pandas的连接函数concat()函数的具体使用方法
concat()函数的具体用法
pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False,
keys=None, levels=None, names=None, verify_integrity=False,
copy=True)
参数含义
- objs:Series,DataFrame或Panel对象的序列或映射。如果传递了dict,则排序的键将用作键参数,除非它被传递,在这种情况下,将选择值(见下文)。任何无对象将被静默删除,除非它们都是无,在这种情况下将引发一个ValueError。
- axis:{0,1,...},默认为0。沿着连接的轴。
- join:{'inner','outer'},默认为“outer”。如何处理其他轴上的索引。outer为联合和inner为交集。
- ignore_index:boolean,default False。如果为True,请不要使用并置轴上的索引值。结果轴将被标记为0,...,n-1。如果要连接其中并置轴没有有意义的索引信息的对象,这将非常有用。注意,其他轴上的索引值在连接中仍然受到尊重。
- join_axes:Index对象列表。用于其他n-1轴的特定索引,而不是执行内部/外部设置逻辑。
- keys:序列,默认值无。使用传递的键作为最外层构建层次索引。如果为多索引,应该使用元组。
- levels:序列列表,默认值无。用于构建MultiIndex的特定级别(唯一值)。否则,它们将从键推断。
- names:list,default无。结果层次索引中的级别的名称。
- verify_integrity:boolean,default False。检查新连接的轴是否包含重复项。这相对于实际的数据串联可能是非常昂贵的。
- copy:boolean,default True。如果为False,请勿不必要地复制数据。
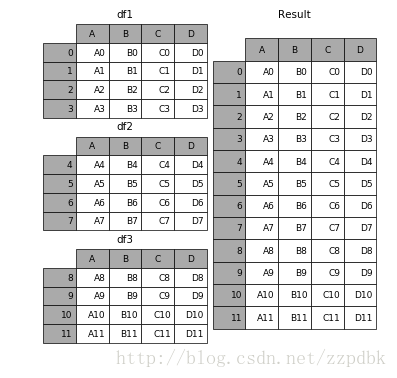
In [1]: df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
...: 'B': ['B0', 'B1', 'B2', 'B3'],
...: 'C': ['C0', 'C1', 'C2', 'C3'],
...: 'D': ['D0', 'D1', 'D2', 'D3']},
...: index=[0, 1, 2, 3])
...:
In [2]: df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'],
...: 'B': ['B4', 'B5', 'B6', 'B7'],
...: 'C': ['C4', 'C5', 'C6', 'C7'],
...: 'D': ['D4', 'D5', 'D6', 'D7']},
...: index=[4, 5, 6, 7])
...:
In [3]: df3 = pd.DataFrame({'A': ['A8', 'A9', 'A10', 'A11'],
...: 'B': ['B8', 'B9', 'B10', 'B11'],
...: 'C': ['C8', 'C9', 'C10', 'C11'],
...: 'D': ['D8', 'D9', 'D10', 'D11']},
...: index=[8, 9, 10, 11])
...:
In [4]: frames = [df1, df2, df3]
In [5]: result = pd.concat(frames)
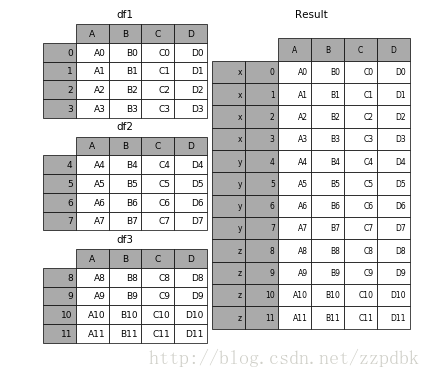
KEY参数
result = pd.concat(frames, keys=['x', 'y', 'z'])
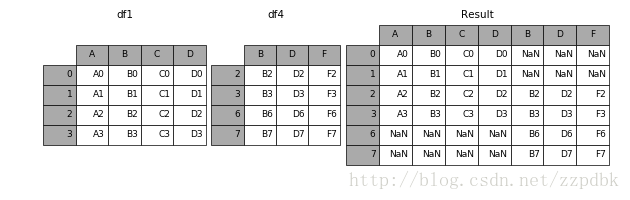
JOIN参数
默认join = 'outer',为取并集的关系
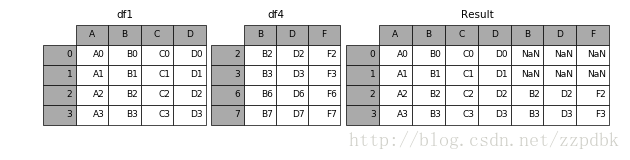
In [8]: df4 = pd.DataFrame({'B': ['B2', 'B3', 'B6', 'B7'],
...: 'D': ['D2', 'D3', 'D6', 'D7'],
...: 'F': ['F2', 'F3', 'F6', 'F7']},
...: index=[2, 3, 6, 7])
...:
In [9]: result = pd.concat([df1, df4], axis=1)
结果:
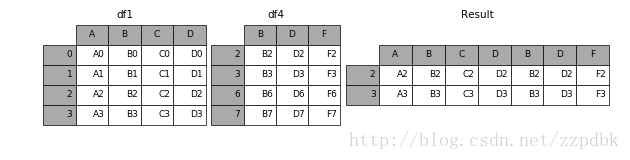
当设置join = 'inner',则说明为取交集
In [10]: result = pd.concat([df1, df4], axis=1, join='inner')
结果:
如果索引想从原始DataFrame重用确切索引:
In [11]: result = pd.concat([df1, df4], axis=1, join_axes=[df1.index]) #设置索引为df1的索引
pandas文档:http://pandas.pydata.org/pandas-docs/stable/
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。
