如何使用Python实现自动化水军评论
前言
玩博客一个多月了,渐渐发现了一些有意思的事,经常会有人用同样的评论到处刷,不知道是为了加没什么用的积分,还是纯粹为了表达楼主好人。那么问题来了,这种无聊的事情当然最好能够自动化咯,自己也来试了一把,纯属娱乐。
登陆
要评论当然要能够先进行登陆,采用 库进行处理,尝试能否看到自己的消息列表:
结果跳转到登陆界面,好的那看一下登陆界面是怎么登陆的,找到表单:
发现还有一些隐藏的参数,如lt、excution等,好心的程序猿还写明了不能为什么不能直接认证的原因:缺少流水号,那就多访问一次来获取流水号好了,用 来分析页面内容抓取流水号,同时因为要跨不同的域来进行操作,所以引入session:
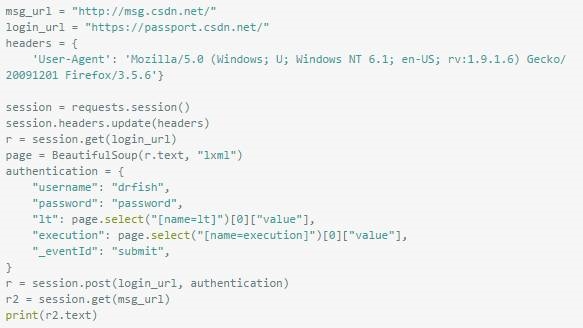
好了,现在能够得到我的消息信息了,说明已经成功解决登陆问题,那么自动化水军评论应该就近在眼前了。
自动评论
这次学乖了,随便找了篇文章直接查看评论框form:
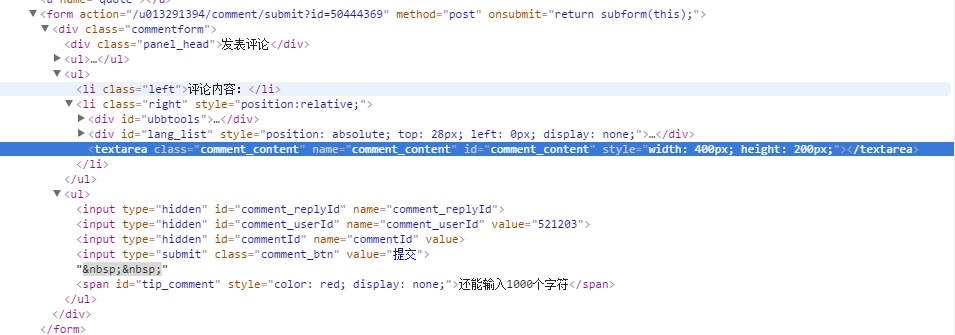
在上面登陆代码的基础上进行评论的提交:
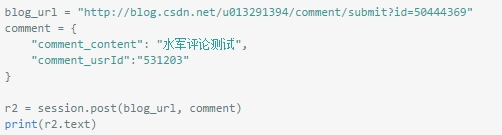
结果返回了 {"result":0,"content":"评论内容没有填写!","callback":null,"data":null} 这样的结果。有点意思,应该是在js中对参数进行了处理。那就把js拉出来看看,网页里搜了一下js文件,有个 ,就是它了。在上面的form中可以看到提交时调用了subform方法,查看方法如下:

可以清楚的看到最后POST提交的数据 data 改变了参数的名字,还有几个其他的参数通过看js文件可以看到不是空的就是定死的,就不用管他了。同时发现上的 "comment_usrId" 也是给死的?那就只要comment一个变量就搞定了。
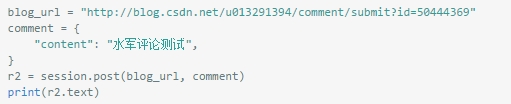
看一下效果:

自动化
当然上面最终的参数传递也可以自己手动评论并用抓包软件抓取,不过通过查看 commetn.js 文件也给我的自动化评论提供了方向,其中有一个 load_comment_form() 方法,是用来加载comment-form的,它给出了action的定义:
action="/' + username + '/comment/submit?id=' + fileName + '"
写的很明白了,我只要抓取到页面的作者名和文章的编号就可以尽情的水评论了,随便选个抓取文章的入口,如最新博客入口 ,用BeautifulSoup抓取url并解析取到其中的username和filename来构成action并提价评论。
运行脚本试一下效果:

打开评论管理看一下:
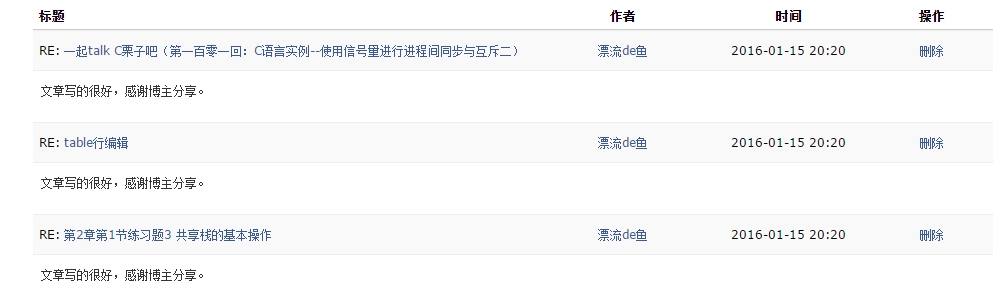
自动化评论成功。
写在最后
写这篇文章只是为了证明一下自己的想法,不是用来也不希望有人用来恶意刷评论。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。
