django项目简单调取百度翻译接口的方法
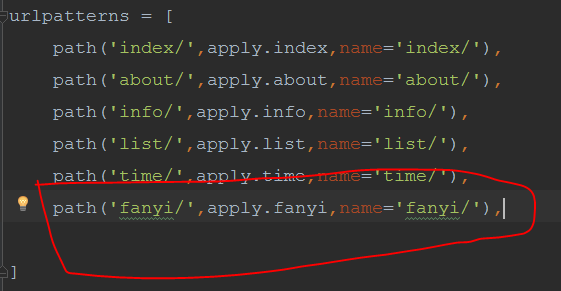
1,建路由;
2,写方法;
def fanyi(request):
import requests
import json
content = request.POST.get('content')
try:
if not content:
res={'status':1,'info':'未输入查询内容'}
return HttpResponse(json.dumps(res))
else:
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'
}
parmas = {'kw': content}
response = requests.post(url='https://fanyi.baidu.com/sug', params=parmas, headers=headers)
print(json.loads(response.text)['data'][0]['v'])
res={'status':0,'info':json.loads(response.text)['data'][0]['v']}
return HttpResponse(json.dumps(res))
except:
res={'status':2,'info':'未查询到结果,请输入正确的内容'}
return HttpResponse(json.dumps(res))
3,前端页面;form表单提交;
<form method="post" onsubmit="return false" id="form">
{% csrf_token %}
<div>
<button>英汉互译</button>
<br>
<textarea name="content" cols="50" rows="10" class="main"></textarea>
<input type="button" id="onsubmit" value="查询">
</div>
</form>
4,触发提交事件和返回结果的的jquery;
<script>
$('#onsubmit').click(function () {
console.log(123);
$.post('/apply/fanyi/',$('#form').serialize(),function (data) {
if (data['status']==0){
layer.alert(data['info'], {
skin: 'layui-layer-molv' //样式类名
,closeBtn: 0
})
}else{
layer.alert(data['info'], {
icon: 1,
skin: 'layer-ext-moon' //该皮肤由layer.seaning.com友情扩展。关于皮肤的扩展规则,去这里查阅
})
}
},'json')
})
</script>
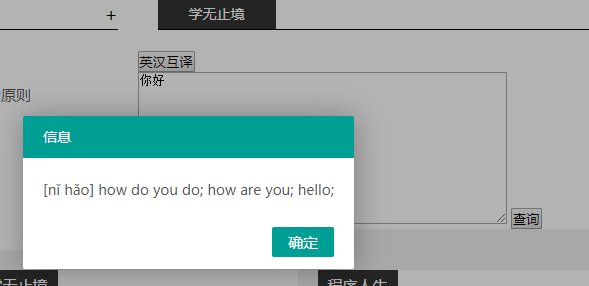
5,页面效果;

总结
以上所述是小编给大家介绍的django项目简单调取百度翻译接口的方法,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对【听图阁-专注于Python设计】网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!