python3.6 如何将list存入txt后再读出list的方法
今天遇到一个需求,就是将一个list文件读取后,存入一个txt配置文件。存入时,发现list文件无法直接存入,必须转为str模式。
但在读取txt时,就无法恢复成list类型来读取了(准确地说,即使强行使用list读取,读出来的也是单个的字符)。
查了查资料,发现json.loads和json.dumps这对兄弟提供了一个很好的办法。下面看代码
#python 3.6
#!/usr/bin/env python
# -*- coding:utf-8 -*-
__author__ = 'BH8ANK'
'''取出字典中的value中的字典的value
'''
import json
x = {'RegionSet': [{'Region': 'ap-beijing',
'RegionName': '\xe5\x8d\x8e\xe5\x8c\x97\xe5\x9c\xb0\xe5\x8c\xba(\xe5\x8c\x97\xe4\xba\xac)',
'RegionState': 'AVAILABLE'},
{'Region': 'ap-chengdu',
'RegionName': '\xe8\xa5\xbf\xe5\x8d\x97\xe5\x9c\xb0\xe5\x8c\xba(\xe6\x88\x90\xe9\x83\xbd)',
'RegionState': 'AVAILABLE'},
{'Region': 'ap-chongqing',
'RegionName': '\xe8\xa5\xbf\xe5\x8d\x97\xe5\x9c\xb0\xe5\x8c\xba(\xe9\x87\x8d\xe5\xba\x86)',
'RegionState': 'AVAILABLE'},
{'Region': 'ap-guangzhou',
'RegionName': '\xe5\x8d\x8e\xe5\x8d\x97\xe5\x9c\xb0\xe5\x8c\xba(\xe5\xb9\xbf\xe5\xb7\x9e)',
'RegionState': 'AVAILABLE'},
{'Region': 'ap-guangzhou-open',
'RegionName': '\xe5\x8d\x8e\xe5\x8d\x97\xe5\x9c\xb0\xe5\x8c\xba(\xe5\xb9\xbf\xe5\xb7\x9eOpen)',
'RegionState': 'AVAILABLE'},
{'Region': 'ap-hongkong',
'RegionName': '\xe4\xb8\x9c\xe5\x8d\x97\xe4\xba\x9a\xe5\x9c\xb0\xe5\x8c\xba(\xe9\xa6\x99\xe6\xb8\xaf)',
'RegionState': 'AVAILABLE'},
{'Region': 'ap-mumbai',
'RegionName': '\xe4\xba\x9a\xe5\xa4\xaa\xe5\x9c\xb0\xe5\x8c\xba(\xe5\xad\x9f\xe4\xb9\xb0)',
'RegionState': 'AVAILABLE'},
{'Region': 'ap-seoul',
'RegionName': '\xe4\xb8\x9c\xe5\x8d\x97\xe4\xba\x9a\xe5\x9c\xb0\xe5\x8c\xba(\xe9\xa6\x96\xe5\xb0\x94)',
'RegionState': 'AVAILABLE'},
{'Region': 'ap-shanghai',
'RegionName': '\xe5\x8d\x8e\xe4\xb8\x9c\xe5\x9c\xb0\xe5\x8c\xba(\xe4\xb8\x8a\xe6\xb5\xb7)',
'RegionState': 'AVAILABLE'},
{'Region': 'ap-shanghai-fsi',
'RegionName': '\xe5\x8d\x8e\xe4\xb8\x9c\xe5\x9c\xb0\xe5\x8c\xba(\xe4\xb8\x8a\xe6\xb5\xb7\xe9\x87\x91\xe8\x9e\x8d)',
'RegionState': 'AVAILABLE'},
{'Region': 'ap-shenzhen-fsi',
'RegionName': '\xe5\x8d\x8e\xe5\x8d\x97\xe5\x9c\xb0\xe5\x8c\xba(\xe6\xb7\xb1\xe5\x9c\xb3\xe9\x87\x91\xe8\x9e\x8d)',
'RegionState': 'AVAILABLE'},
{'Region': 'ap-singapore',
'RegionName': '\xe4\xb8\x9c\xe5\x8d\x97\xe4\xba\x9a\xe5\x9c\xb0\xe5\x8c\xba(\xe6\x96\xb0\xe5\x8a\xa0\xe5\x9d\xa1)',
'RegionState': 'AVAILABLE'},
{'Region': 'eu-frankfurt',
'RegionName': '\xe6\xac\xa7\xe6\xb4\xb2\xe5\x9c\xb0\xe5\x8c\xba(\xe5\xbe\xb7\xe5\x9b\xbd)',
'RegionState': 'AVAILABLE'},
{'Region': 'na-ashburn',
'RegionName': '\xe7\xbe\x8e\xe5\x9b\xbd\xe4\xb8\x9c\xe9\x83\xa8(\xe5\xbc\x97\xe5\x90\x89\xe5\xb0\xbc\xe4\xba\x9a)',
'RegionState': 'AVAILABLE'},
{'Region': 'na-siliconvalley',
'RegionName': '\xe7\xbe\x8e\xe5\x9b\xbd\xe8\xa5\xbf\xe9\x83\xa8(\xe7\xa1\x85\xe8\xb0\xb7)',
'RegionState': 'AVAILABLE'},
{'Region': 'na-toronto',
'RegionName': '\xe5\x8c\x97\xe7\xbe\x8e\xe5\x9c\xb0\xe5\x8c\xba(\xe5\xa4\x9a\xe4\xbc\xa6\xe5\xa4\x9a)',
'RegionState': 'AVAILABLE'}],
'RequestId': 'CDFBE924-36FE-30AE-1B46-5AFCDF8A943D',
'TotalCount': 16}
y_list = x['RegionSet']
# print(y)#y是一个list,其中每个元素包含地域信息,每个元素又是单独的一个dict
# print(y_list)
i = 0
c_list = []
for i in range(len(y_list)):
b_dict = y_list[i]
c_list.append(b_dict['Region'])
# print(a['Region'])
# print(b_dict)
print('============clist=============')
print(c_list)
'''
json.dumps()和json.loads()是json格式处理函数(可以这么理解,json是字符串)
(1)json.dumps()函数是将一个Python数据类型列表进行json格式的编码(可以这么理解,json.dumps()函数是将字典转化为字符串)
(2)json.loads()函数是将json格式数据转换为字典(可以这么理解,json.loads()函数是将字符串转化为字典)
'''
c_list = json.dumps(c_list)
'''将c_list存入文件
'''
a = open(r"D:\python_test\data_source_list.txt", "w",encoding='UTF-8')
a.write(c_list)
a.close()
'''读取data_source_list文件
'''
b = open(r"D:\python_test\data_source_list.txt", "r",encoding='UTF-8')
out = b.read()
out = json.loads(out)
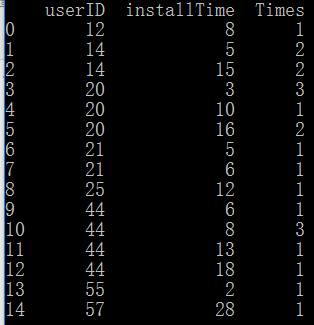
print(out)
print(isinstance(out,list))
输出如图:

有关json模块的说明:
json.dumps()和json.loads()是json格式处理函数(可以这么理解,json是字符串)
(1)json.dumps()函数是将一个Python数据类型列表进行json格式的编码(可以这么理解,json.dumps()函数是将字典转化为字符串)
(2)json.loads()函数是将json格式数据转换为字典(可以这么理解,json.loads()函数是将字符串转化为字典)
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。