基于python实现的百度新歌榜、热歌榜下载器(附代码)
前言
首先声明,本工具仅仅为学习之用,不涉及版权问题,因为百度音乐里面的歌曲本身是可以下载的,而且现在百度也提供了”百度音乐播放器”,可以通过这个工具进行批量下载。
我当时做这个工具的时候,百度还没有提供”百度音乐播放器”,而我又想批量下载,所以做了这样的一个下载工具。当然,主要还是为了学习。
工具采用Python2.7.3+PyQt开发。
功能:
1.集中展示百度新歌榜或热歌榜可下载的歌单。
2.支持单个、多个歌曲的下载。
3.可复制歌单中所有的链接内容,方便在迅雷等下载工具中创建下载组。
缺陷:
目前采用单线程,效率不高,UI界面容易假死。
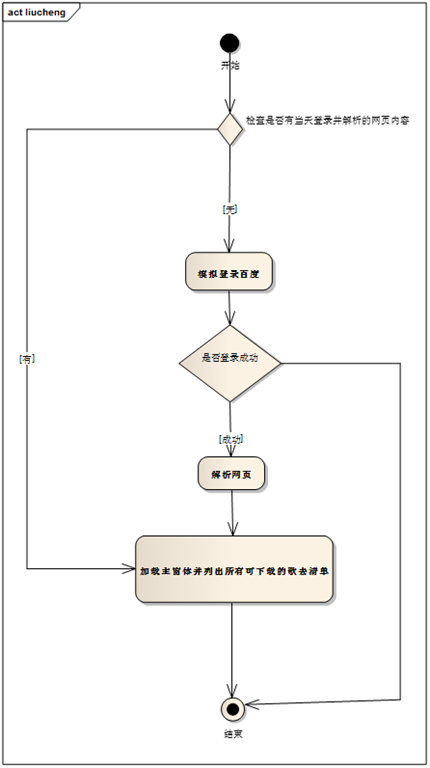
本工具运行流程:
1.模拟用户登录百度。
2.若登录成功,采集并解析页面内容,加载歌单列表。
3.用户点击下载按钮或者批量下载按钮后,下载歌曲。
使用方法:
1.在配置文件setting.py的最后,配置可登录百度的账号和密码,及百度热歌榜或新歌榜的URL.
username = "your baidu acount" #配置你的百度账号 password = "your baidu password" #配置你的百度密码 musiclistUrl = "http://music.baidu.com/top/dayhot" # http://music.baidu.com/top/new
2.直接运行mainWindow.py文件即可,如果网速不给力的话可能要等上3、4分钟。
运行后如图:

用到的知识:
1.首先用到了PyQt的GUI编程,窗体布局及QTableWidget、QProgressBar、QPushButton等控件及控件的重写
2.用到了网络编程的部分内容,利用urllib,urllib2,cookielib请求网页,模拟登录百度。
3.利用HTMLParser解析网页内容,匹配网页元素。
4.利用codecs进行文件的读写。
遇到的问题:
1.编码问题,由于在创建文件时将文件编码设置为UTF-8,当需要向文件写入的内容为中文等非ASCII码内容时,总是提示编码问题。其实,百度音乐的网页全部为UTF-8格式,因此从网页中获取的内容也是UTF-8格式,但是,要讲内容写入UTF-8的文本中,必须将网页内容进行decode(“utf8”)解码为unicode格式,才能正常写入。
检测内容编码,可以用chardet模块的chardet.detect(“内容”)的方法。
另外,HTMLParser解析网页内容过程中,有的下载页面会出现问题,根据提示信息发现还是编码问题,将feed()方法中的内容参数进行decode(“utf8”)后,结果正常。
decode将内容根据参数内容解码为unicode类型,具体要根据所采集的页面的编码。
github下载地址:点这里