简单了解django索引的相关知识
前言
由于数据库每天都用来存储越来越多的信息,因此这些也是每个Django项目中的关键组件。 因此了解它们的工作方式非常重要。
当然,我无法解释所有可用于Django的不同数据库的全部细节。 不仅如此,因为我不知道这一切,但也因为这会造成一场谈话。 或者可能是整个会议。
关于数据库的理论背景我唯一想说的是,有一种叫做“关系代数”的东西。 用你可能想出的每 一条SELECT语句都可以表达出来。 数学证明。
数据库查找如何工作
相反,让我们从数据库查找的工作方式开始。 因为那是我们最多的时间。
假设我们有这个数据库的人名表及其相应的年龄,当他们开始编程时。
现在我们要选择每个19岁开始的人。
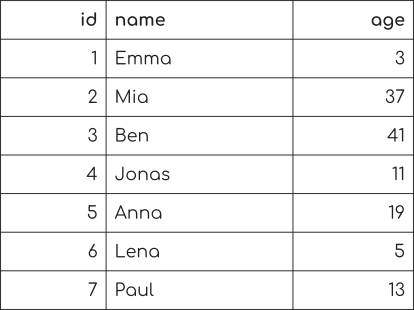
我们可以用SQL查询来表达:
SELECT * FROM people WHERE age = 19
现在,我们如何找到每个人匹配该查询?
表扫描查找
那么,这很容易。 我们只查看表中的每一行,检查条件是否适用,如果是,则返回该行。
这被称为“全表扫描”
到现在为止还挺好。 我们在这里有7排。 因此我们看7行。 这是少量的行,所以查询速度很快。
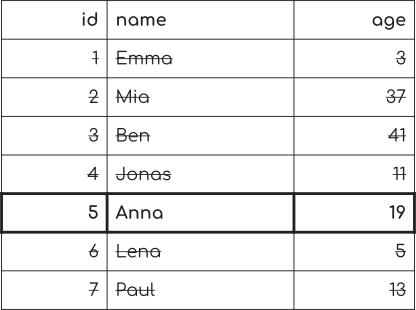
但是想象一下,你有10万,1亿,100亿甚至更多的行。 遍历每一行可能非常耗时。 这不是我们想要的或我们可以负担得起的东西。 我们希望能够提供有保证的时机来查找特定行。 与行数无关。
这是索引加入派对的地方。
什么是索引?
对于数量不断增加的数据,索引可以快速访问单个(或多个)项目,而不会减少很多速度。 这也被称为“随机访问”。 你会看到为什么这样叫。 但首先让我们看看现代数据库系统中最常见的索引类型。
B-Trees / B +树
目前最常见的索引是B-Tree索引。 或者更确切地说,B +树索引。
它们或者以其发明者之一Rudolf Bayer命名,或者因为他们自我平衡。 这不是很清楚,但也并不重要。 自我平衡意味着树木有一定的时间保证:对于B树最有意思的是,索引的大小并不重要,对于任何相同大小的索引,时间将是相同的。 你也会看到这一点。
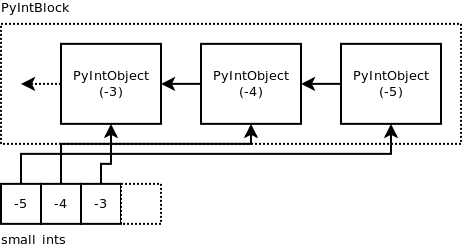
就像所有的树(无论是在计算机科学还是在自然界中),你都以一个根开始。 计算机科学与自然的区别在于,在计算机科学中,我们把树的根部放在顶部。
随你。 这是3级B +树的根音。
等级3意味着,这个节点可以有3个键。 这就是该节点顶部的3个盒子的用途。 下面的4个盒子保存指向另一个节点的指针或数据库表中的一行。
现在,假设您在此节点中具有密钥11和37,并且您没有第三个密钥。
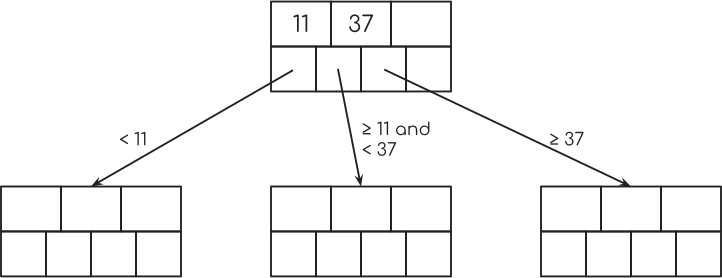
然后最左边的指针指向一个节点的键小于11.第二个指针指向一个节点,其键大于或等于11,小于37.第三个指针指向一个键大于或等于37的节点。
从我在开始时显示的表格的年龄栏索引中,可以看起来像这样。
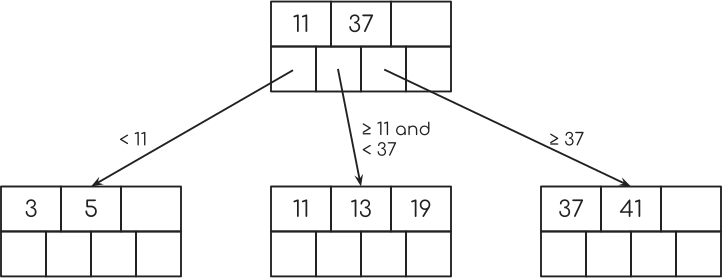
现在的魔法就是第二行节点中的指针。 它们中的每一个指向表中具有特定键的单个行,在我们的示例中,这是年龄。
但不只是这个。
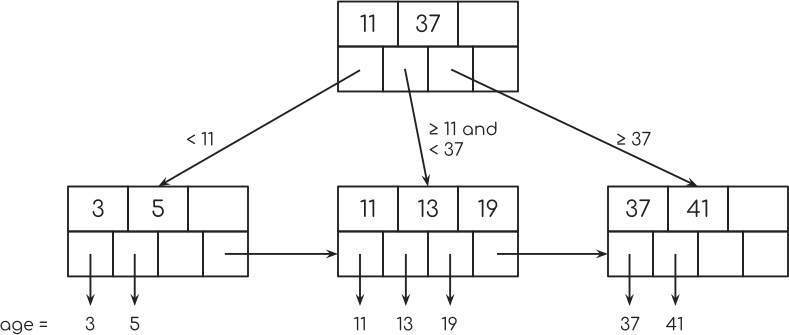
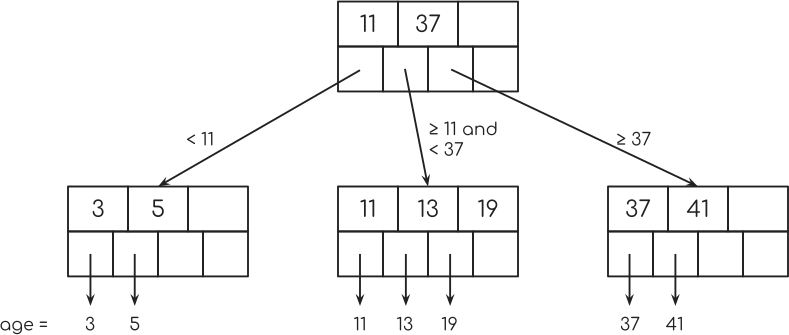
您会看到每个底层节点中的最后一个指针如何指向下一个节点? 这用于“索引扫描”。 我会在稍后回来。
我们来更详细地看看第二排节点。
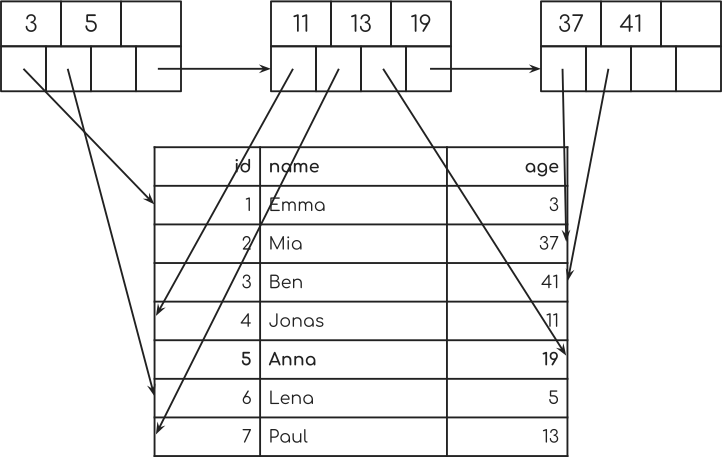
您现在可以看到,来自其中一个树节点的每个指针如何指向表中的单个行。
您还可以看到来自树节点的这些指针如何随机地指向表中的某些行。 这就是为什么这被称为“随机访问”。 数据库随机在数据库表中跳转。
随机访问查找
让我们用我们之前的SQL查询刷新我们的记忆。
SELECT * FROM people WHERE age = 19
现在索引如何帮助更快找到相应的行?
那么,让我们看看树:
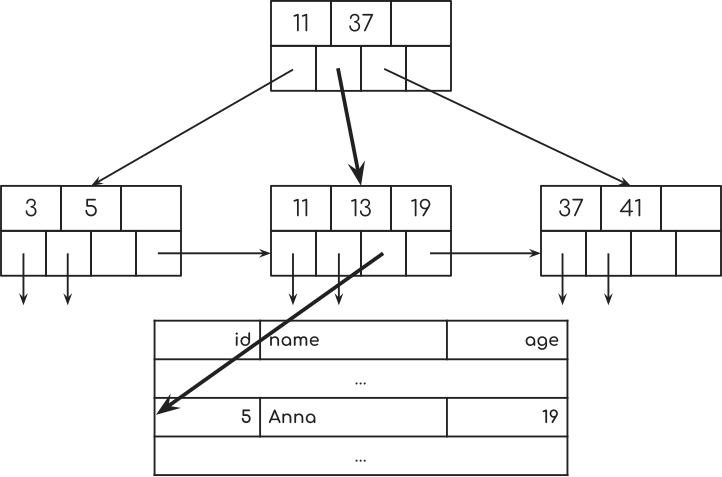
它需要1步从第一个节点到第二个节点。 并且从第二个节点到数据库表中的行一秒钟。
请记住,我们必须查看所有7行以查看它们是否与数据库查询匹配。
而且由于19个指数中没有更多的关键,我们就完成了。
索引扫描
现在,回到“索引扫描”,假设你想要计算从5岁到13岁时开始编码的人数。
SELECT COUNT(*) FROM people WHERE age BETWEEN 5 AND 19; SELECT COUNT(*) FROM people WHERE age >= 5 AND age <= 19;
数据库将查找密钥5,然后使用指向下一个节点的指针查找更多密钥。
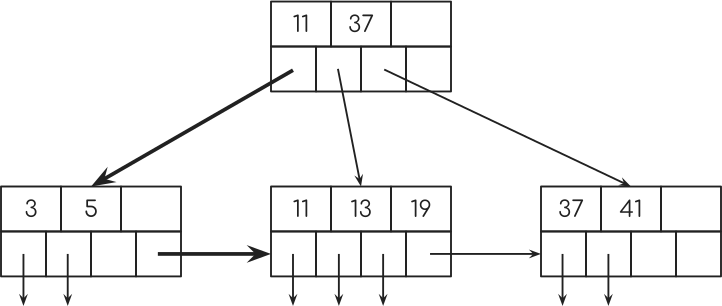
而且因为数据库所需的所有查询信息都在索引中,所以数据库根本不会查看表。
索引非常棒
让我们让他们在Django。
实际上,我们已经做到了。
有
- db_index = True ,您可以在模型字段上设置
- index_together =(('name', 'age'),)你可以在模型的Meta类中设置
- ForeignKey() / OneToOneField()使用索引快速查找相关表中的数据
- primary_key = True ,Django自动使用AutoField表示每个模型上的id列。
这已经很棒了。 但是这个功能集有点限制。 那里不仅有B +树索引。 还有一吨多
2016
我们来看看2016年。
马克·坦林和我有索引的想法。 实际上,Marc在他的contrib.postgres工作中已经有了一些想法。 我们有关于API的想法。 我们希望在Django中拥有的东西。 像,让我们让Django支持所有的索引 。
但是我们没有时间去实现我们的想法!
但我们很幸运。 事实上,Django项目很幸运。
Google Summer of Code 2016
Django再次被接受为Google Summer of Code的组织。 谢谢Google!
对于那些不知道这是什么的人:谷歌支付学生3个月的时间在开源项目上工作,同时由项目贡献者进行指导。
大多数情况下, Tim Graham ,还有Marc和我辅导学生Akshesh Doshi在Django中处理更通用的索引支持。 从写下API等提议,直到最终合并到Django中。
GSoC 2016的主要成果是django.db.models.indexes.Index(fields,name) ( docs )
它定义了所有索引的基类。 您可以通过模型的Meta类中的索引选项使用它们。
例如像这样:
from django.db import models
class Person(models.Model):
name = models.CharField(max_length=200)
class Meta:
indexes = [
models.Index(
fields=['name'],
name='name_idx',
),
]
这将在数据库表的名称列上创建一个B +树索引。
当然,这并不是什么新鲜事。 这就是在名称字段中使用db_index = True时可以执行的操作。
您当然也可以在多列上定义索引:
from django.db import models
class Person(models.Model):
name = models.CharField(max_length=200)
age = models.PositiveSmallIntegerField()
class Meta:
indexes = [
models.Index(
fields=['name', 'age'],
name='name_age_idx',
),
]
当然,这也不是什么新东西。 你可以用index_together来完成。
但你现在也可以这样做:
from django.contrib.postgres.fields import JSONField
from django.contrib.postgres.indexes import GinIndex
from django.db import models
class Doc(models.Model):
data = JSONField()
class Meta:
indexes = [
GinIndex(
fields=['data'],
name='data_gin',
),
]
定义一个GinIndex 。 这是PostgreSQL特有的。 但这是你以前无法做到的事情。 至少不可靠,没有太多的痛苦。
GinIndex可用于索引JSON blob中的键值。 因此,您可以筛选表中JSONB字段中的键映射到特定值的表中的行。 这就像“NoSQL 1-0-1”。
Django 1.11附带的另一种内置索引类型是BrinIndex ,简单地说,它可以允许更快地计算聚合。 比如,找出每篇文章最后一次购买的时间。
而且由于索引是数据库模式的一部分,显然通过迁移来追踪索引。 因此,当您运行python manage.py migrate时会创建索引:
BEGIN;
--
-- Create model Doc
--
CREATE TABLE "someapp_doc" (
"id" serial NOT NULL PRIMARY KEY,
"data" jsonb NOT NULL);
--
-- Create index data_gin on field(s) data of model doc
--
CREATE INDEX "data_gin" ON "someapp_doc" USING gin ("data");
COMMIT;
特色创意
大。
这就是昨天发布的Django 1.11。
但是Django 2.0有什么用?
什么在地平线上?
我们最终想要什么?
功能索引
它们在各种情况下都很有用,在这种情况下,您不希望对原始值进行索引,但可以对其进行变化,例如字符串的小写。 我已经在为此工作。 我还没到。 我很想从理解表达式API的人那里获得帮助。
from django.db import models
class Author(models.Model):
name = models.CharField(max_length=200)
class Meta:
indexes = [
FuncIndex(
expression=Lower('name'),
name='name_lower_idx',
),
]
db_index = <IndexClass>
如前所述,对单个列使用索引可能非常麻烦。 因此,让我们支持Index类作为db_index的一个属性。
from django.db import models class Author(models.Model): name = models.CharField( max_length=200, db_index=HashIndex )
对某些领域有一个B +树是没有意义的。 如前所示, GinIndex对于JSONField来说非常完美。 为什么不在db_index = True时使用每个字段类的default_index_class ?
from django.contrib.postgres.fields import JSONField from django.contrib.postgres.indexes import GinIndex from django.db import models # Somewhere in Django's JSONField implementation: # JSONField.default_index_class = GinIndex class Document(models.Model): data = JSONField(db_index=True)
重构index_together和db_index
这个比面向用户更引人注目:
我可以想象, db_index和index_together在内部使用Model._meta.indexes可能是有意义的。 这是要调查的东西。
GiSTIndex
PostgreSQL中有一个GiSTIndex ,可用于地理空间查询,例如“给我所有与给定点最大距离为10的点”。 这不是在Django 1.11中。 我不知道为什么,但我猜是因为没有人添加它。
请注意,Django 2.0不再支持Python 2了!
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。