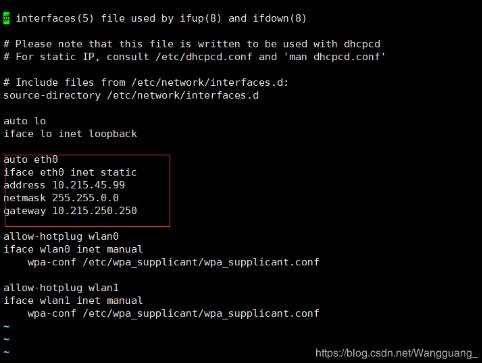
pytorch中的embedding词向量的使用方法
Embedding
词嵌入在 pytorch 中非常简单,只需要调用 torch.nn.Embedding(m, n) 就可以了,m 表示单词的总数目,n 表示词嵌入的维度,其实词嵌入就相当于是一个大矩阵,矩阵的每一行表示一个单词。
emdedding初始化
默认是随机初始化的
import torch from torch import nn from torch.autograd import Variable # 定义词嵌入 embeds = nn.Embedding(2, 5) # 2 个单词,维度 5 # 得到词嵌入矩阵,开始是随机初始化的 torch.manual_seed(1) embeds.weight # 输出结果: Parameter containing: -0.8923 -0.0583 -0.1955 -0.9656 0.4224 0.2673 -0.4212 -0.5107 -1.5727 -0.1232 [torch.FloatTensor of size 2x5]
如果从使用已经训练好的词向量,则采用
pretrained_weight = np.array(args.pretrained_weight) # 已有词向量的numpy self.embed.weight.data.copy_(torch.from_numpy(pretrained_weight))
embed的读取
读取一个向量。
注意参数只能是LongTensor型的
# 访问第 50 个词的词向量 embeds = nn.Embedding(100, 10) embeds(Variable(torch.LongTensor([50]))) # 输出: Variable containing: 0.6353 1.0526 1.2452 -1.8745 -0.1069 0.1979 0.4298 -0.3652 -0.7078 0.2642 [torch.FloatTensor of size 1x10]
读取多个向量。
输入为两个维度(batch的大小,每个batch的单词个数),输出则在两个维度上加上词向量的大小。
Input: LongTensor (N, W), N = mini-batch, W = number of indices to extract per mini-batch Output: (N, W, embedding_dim)
见代码
# an Embedding module containing 10 tensors of size 3 embedding = nn.Embedding(10, 3) # 每批取两组,每组四个单词 input = Variable(torch.LongTensor([[1,2,4,5],[4,3,2,9]])) a = embedding(input) # 输出2*4*3 a[0],a[1]
输出为:
(Variable containing: -1.2603 0.4337 0.4181 0.4458 -0.1987 0.4971 -0.5783 1.3640 0.7588 0.4956 -0.2379 -0.7678 [torch.FloatTensor of size 4x3], Variable containing: -0.5783 1.3640 0.7588 -0.5313 -0.3886 -0.6110 0.4458 -0.1987 0.4971 -1.3768 1.7323 0.4816 [torch.FloatTensor of size 4x3])
以上这篇pytorch中的embedding词向量的使用方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。