python Pandas如何对数据集随机抽样
摘要:有时候我们只需要数据集中的一部分,并不需要全部的数据。这个时候我们就要对数据集进行随机的抽样。pandas中自带有抽样的方法。
应用场景:
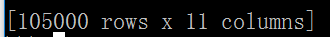
我有10W行数据,每一行都11列的属性。
现在,我们只需要随机抽取其中的2W行。
实现方法很简单:
利用Pandas库中的sample。
DataFrame.sample(n=None, frac=None, replace=False, weights=None, random_state=None, axis=None)
n是要抽取的行数。(例如n=20000时,抽取其中的2W行)
frac是抽取的比列。(有一些时候,我们并对具体抽取的行数不关系,我们想抽取其中的百分比,这个时候就可以选择使用frac,例如frac=0.8,就是抽取其中80%)
replace:是否为有放回抽样,取replace=True时为有放回抽样。
weights这个是每个样本的权重,具体可以看官方文档说明。
random_state这个在之前的文章已经介绍过了。
axis是选择抽取数据的行还是列。axis=0的时是抽取行,axis=1时是抽取列(也就是说axis=1时,在列中随机抽取n列,在axis=0时,在行中随机抽取n行)
具体用法:
假设DataFrame为df
import pandas as pd df.sample(n=20000)
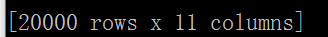
另外,介绍一种不是Pandas中的方法。如果想用Numpy这个库进行也可以。
import numpy as np np.random.sample(Your_index)
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。