如何用Python制作微信好友个性签名词云图
前言
上次查看了微信好友的位置信息,想了想,还是不过瘾,于是就琢磨起了把微信好友的个性签名拿到,然后分词,接着分析词频,最后弄出词云图来。
1.环境说明
Win10 系统下 Python3,编译器是 Pycharm,需要安装 itchat、matplotlib、pandas、jieba、wordcloud、numpy、pillow 这几个包
介绍 Pycharm 安装第三方包的方法。
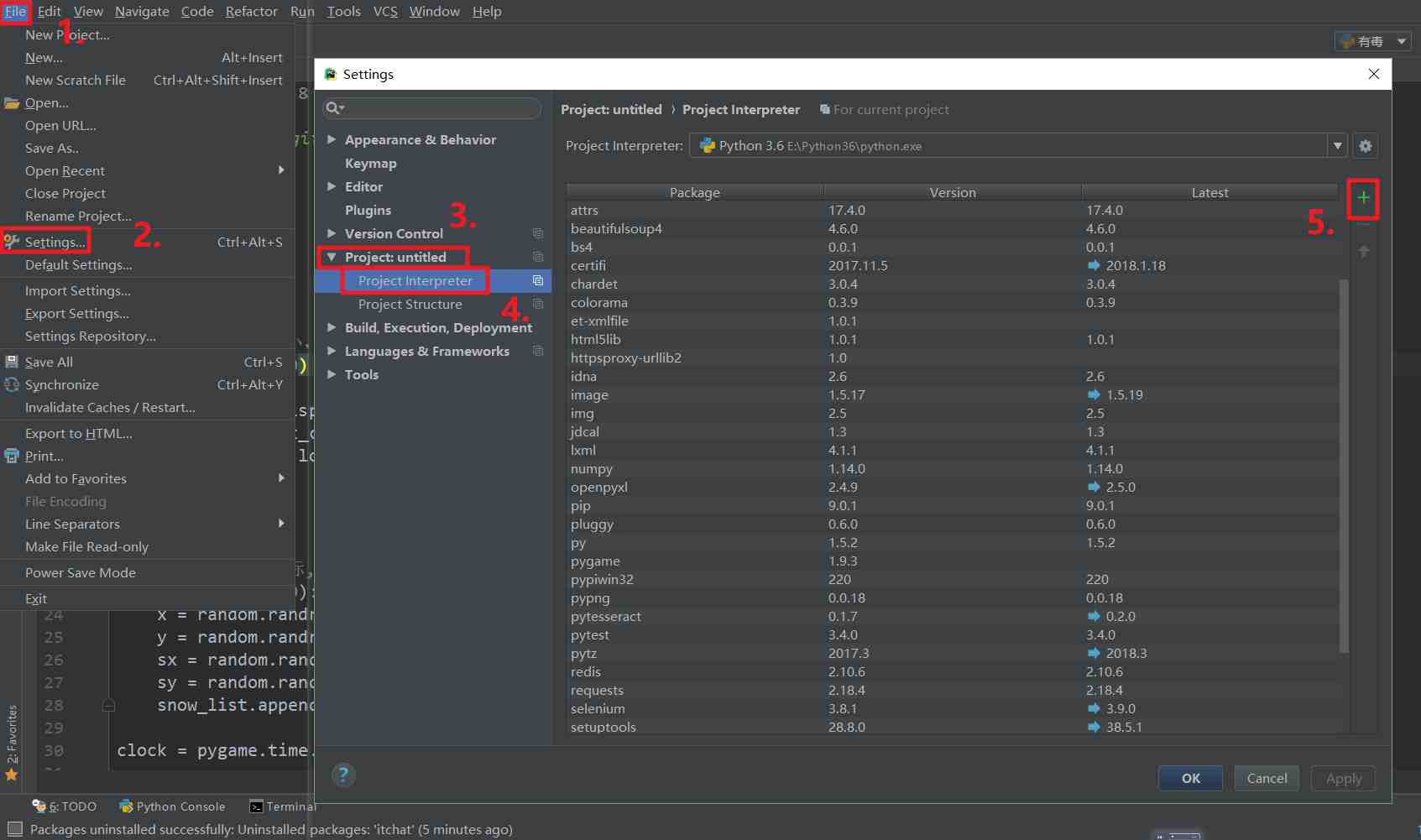
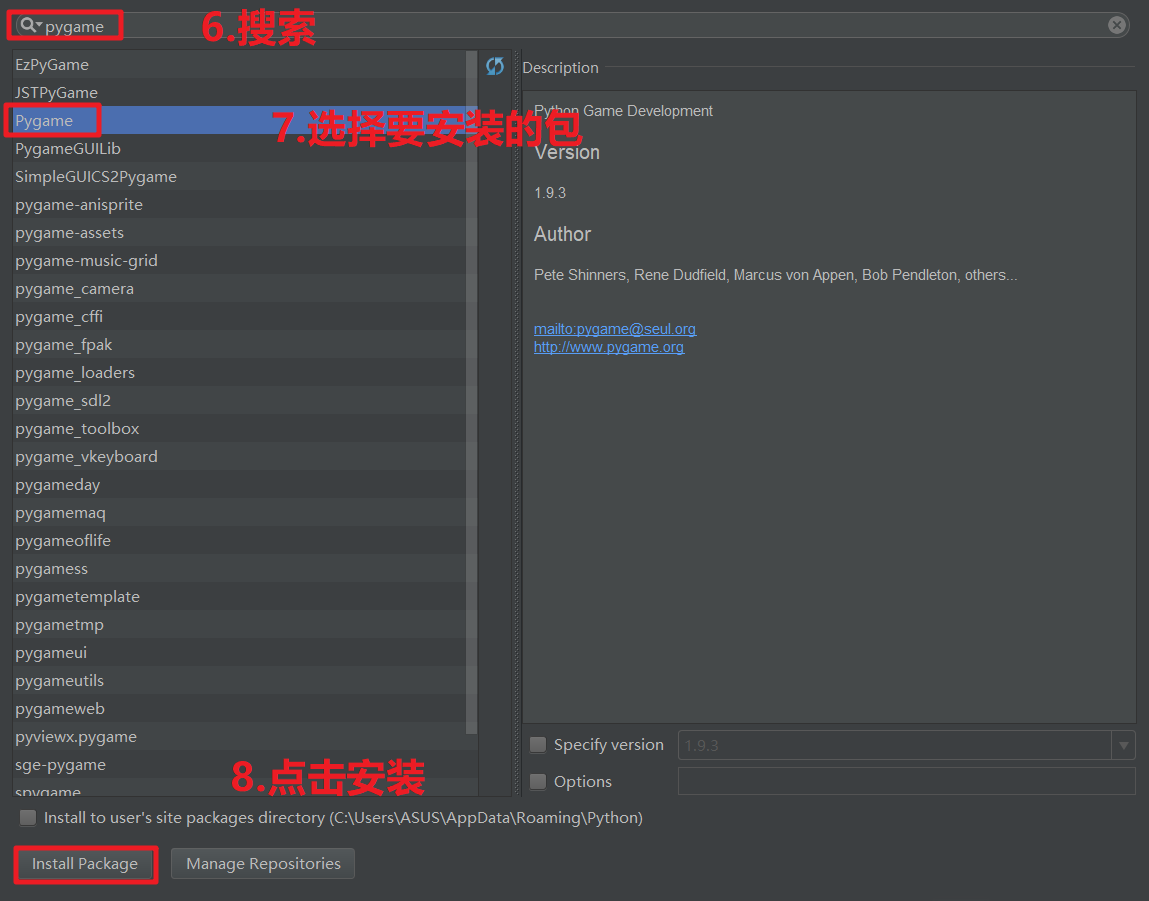
由于某些包不能直接用 Pycharm 安装,所以这里说一下安装的方法。
安装wordcloud
worcloud需要numpy> = 1.5.1,pillow和matplotlib,所以要先安装numpy,pillow和matplotlib。
在这个链接找到合适的whl文件
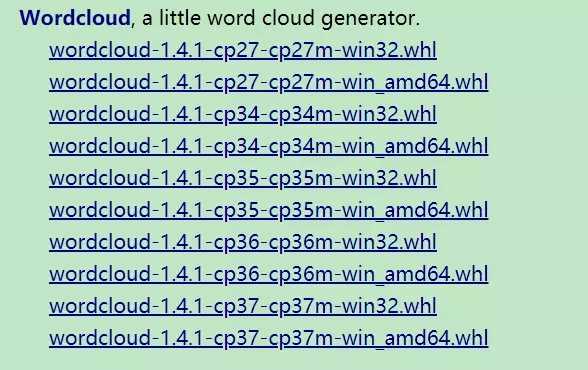
如果是电脑是64位,python是3.6就下载下面这个。
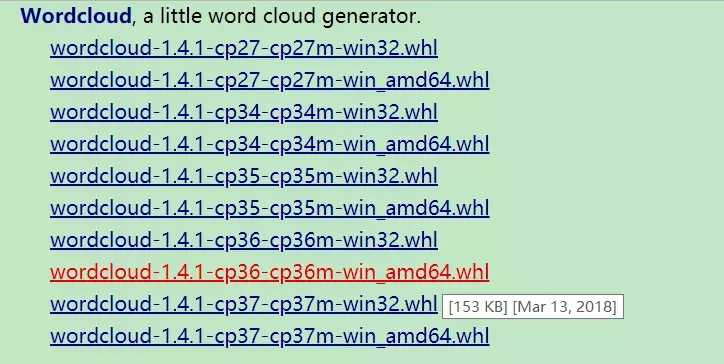
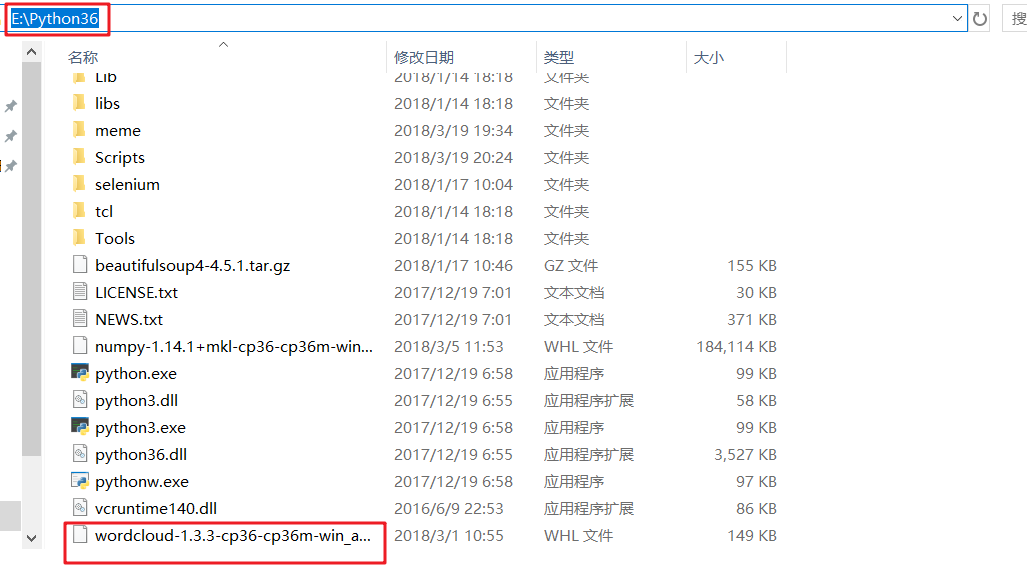
下载回来就放到Python的目录下,就比如我是把 Python 安装在E:\Python36这个目录,就把下载回来的 wordcloud-1.3.3-cp36-cp36m-win_amd64.whl 放在这。
然后按win键+R ,输入cmd,回车

然后cd 到 Python 目录那
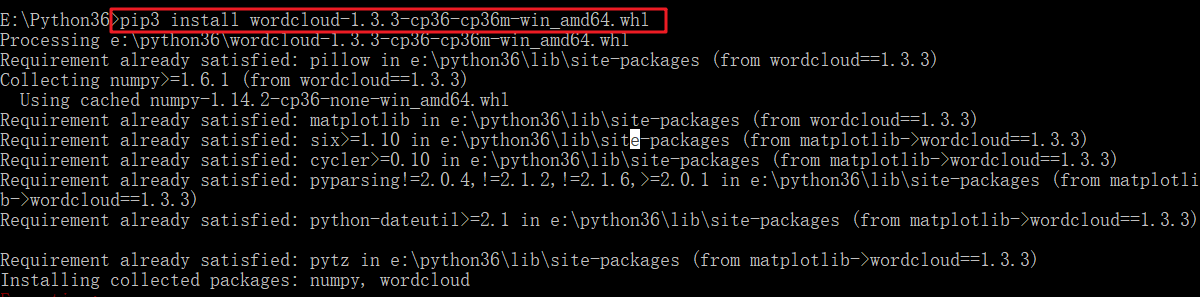
接下来就是安装了,pip install wordcloud-1.3.3-cp36-cp36m-win_amd64.whl
除了这个以外,某一个包需要翻墙才能安装,具体是哪个就不记得了,好像是 pandas。
2.相关代码
先把需要的东西导入,安装这些包可不简单
import itchat import matplotlib.pyplot as plt import re, jieba import pandas as pd from wordcloud import WordCloud, ImageColorGenerator import numpy as np import PIL.Image as Image
登录微信
itchat.auto_login(hotReload=True) friends = itchat.get_friends(update=True)
获取数据
data = pd.DataFrame() # 提出好友的昵称、性别、省份、城市、个性签名,生成一个数据框 columns=['NickName', 'Sex', 'Province', 'City', 'Signature'] for col in columns: val = [] for i in friends[1:]: # friends[0]是自己的信息,因此我们要从[1:]开始 val.append(i[col]) data[col] = pd.Series(val)
把个性签名中的 emoji 和别的东西过滤一下
siglist = []
for i in data['Signature']:
signature = i.strip().replace('emoji','').replace('span','').replace('class','')
rep = re.compile('1f\d+\w*|[<>/=]') # 具体含义另行查看
signature = rep.sub('', signature)
siglist.append(signature)
text = ''.join(siglist)
使用结巴分词进行分词,用 matplotlib 把图画出来
word_list = jieba.cut(text, cut_all=True)
word_space_split = ' '.join(word_list)
coloring = np.array(Image.open("E:/Python/wechat/toux.jpg")) #这个路径可以改,最好还是不要改
my_wordcloud = WordCloud(background_color="white", max_words=2000,
mask=coloring, max_font_size=100, random_state=42, scale=2,
font_path="C:/Windows/Fonts/simkai.ttf").generate(word_space_split)
image_colors = ImageColorGenerator(coloring)
plt.imshow(my_wordcloud.recolor(color_func=image_colors))
plt.imshow(my_wordcloud)
plt.axis("off")
plt.show()
3.运行
先说明一下,如果能看懂代码,知道该怎么把必要的文件弄好,那就不怎么需要看下面这个。
如果看得不太理解,运行前一定要在 E 盘建立一个文件夹。路径是 E:\Python\Wechat ,然后在文件夹中放入一张命名为 toux.jpg 的照片,具体图片看个人喜好。
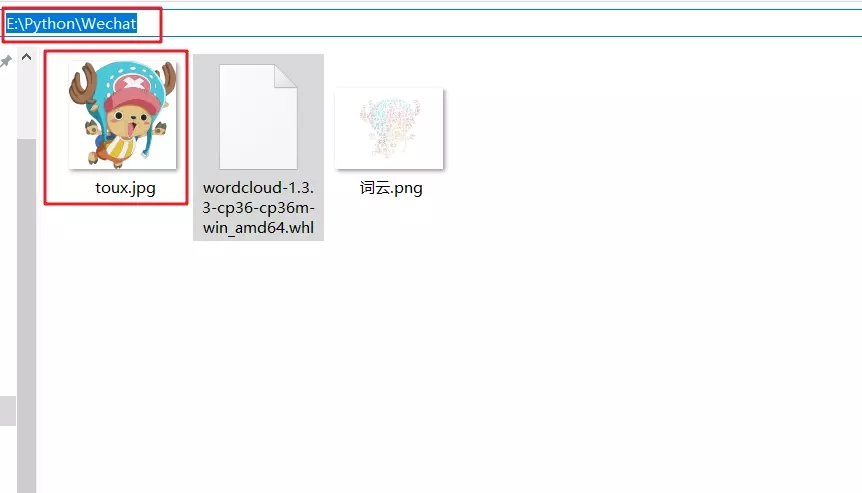
最好就是下图这样的照片

这样生成的词云就会很好看
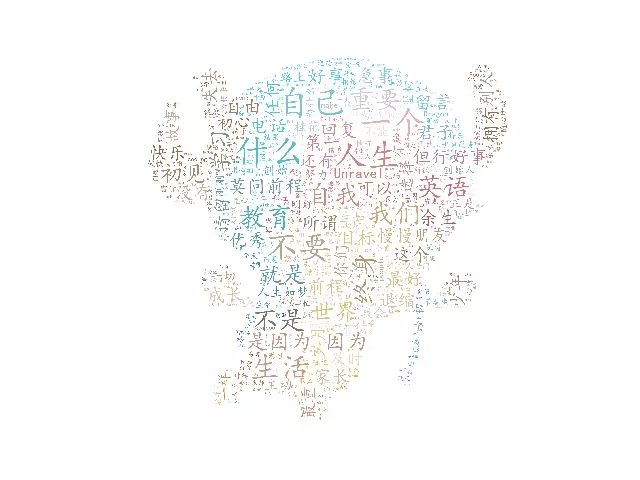
意思就是图片要有白色的背景,人物颜色较鲜艳,人物突出(图片分辨率要高)
把代码安装顺序复制到 Pycharm,然后鼠标右键,选择 Run,扫描弹出来的二维码,登录微信网页版,确认后等待一下,看到下图就说明代码运行得很完美,成功运行,没有报错。

然后稍微等一下就可以看到词云图了。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。