opencv导入头文件时报错#include的解决方法
一、首先要确保你的电脑上opencv的环境和visual studio上的环境都配置好了,测试的时候通过了没有问题。
二、那么只要在你项目里面的属性设置里面配置一下包含目录就OK了,具体步骤如下
1、找到项目,鼠标右键选择属性
2、点击属性后会出现一个项目属性的管理窗口
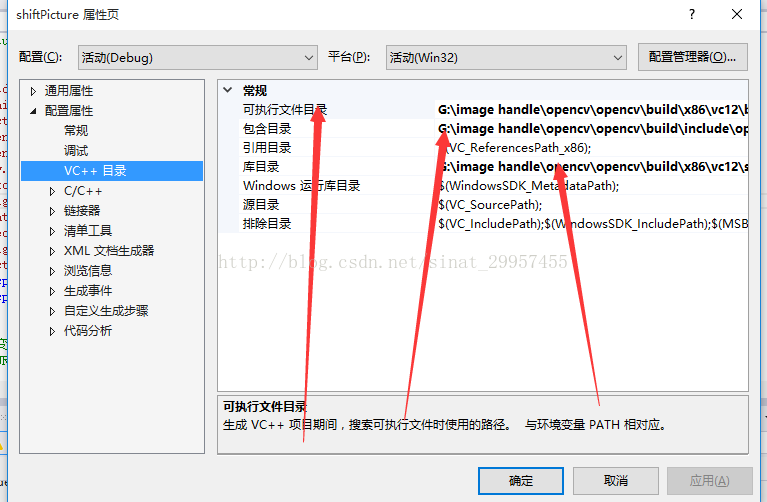
最好把三个目录都配置一下,其实只要配置包含目录后就不会报错了
可执行文件的目录为:你安装opencv的目录\opencv\build\x86\vc12\bin,至于x86和vc12的选择请自行百度查看,vc12和你的visual studio版本有关,一般是visual studio2013及以上的版本选择这个,x86一般都配置这个 目录就好了,这个和你电脑系统没什么关系,不要被误导了,刚开始时,我也纠结了很久
包含目录:opencv\build\include
opencv\build\include\opencv
opencv\build\include\opencv2
这三个目录都要配置,配置完成之后,点击应用然后再点击确定,报错就消失了。