代码实例讲解python3的编码问题
python3的编码问题。
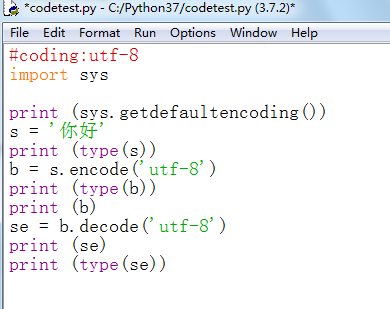
打开python开发工具IDLE,新建‘codetest.py'文件,并写代码如下:
import sys print (sys.getdefaultencoding())
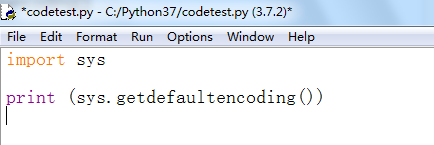
F5运行程序,打印出系统默认编码方式
将字符串从str格式编码程bytes格式,修改代码如下:
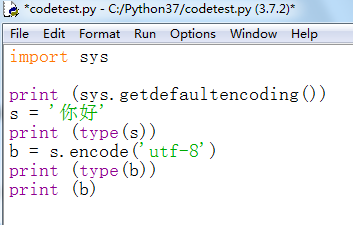
import sys
print (sys.getdefaultencoding())
s = '你好'
print (type(s))
b = s.encode('utf-8')
print (type(b))
print (b)
其中b = s.encode('utf-8') 等同于b = s.encode() ,因为系统默认编码方式就是utf-8
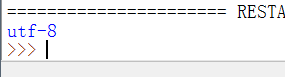
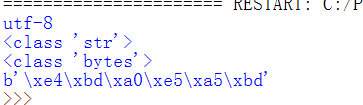
F5运行程序,打印出内容如下,中文必须用utf-8编码,因为ascii码表示不了所有汉字,这里暂时不介绍gbk编码,现在用得很少了,utf-8使用3个字节表示一个汉字,ascii使用一个字节表示一个英文字母或字符。
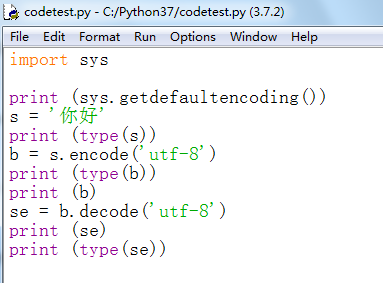
解码就是从bytes变回str的过程,修改代码如下:
import sys
print (sys.getdefaultencoding())
s = '你好'
print (type(s))
b = s.encode('utf-8')
print (type(b))
print (b)
se = b.decode('utf-8')
print (se)
print (type(se))
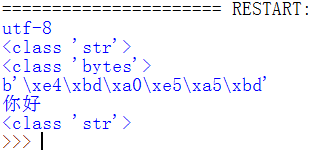
F5运行程序,打印内容如下图,bytes转回str
utf-8编码兼容ascii,当既有中文又有英文时使用encode('utf-8'),英文还是占一个字节,中国三个字节,另外当py文件注释有中文时,需要在头部添加
#coding:utf-8