Python定时任务工具之APScheduler使用方式
APScheduler (advanceded python scheduler)是一款Python开发的定时任务工具。
文档地址 apscheduler.readthedocs.io/en/latest/u…
特点:
- 不依赖于Linux系统的crontab系统定时,独立运行
- 可以 动态添加 新的定时任务,如下单后30分钟内必须支付,否则取消订单,就可以借助此工具(每下一单就要添加此订单的定时任务)
- 对添加的定时任务可以做持久保存
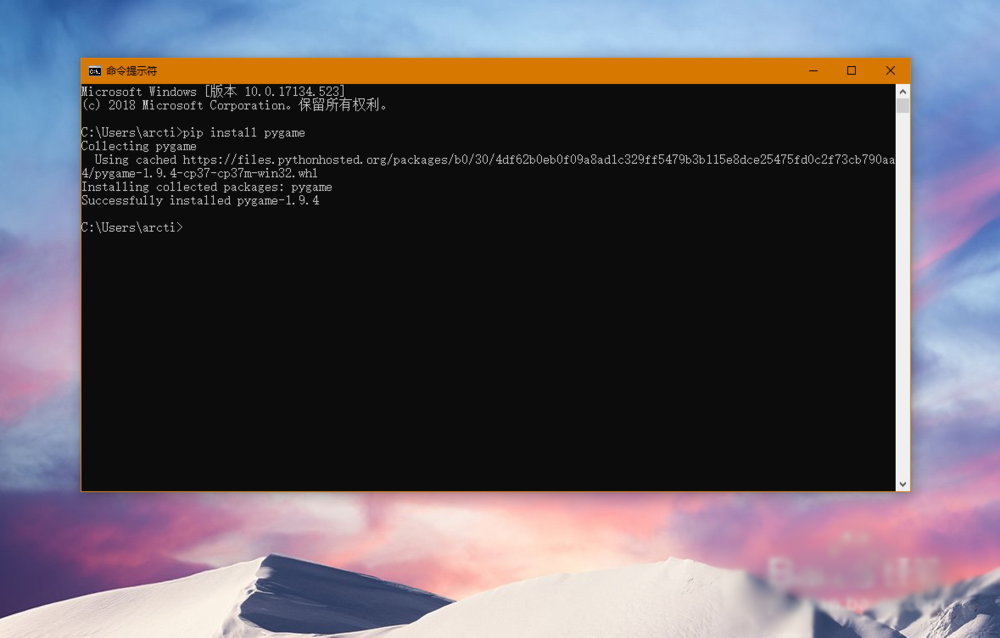
1 安装
pip install apscheduler
2 组成
- APScheduler 由以下四部分组成:
- triggers 触发器 指定定时任务执行的时机
- job stores 存储器 可以将定时持久存储
- executors 执行器 在定时任务该执行时,以进程或线程方式执行任务
- schedulers 调度器 常用的有BackgroundScheduler( 后台运行 )和BlockingScheduler( 阻塞式 )
3 使用方式
from apscheduler.schedulers.background import BlockingScheduler
#
创建定时任务的调度器对象
scheduler = BlockingScheduler()
# 创建执行器
executors = {
'default': ThreadPoolExecutor(20),
}
# 定义定时任务
def my_job(param1, param2): # 参数通过add_job()args传递传递过来
print(param1) # 100
print(param2) # python
# 向调度器中添加定时任务
scheduler.add_job(my_job, 'date', args=[100, 'python'], executors=executors)
# 启动定时任务调度器工作
scheduler.start()
4 调度器 Scheduler
负责管理定时任务
BlockingScheduler : 作为独立进程时使用
from apscheduler.schedulers.blocking import BlockingScheduler scheduler = BlockingScheduler() scheduler.start() # 此处程序会发生阻塞 BackgroundScheduler : 在框架程序(如Django、Flask)中使用. from apscheduler.schedulers.background import BackgroundScheduler scheduler = BackgroundScheduler() scheduler.start() # 此处程序不会发生阻塞
- AsyncIOScheduler : 当你的程序使用了asyncio的时候使用。
- GeventScheduler : 当你的程序使用了gevent的时候使用。
- TornadoScheduler : 当你的程序基于Tornado的时候使用。
- TwistedScheduler : 当你的程序使用了Twisted的时候使用
- QtScheduler : 如果你的应用是一个Qt应用的时候可以使用。
4 执行器 executors
在定时任务该执行时,以进程或线程方式执行任务
ThreadPoolExecutor from apscheduler.executors.pool import ThreadPoolExecutor ThreadPoolExecutor(max_workers)
使用方法
from apscheduler.executors.pool import ThreadPoolExecutor
executors = {
'default': ThreadPoolExecutor(20) # 最多20个线程同时执行
}
scheduler = BackgroundScheduler(executors=executors)
ProcessPoolExecutor
from apscheduler.executors.pool import ProcessPoolExecutor
ProcessPoolExecutor(max_workers)
使用方法
from apscheduler.executors.pool import ProcessPoolExecutor
executors = {
'default': ProcessPoolExecutor(5) # 最多5个进程同时执行
}
scheduler = BackgroundScheduler(executors=executors)
5 触发器 Trigger
指定定时任务执行的时机。
1) date 在特定的时间日期执行
from datetime import date # 在2019年11月6日00:00:00执行 sched.add_job(my_job, 'date', run_date=date(2019, 11, 6)) # 在2019年11月6日16:30:05 sched.add_job(my_job, 'date', run_date=datetime(2009, 11, 6, 16, 30, 5)) sched.add_job(my_job, 'date', run_date='2009-11-06 16:30:05') # 立即执行 sched.add_job(my_job, 'date') sched.start()
2) interval 经过指定的时间间隔执行
weeks (int) – number of weeks to wait days (int) – number of days to wait hours (int) – number of hours to wait minutes (int) – number of minutes to wait seconds (int) – number of seconds to wait start_date (datetime|str) – starting point for the interval calculation end_date (datetime|str) – latest possible date/time to trigger on timezone (datetime.tzinfo|str) – time zone to use for the date/time calculations from datetime import datetime # 每两小时执行一次 sched.add_job(job_function, 'interval', hours=2) # 在2012年10月10日09:30:00 到2014年6月15日11:00:00的时间内,每两小时执行一次 sched.add_job(job_function, 'interval', hours=2, start_date='2012-10-10 09:30:00', end_date='2014-06-15 11:00:00')
3) cron 按指定的周期执行
year (int|str) – 4-digit year month (int|str) – month (1-12) day (int|str) – day of the (1-31) week (int|str) – ISO week (1-53) day_of_week (int|str) – number or name of weekday (0-6 or mon,tue,wed,thu,fri,sat,sun) hour (int|str) – hour (0-23) minute (int|str) – minute (0-59) second (int|str) – second (0-59) start_date (datetime|str) – earliest possible date/time to trigger on (inclusive) end_date (datetime|str) – latest possible date/time to trigger on (inclusive) timezone (datetime.tzinfo|str) – time zone to use for the date/time calculations (defaults to scheduler timezone) # 在6、7、8、11、12月的第三个周五的00:00, 01:00, 02:00和03:00 执行 sched.add_job(job_function, 'cron', month='6-8,11-12', day='3rd fri', hour='0-3') # 在2014年5月30日前的周一到周五的5:30执行 sched.add_job(job_function, 'cron', day_of_week='mon-fri', hour=5, minute=30, end_date='2014-05-30')
6.任务存储
MemoryJobStore 默认内存存储 MongoDBJobStore 任务保存到MongoDB from apscheduler.jobstores.mongodb import MongoDB JobStoreMongoDBJobStore()复制代码 RedisJobStore 任务保存到redis from apscheduler.jobstores.redis import RedisJobStore RedisJobStore()
7 配置方法
方法1
from apscheduler.schedulers.background import BackgroundScheduler
from apscheduler.executors.pool import ThreadPoolExecutor
executors = {
'default': ThreadPoolExecutor(20),
}
conf = { # redis配置
"host":127.0.0.1,
"port":6379,
"db":15, # 连接15号数据库
"max_connections":10 # redis最大支持300个连接数
}
scheduler = BackgroundScheduler(executors=executors)
scheduler.add_jobstore(jobstore='redis', **conf) # 添加任务持久化存储方式,如果未安装redis可省略此步骤
方法2
from pytz import utc
from apscheduler.schedulers.background import BackgroundScheduler
from apscheduler.jobstores.sqlalchemy import SQLAlchemyJobStore
from apscheduler.executors.pool import ProcessPoolExecutor
executors = {
'default': {'type': 'threadpool', 'max_workers': 20},
'processpool': ProcessPoolExecutor(max_workers=5)
}
scheduler = BackgroundScheduler()
# .. 此处可以编写其他代码
# 使用configure方法进行配置
scheduler.configure(executors=executors)
8 启动
scheduler.start()
对于BlockingScheduler ,程序会阻塞在这,防止退出,作为独立进程时使用。(可以用来生成静态页面)
对于BackgroundScheduler,可以在应用程序中使用。不再以单独的进程使用。(如30分钟内取消订单)
9 扩展
任务管理
方式1
job = scheduler.add_job(myfunc, 'interval', minutes=2) # 添加任务 job.remove() # 删除任务 job.pause() # 暂定任务 job.resume() # 恢复任务
方式2
scheduler.add_job(myfunc, 'interval', minutes=2, id='my_job_id') # 添加任务
scheduler.remove_job('my_job_id') # 删除任务
scheduler.pause_job('my_job_id') # 暂定任务
scheduler.resume_job('my_job_id') # 恢复任务
调整任务调度周期
job.modify(max_instances=6, name='Alternate name')
scheduler.reschedule_job('my_job_id', trigger='cron', minute='*/5')复制代码
停止APScheduler运行
scheduler.shutdown()
10 综合使用
这里提供30分钟取消订单支付的思路,可以使用Flask或者Django程序都能实现,这里是在django应用中动态的添加一个定时任务,调度器需要使用BackgroundScheduler。下面先定义执行订单取消的任务。
from apscheduler.executors.pool import ThreadPoolExecutor from datetime import datetime, timedelta from apscheduler.schedulers.blocking import BackgroundScheduler from goods.models import SKU from orders.models import OrderGoods def cancel_order_job(order_id, sku_id, stock, sales): # 将订单商品和订单信息筛选出来 order_goods = OrderGoods.objects.filter( order_id=order_id, sku_id=sku_id) order_goods.delete() # 删除订单 try: sku = SKU.objects.get(id=sku_id) sku.stock += stock # 订单删掉后商品表里的库存恢复 sku.sales -= sales # 商品表里销量还原 sku.save() except Exception as e: print(e)
具体操作哪些表要根据自身表的设计来定,大致是上面的思路。然后在生成订单的视图中同时生成取消订单的任务。然后将取消订单cancel_order_job()需要的参数传递过去,注意要判定当前订单的状态为未支付状态。
from datetime import datetime, timedelta
class OrderCommitView(View):
def post(self, request):
# ... 此处省略生成订单相关逻辑
if status == OrderInfo.STATUS.UNPADED: # 待支付状态
executors = {
'default': ThreadPoolExecutor(10)
}
now = datetime.now()
delay = now + timedelta(minutes=30) # 从当前下订单延时30分钟后
scheduler = BackgroundScheduler(executors=executors)
# 添加定时任务
scheduler.add_job(cancel_order_job, 'date', run_date=delay,
args=[order_id, sku.id, sku.stock, sku.sales])
scheduler.start()
# ....省略其他业务及返回
注意: 如果需要周期性的执行一个定时任务,如果用到了django中模型类或者Flask的配置信息等相关信息,需要将框架的配置信息导入。
总结
以上所述是小编给大家介绍的Python定时任务工具之APScheduler详解,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对【听图阁-专注于Python设计】网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!