PyCharm搭建Spark开发环境的实现步骤
1.安装好JDK
下载并安装好jdk-12.0.1_windows-x64_bin.exe,配置环境变量:
- 新建系统变量JAVA_HOME,值为Java安装路径
- 新建系统变量CLASSPATH,值为 .;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar;(注意最前面的圆点)
- 配置系统变量PATH,添加 %JAVA_HOME%bin;%JAVA_HOME%jrebin
在CMD中输入:java或者java -version,不显示不是内部命令等,说明安装成功。
2.安装Hadoop,并配置环境变量
下载hadoop:https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz
- 解压hadoop-2.7.7.tar.gz特定路径,如:D:\adasoftware\hadoop
- 添加系统变量HADOOP_HOME:D:\adasoftware\hadoop
- 在系统变量PATH中添加:D:\adasoftware\hadoop\bin
- 安装组件winutils:将winutils中对应的hadoop版本中的bin替换自己hadoop安装目录下的bin
3.Spark环境变量配置
spark是基于hadoop之上的,运行过程中会调用相关hadoop库,如果没配置相关hadoop运行环境,会提示相关出错信息,虽然也不影响运行。
- 下载对应hadoop版本的spark:http://spark.apache.org/downloads.html
- 解压文件到:D:\adasoftware\spark-2.4.3-bin-hadoop2.7
- 添加PATH值:D:\adasoftware\spark-2.4.3-bin-hadoop2.7\bin;
- 新建系统变量SPARK_HOME:D:\adasoftware\spark-2.4.3-bin-hadoop2.7;
4.下载安装anaconda
anaconda集成了python解释器和大多数python库,安装anaconda 后不用再安装python和pandas numpy等这些组件了。下载地址。最后将python加到path环境变量中。
5.在CMD中运行pyspark,出现类似下图说明安装配置正常:
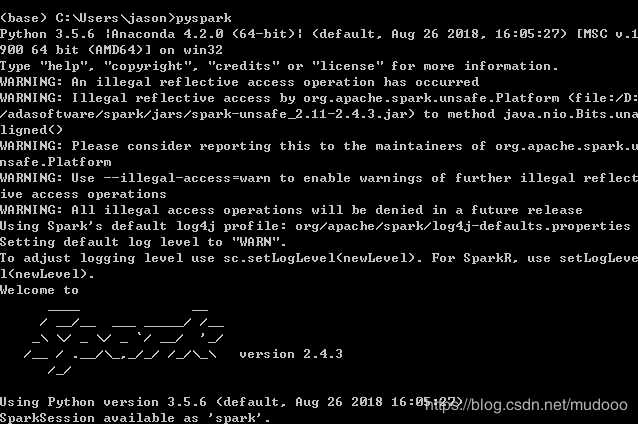
出现这种warning是因为JDK版本为12,太高了,但是不影响运行。没有影响。
6.在pycharm中配置spark
打开PyCharm,创建一个Project。然后选择“Run” ->“Edit Configurations”–>点击+创建新的python Configurations
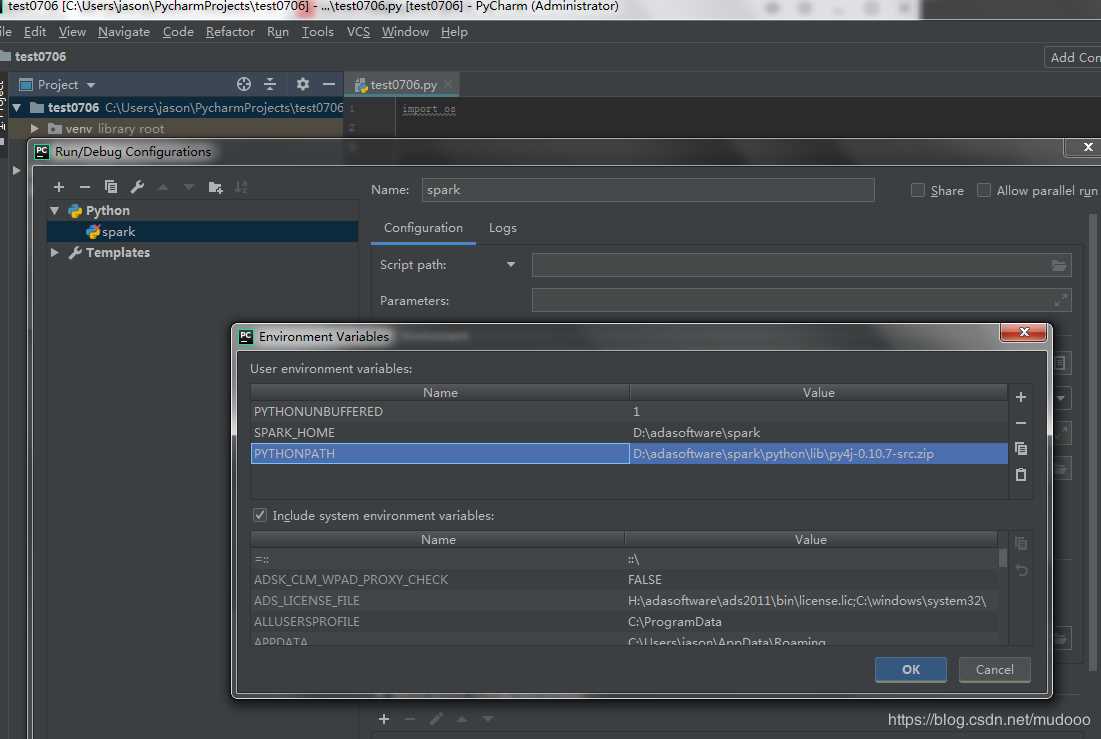
选择 “Environment variables” 增加SPARK_HOME目录与PYTHONPATH目录。
- SPARK_HOME:Spark安装目录
- PYTHONPATH:Spark安装目录下的Python目录
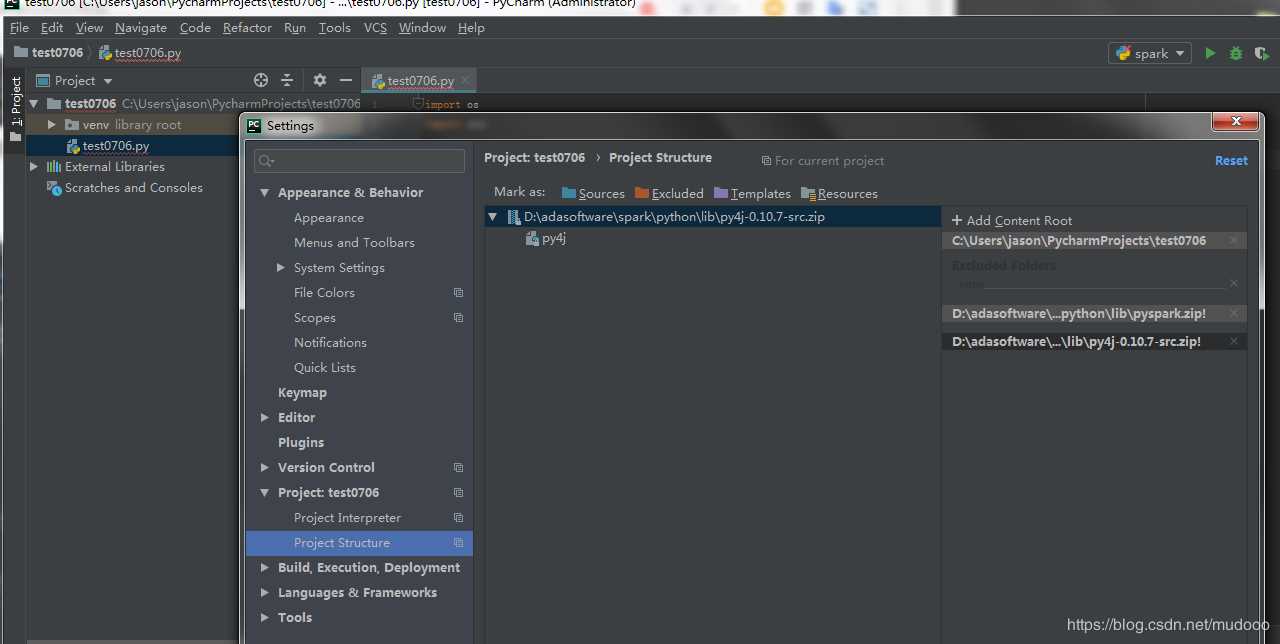
选择 File->setting->你的project->project structure
右上角Add content root添加:py4j-some-version.zip和pyspark.zip的路径(这两个文件都在Spark中的python文件夹下)
保存即可
7.测试是否配置成功,程序代码如下,创建一个python程序放进去就可以:
import os
import sys
# Path for spark source folder
os.environ['SPARK_HOME'] = "D:\adasoftware\spark"
# Append pyspark to Python Path
sys.path.append("D:\adasoftware\spark\python")
try:
from pyspark import SparkContext
from pyspark import SparkConf
print("Successfully imported Spark Modules")
except ImportError as e:
print("Can not import Spark Modules", e)
sys.exit(1)
若程序正常输出: "Successfully imported Spark Modules"就说明环境已经可以正常执行。

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。