python读取大文件越来越慢的原因与解决
背景:
今天同事写代码,用python读取一个四五百兆的文件,然后做一串逻辑上很直观的处理。结果处理了一天还没有出来结果。问题出在哪里呢?
解决:
1. 同事打印了在不同时间点的时间,在需要的地方插入如下代码:
print time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time()))
发现一个规律,执行速度到后面时间越来越长,也就是处理速度越来越慢。
2. 为什么会越来越慢呢?
1)可能原因1,GC 的问题,有篇文章里面写,python list append 的时候会越来越慢,解决方案是禁止GC:
使用 gc.disable()和gc.enable()
2)改完上面,仍然不行,然后看到一篇文章里面写,可能是因为 git 导致的,因为append 的时候 git 会不断同步,会出问题,于是删除 .git 文件夹,结果还是不行。
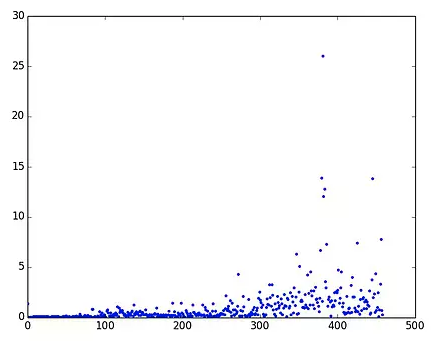
3)继续查询,发下一个及其有可能出问题的地方。dict 的 in dict.key(),判断 key 是否在 dict 里面,这个的效率是非常低的。看到一篇文章比较了效率:
① 使用 in dict.keys() 效率:
② 使用 has_key() 效率:
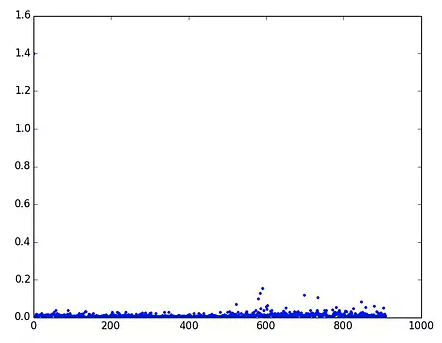
发现 has_key() 效率比较稳定。于是修改,问题解决。
后话:
最初的时候,的确是使用 has_key(), 结果后面上传代码的时候,公司代码检查过不了,提示不能使用这个函数,只能改成 in dict.key() 这种方式,为什么公司不让这么传呢?经过一番百度,发现原因所在:在 python3 中,直接将 has_key() 函数给删除了,所以禁止使用。那禁止了该怎么办呢?原来 python 中 in 很智能,能自动判断 key 是否在字典中存在。所以最正规的做法不是 has_key(), 更不是 in dict.keys(), 而是 in dict. 判断 key 在 map 中,千万别用 in dict.keys() !!!
附录:
in、 in dict.keys()、 has_key() 方法实战对比:
>>> a = {'name':"tom", 'age':10, 'Tel':110}
>>> a
{'age': 10, 'Tel': 110, 'name': 'tom'}
>>> print 'age' in a
True
>>> print 'age' in a.keys()
True
>>>
>>> print a.has_key("age")
True
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对【听图阁-专注于Python设计】的支持。
参考资料:
https://www.douban.com/group/topic/44472300/