对python3中的RE(正则表达式)-详细总结
1.引入正则模块(Regular Expression)
要使用python3中的RE则必须引入 re模块
import re #引入正则表达式
2.主要使用的方法 match(), 从左到右进行匹配
#pattern 为要校验的规则 #str 为要进行校验的字符串 result = re.match(pattern, str) #如果result不为None,则group方法则对result进行数据提取
3. 正则表达式
1️⃣单字符匹配规则
字符 功能 . 匹配任意1个字符(除了\n) [] 匹配[]中列举的字符 \d 匹配数字,也就是0-9 \D 匹配非数字,也就是匹配不是数字的字符 \s 匹配空白符,也就是 空格\tab \S 匹配非空白符,\s取反 \w 陪陪单词字符, a-z, A-Z, 0-9, _ \W 匹配非单词字符, \w取反
2️⃣表示数量的规则
字符 功能
* 匹配前一个字符出现0次多次或者无限次,可有可无,可多可少
+ 匹配前一个字符出现1次多次或则无限次,直到出现一次
? 匹配前一个字符出现1次或者0次,要么有1次,要么没有
{m} 匹配前一个字符出现m次
{m,} 匹配前一个字符至少出现m次
{m,n} 匹配前一个字符出现m到n次
例一: 验证手机号码是否符合规则(不考虑边界问题)
#首先清楚手机号的规则
#1.都是数字 2.长度为11 3.第一位是1 4.第二位是35678中的一位
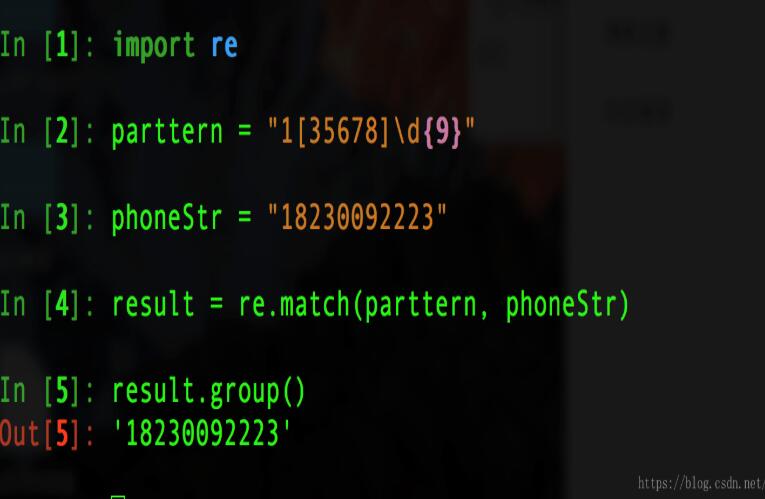
pattern = "1[35678]\d{9}"
phoneStr = "18230092223"
result = re.match(pattern, phoneStr)
result.group()
#执行结果如下图:
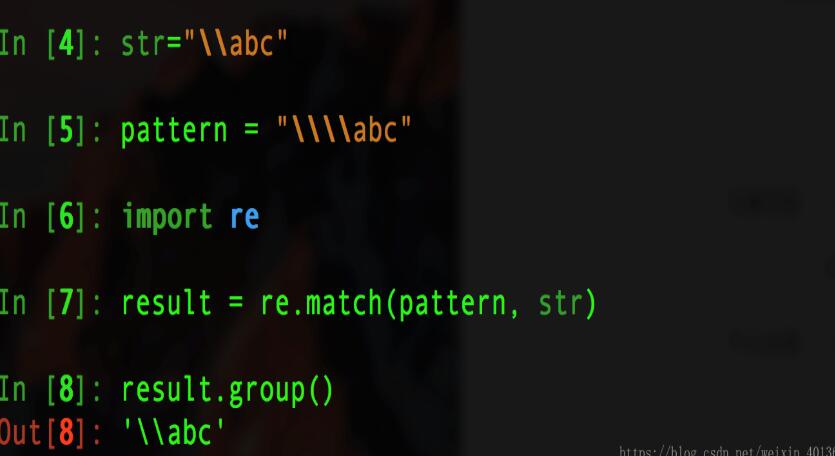
4. 原始字符串raw, 先来看如下实例:
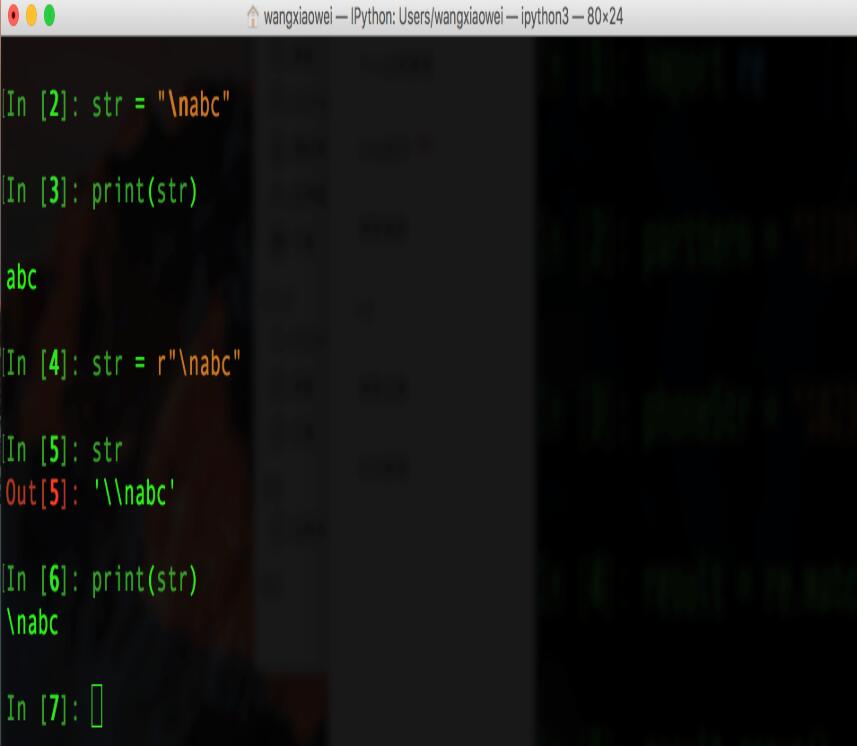
在上图中: 在给str赋值"\nabc"前加上"r"之后,python解释器会自动给str的值"\nabc"在加上一个"\".
使str在被打印的时候,能够保持原始字符串的值"\nabc"打印出来.
例二: (原始字符串在正则表达式中的应用)
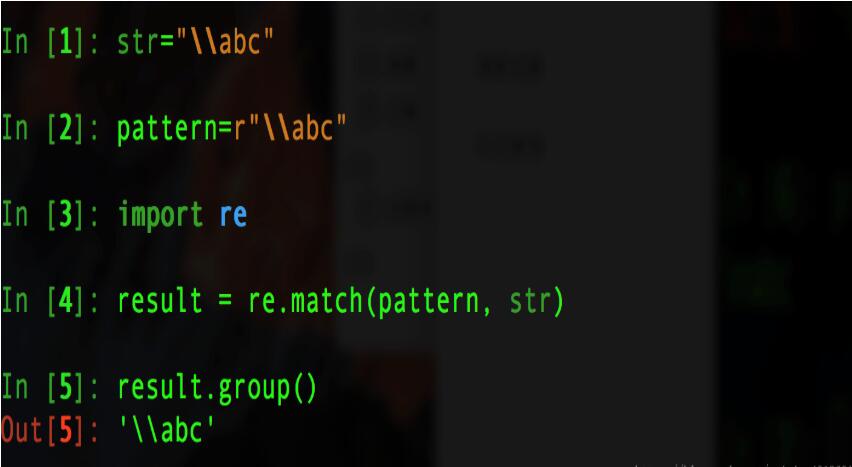
假若没有原始自付出r,则我们就要进行如下的操作: 给pattern加上双倍的"\"以避免转义字符中减少"\".会比较麻烦
当我们使用r原始字符串时,就不必考虑字符串的转移问题,更易集中解决字符匹配问题.
5. 表示边界
字符 功能 ^ 匹配字符串开头 $ 匹配字符串结尾 \b 匹配一个单词的边界 \B 匹配非单词边界
例三: 边界(制定规则来匹配str="ho ve r")
import re #定义规则匹配str="ho ve r" #1. 以字母开始 #2. 中间有空字符 #3. ve两边分别限定匹配单词边界 pattern = r"^\w+\s\bve\b\sr" str = "ho ve r" result = re.match(pattern, str) result.group()
6. 匹配分组
字符 功能 | 匹配左右任意一个表达式 (ab) 将括号中字符作为一个分组 \num 引用分组num匹配到的字符串 (?P<name>) 分组起别名 (?P=name) 引用别名为name分组匹配到的字符串
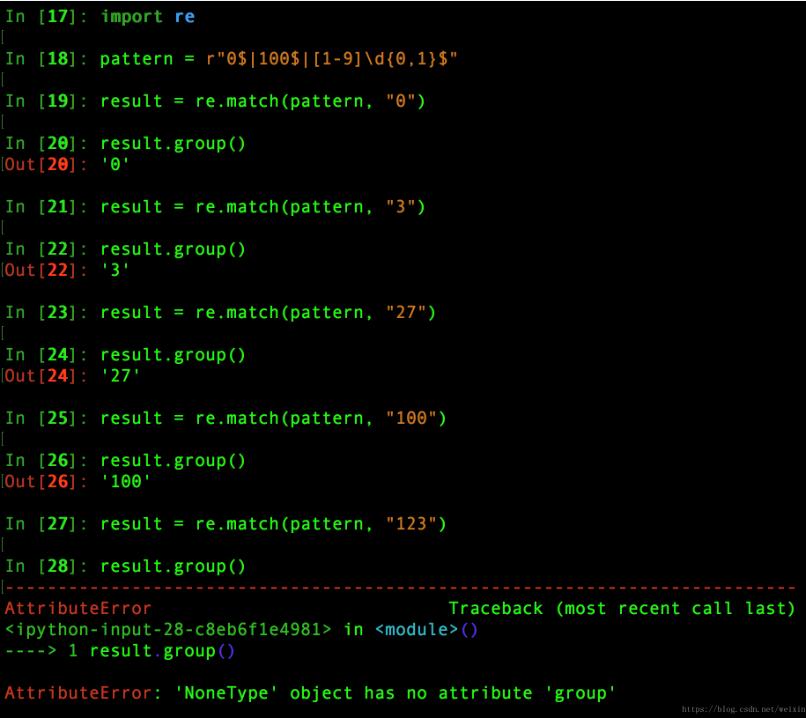
例四: 匹配出0-100之间的数字
import re
#匹配出0-100之间的数字
#首先:正则是从左往又开始匹配
#经过分析: 可以将0-100分为三部分
#1. 0 "0$"
#2. 100 "100$"
#3. 1-99 "[1-9]\d{0,1}$"
#所以整合如下
pattern = r"0$|100$|[1-9]\d{0,1}$"
#测试数据为0,3,27,100,123
result = re.match(pattern, "27")
result.group()
#将0考虑到1-99上,上述pattern还可以简写为:pattern=r"100$|[1-9]?\d{0,1}$"
#测试结果如下图:
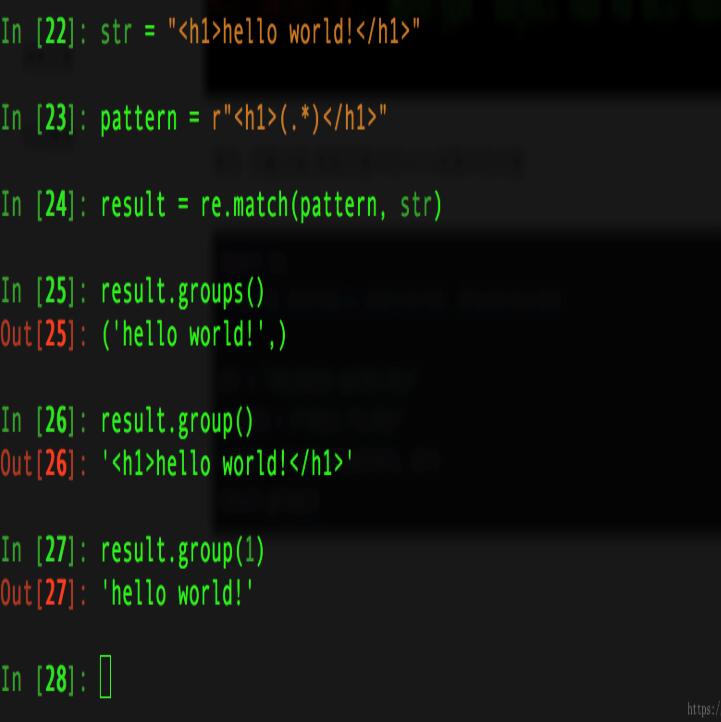
例五: 匹配分组,获取页面中的<h1>标签中的内容
import re #匹配分组,获取页面<h1>标签中的内容, 爬虫的时候会用到 str = "<h1>hello world!<h1>" pattern = r"<h1>(.*)</h1>" result = re.match(pattern, str) result.group() #执行如下图
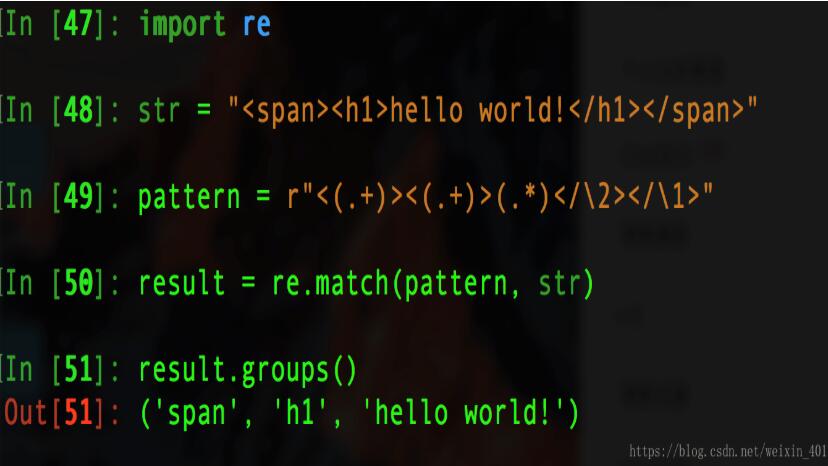
例六: 分组引用, 精确获取多个标签内的内容
import re #引用分组,精确获取多个标签内的内容 #"\1"是对第一个分组的引用,同理...... str = "<span><h1>hello world!</h1></span>" pattern = r"<(.+)><(.+)>.*</\2></\1>" result = re.match(pattern, str) result.groups() #执行如下图:
例七-2:分组起别名
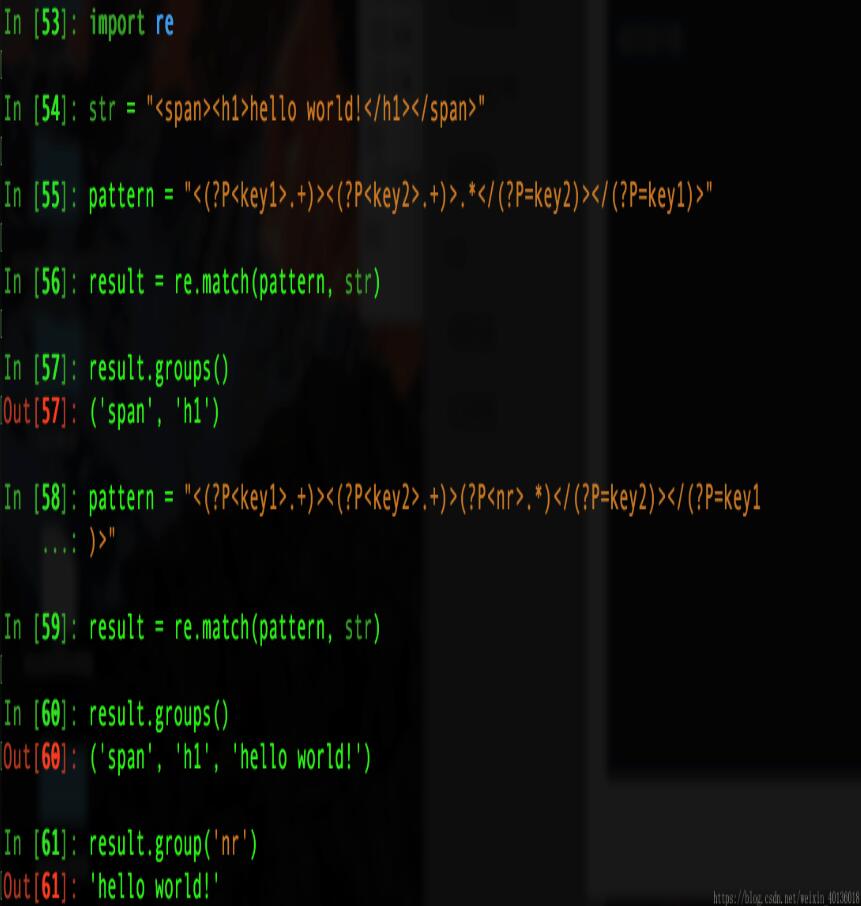
import re #分组起别名 str = "<span><h1>hello world!</h1></span>" pattern = "<(?P<key1>.+)><(?P<key2>.+)>(?P<nr>.*)</(?P=key2)></(?P=key1)>" result = re.match(pattern, str) result.groups() #执行如下图:
以上这篇对python3中的RE(正则表达式)-详细总结就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。