Python如何使用k-means方法将列表中相似的句子归类
前言
由于今年暑假在学习一些自然语言处理的东西,发现网上对k-means的讲解不是很清楚,网上大多数代码只是将聚类结果以图片的形式呈现,而不是将聚类的结果表示出来,于是我将老师给的代码和网上的代码结合了一下,由于网上有许多关于k-means算法基础知识的讲解,因此我在这里就不多讲解了,想了解详细内容的,大家可以自行百度,在这里我只把我的代码给大家展示一下。
k-means方法的缺点是k值需要自己找,大家可以多换换k值,看看结果会有什么不同
代码
# coding: utf-8
import sys
import math
import re
import docx
from sklearn.cluster import AffinityPropagation
import nltk
from nltk.corpus import wordnet as wn
from nltk.collocations import *
import numpy as np
reload(sys)
sys.setdefaultencoding('utf8')
from sklearn.feature_extraction.text import CountVectorizer
#要聚类的数据
corpus = [
'This is the first document.',#0
'This is the second second document.',#1
'And the third one.',#2
'Is this the first document?',#3
'I like reading',#4
'do you like reading?',#5
'how funny you are! ',#6
'he is a good guy',#7
'she is a beautiful girl',#8
'who am i',#9
'i like writing',#10
'And the first one',#11
'do you play basketball',#12
]
#将文本中的词语转换为词频矩阵
vectorizer = CountVectorizer()
#计算个词语出现的次数
X = vectorizer.fit_transform(corpus)#获取词袋中所有文本关键词
word = vectorizer.get_feature_names()
#类调用
transformer = TfidfTransformer()
#将词频矩阵X统计成TF-IDF值
tfidf = transformer.fit_transform(X)
#查看数据结构 tfidf[i][j]表示i类文本中的tf-idf权重
weight = tfidf.toarray()
# print weight
# kmeans聚类
from sklearn.cluster import KMeans
# print data
kmeans = KMeans(n_clusters=5, random_state=0).fit(weight)#k值可以自己设置,不一定是五类
# print kmeans
centroid_list = kmeans.cluster_centers_
labels = kmeans.labels_
n_clusters_ = len(centroid_list)
# print "cluster centroids:",centroid_list
print labels
max_centroid = 0
max_cluster_id = 0
cluster_menmbers_list = []
for i in range(0, n_clusters_):
menmbers_list = []
for j in range(0, len(labels)):
if labels[j] == i:
menmbers_list.append(j)
cluster_menmbers_list.append(menmbers_list)
# print cluster_menmbers_list
#聚类结果
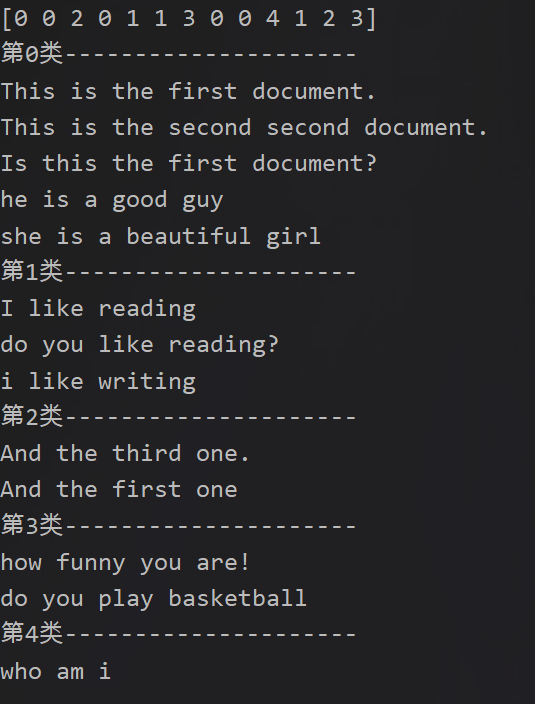
for i in range(0,len(cluster_menmbers_list)):
print '第' + str(i) + '类' + '---------------------'
for j in range(0,len(cluster_menmbers_list[i])):
a = cluster_menmbers_list[i][j]
print corpus[a]
运行结果:
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。