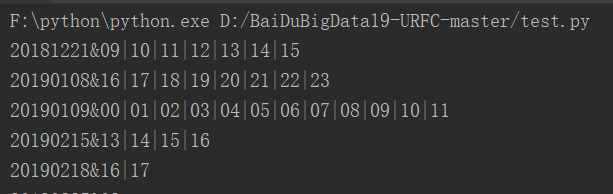
其后,使用temp列表,每一行存储日期和时刻。
如第一个item为 20181221&09|10|11|12|13|14|15
日期为 item[0:8],
时刻之间使用分隔符“|”隔开,故可以通过item[9:].split("|")得到。
temp.append([item[0:8], item[9:].split("|")])
打印一下temp为:
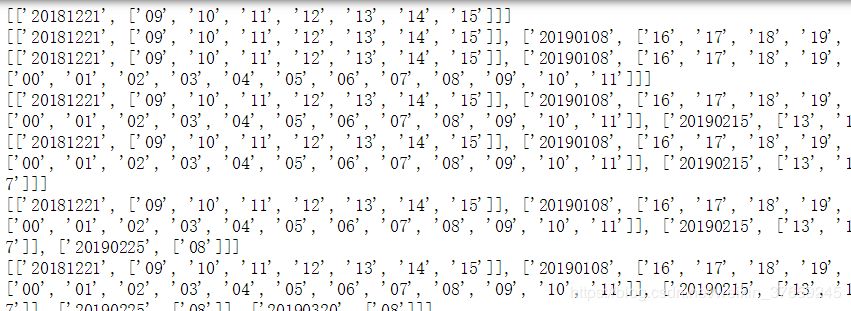
所以需要用两个数据分别存储日期,以及时刻。
首先用来转换成 周、天、时刻的72624矩阵(根据前面的转换函数)
其后根据这个矩阵,统计每一个位置的访客数量
for date, visit_lst in temp: # x - 第几周 # y - 第几天 # z - 几点钟 # value - 到访的总人数 # print(visit_lst) #print(date) x, y = date2position[datestr2dateint[date]] for visit in visit_lst: # 统计到访的总人数 init[x][y][str2int[visit]] += 1
这一段代码很短,但着实是整个时间离散化实现的精髓所在。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。