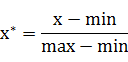python通过txt文件批量安装依赖包的实现步骤
如果要用某个开源框架,需要安装多个依赖包可以如下操作:
如依赖文件形式如下(可以不要版本号):
txt文件名为requirements.txt,内容为:
sklearn==0.0 subprocess32==3.2.7 tablestore==4.3.4 tensorboard==1.8.0 tensorflow==1.8.0
可以用如下命令安装:
$ pip install -r requirements.txt
接下来坐等,偶尔看一下,有些包下载可能会出现timeout,重新执行上面指令继续等待。、
从一个机器的python包导为requirements.txt指令为:
$ pip freeze >requirements.txt
以上这篇(标题)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。