python操作kafka实践的示例代码
1、先看最简单的场景,生产者生产消息,消费者接收消息,下面是生产者的简单代码。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import json
from kafka import KafkaProducer
producer = KafkaProducer(bootstrap_servers='xxxx:x')
msg_dict = {
"sleep_time": 10,
"db_config": {
"database": "test_1",
"host": "xxxx",
"user": "root",
"password": "root"
},
"table": "msg",
"msg": "Hello World"
}
msg = json.dumps(msg_dict)
producer.send('test_rhj', msg, partition=0)
producer.close()
下面是消费者的简单代码:
from kafka import KafkaConsumer
consumer = KafkaConsumer('test_rhj', bootstrap_servers=['xxxx:x'])
for msg in consumer:
recv = "%s:%d:%d: key=%s value=%s" % (msg.topic, msg.partition, msg.offset, msg.key, msg.value)
print recv
下面是结果:

2、如果想要完成负载均衡,就需要知道kafka的分区机制,同一个主题,可以为其分区,在生产者不指定分区的情况,kafka会将多个消息分发到不同的分区,消费者订阅时候如果不指定服务组,会收到所有分区的消息,如果指定了服务组,则同一服务组的消费者会消费不同的分区,如果2个分区两个消费者的消费者组消费,则,每个消费者消费一个分区,如果有三个消费者的服务组,则会出现一个消费者消费不到数据;如果想要消费同一分区,则需要用不同的服务组。以此为原理,我们对消费者做如下修改:
from kafka import KafkaConsumer
consumer = KafkaConsumer('test_rhj', bootstrap_servers=['xxxx:x'])
for msg in consumer:
recv = "%s:%d:%d: key=%s value=%s" % (msg.topic, msg.partition, msg.offset, msg.key, msg.value)
print recv
然后我们开两个消费者进行消费,生产者分别往0分区和1分区发消息结果如下,可以看到,一个消费者只能消费0分区,另一个只能消费1分区:


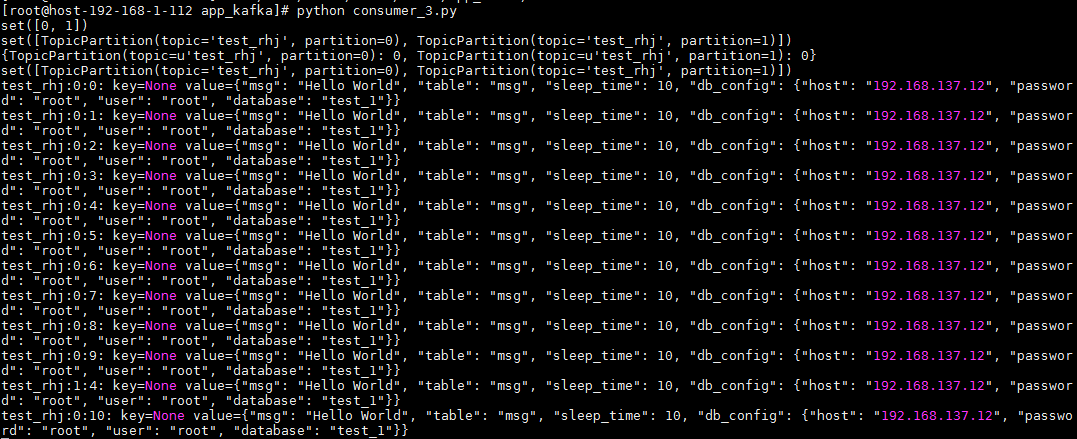
3、kafka提供了偏移量的概念,允许消费者根据偏移量消费之前遗漏的内容,这基于kafka名义上的全量存储,可以保留大量的历史数据,历史保存时间是可配置的,一般是7天,如果偏移量定位到了已删除的位置那也会有问题,但是这种情况可能很小;每个保存的数据文件都是以偏移量命名的,当前要查的偏移量减去文件名就是数据在该文件的相对位置。要指定偏移量消费数据,需要指定该消费者要消费的分区,否则代码会找不到分区而无法消费,代码如下:
from kafka import KafkaConsumer
from kafka.structs import TopicPartition
consumer = KafkaConsumer(group_id='123456', bootstrap_servers=['10.43.35.25:4531'])
consumer.assign([TopicPartition(topic='test_rhj', partition=0), TopicPartition(topic='test_rhj', partition=1)])
print consumer.partitions_for_topic("test_rhj") # 获取test主题的分区信息
print consumer.assignment()
print consumer.beginning_offsets(consumer.assignment())
consumer.seek(TopicPartition(topic='test_rhj', partition=0), 0)
for msg in consumer:
recv = "%s:%d:%d: key=%s value=%s" % (msg.topic, msg.partition, msg.offset, msg.key, msg.value)
print recv
因为指定的便宜量为0,所以从一开始插入的数据都可以查到,而且因为指定了分区,指定的分区结果都可以消费,结果如下:
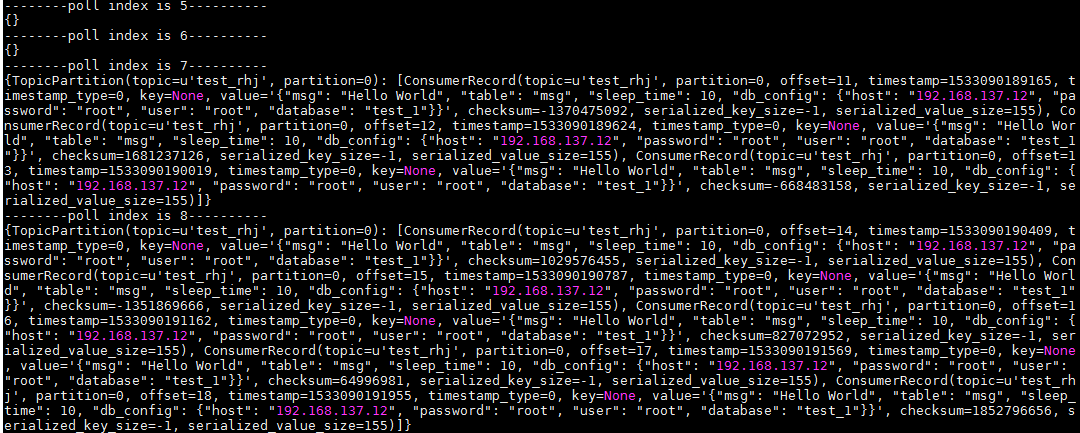
4、有时候,我们并不需要实时获取数据,因为这样可能会造成性能瓶颈,我们只需要定时去获取队列里的数据然后批量处理就可以,这种情况,我们可以选择主动拉取数据
from kafka import KafkaConsumer
import time
consumer = KafkaConsumer(group_id='123456', bootstrap_servers=['10.43.35.25:4531'])
consumer.subscribe(topics=('test_rhj',))
index = 0
while True:
msg = consumer.poll(timeout_ms=5) # 从kafka获取消息
print msg
time.sleep(2)
index += 1
print '--------poll index is %s----------' % index
结果如下,可以看到,每次拉取到的都是前面生产的数据,可能是多条的列表,也可能没有数据,如果没有数据,则拉取到的为空:
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。