Python 实现文件读写、坐标寻址、查找替换功能
读文件
打开文件(文件需要存在)
#打开文件
f = open("data.txt","r") #设置文件对象
print(f)#文件句柄
f.close() #关闭文件
#为了方便,避免忘记close掉这个文件对象,可以用下面这种方式替代
with open('data.txt',"r") as f: #设置文件对象
str = f.read() #可以是随便对文件的操作

完全读取文件
#完全读取文件
f = open("data.txt","r") #设置文件对象
string1 = f.read() #将txt文件的所有内容读入到字符串string1中
f.close() #将文件关闭
print(string1)

按按行读取整个文件方法一(删除回车)
#按行读取整个文件方法一(删除回车)
data = []
f = open("data.txt","r") #设置文件对象
line = f.readline()
if line !='\n' and line[len(line) -1 if len(line)-1>0 else 0] == "\n":#去掉换行符,也可以不去
line_ = line[:-1]
data.append(line_)
while line: #直到读取完文件
line = f.readline() #读取一行文件,包括换行符
if line !='' and line[len(line) -1 if len(line)-1>0 else 0] == "\n":#去掉换行符,也可以不去
line_ = line[:-1]
data.append(line_)
f.close() #关闭文件
print(data)

按行读取整个文件方法一(不删除回车)
#按行读取整个文件方法一(不删除回车)
data = []
f = open("data.txt","r") #设置文件对象
line = f.readline()
data.append(line)
while line: #直到读取完文件
line = f.readline() #读取一行文件,包括换行符
if line !='':
data.append(line)
f.close() #关闭文件
print(data)

按行读取整个文件第二种方法
#按行读取整个文件第二种方法
data = []
for line in open("data.txt","r"): #设置文件对象并读取每一行文件
data.append(line) #将每一行文件加入到list中
print(data )

按行读取整个文件第三种方法
f = open("data.txt","r") #设置文件对象
data = f.readlines() #直接将文件中按行读到list里,效果与方法2一样
f.close() #关闭文件
print(data)

将文件读入numpy数组中
#将文件读入数组中
import numpy as np
data = np.loadtxt("data.txt") #将文件中数据加载到data数组里
print(data)

写文件列表写入文件
#列表写入文件(直接)
data = ['a','b','c']
#单层列表写入文件
with open("data.txt","w") as f:
f.writelines(data)

#列表写入文件(加入一些东西)
data = ['a','b','c']
#单层列表写入文件
with open("data.txt","w") as f:
for i in data:
f.write(i+'\r\n')
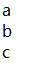
#二维列表写入文件
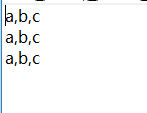
data =[ ['a','b','c'],['a','b','c'],['a','b','c']]
with open("data.txt","w") as f: #设置文件对象
for i in data:
i = str(i).strip('[').strip(']').replace(',','').replace('\'','').replace(' ',',')+'\r\n' #将其中每一个列表规范化成字符串
print(i)
f.write(i)
#第二种方法,直接将每一项都写入文件
data =[ ['a','b','c'],['a','b','c'],['a','b','c']]
with open("data.txt","w") as f: #设置文件对象
for i in data: #对于双层列表中的数据
f.writelines(i)
#将数组写入文件


import numpy as np
data =[ [1,2,3],[4,5,6],[7,8,9]]
# 第一种方法将数组中数据写入到data.txt文件
np.savetxt("data1.txt",data)
# 第二种方法将数组中数据写入到data.npy文件
np.save("data",data)
import numpy as np
filename = 'data.txt' # txt文件和当前脚本在同一目录下,所以不用写具体路径
dataele_list = []
with open(filename, 'r') as f:
while True:
lines = f.readline() # 整行读取数据
if not lines:
break
dataele_tmp = [float(i) for i in lines.split()] # 将整行数据分割处理,如果分割符是空格,括号里就不用传入参数,如果是逗号, 则传入‘,'字符。
dataele_list.append(dataele_tmp) # 添加新读取的数据
dataele_np = np.array(dataele_list) # 将数据从list类型转换为array类型。
print(dataele_np)
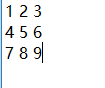

非替换写入
#非替换写入
#r+ 模式的指针默认是在文件的开头
# 如果直接写入,则会覆盖源文件,通过read() 读取文件后,指针会移到文件的末尾,再写入数据就不会有问题了。
# 这里也可以使用a 模式
f2 = open('data.txt','r+')
f2.read()
f2.write('\r\nhello boy!')
f2.close()
#非替换写入
f2 = open('data.txt','a')
f2.write('\r\nhello fff!')
f2.close()

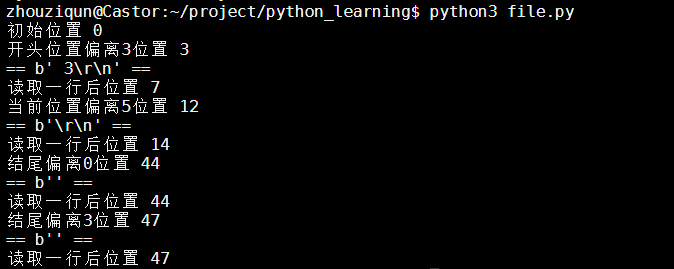
文件坐标插入读取
# 在开始使用open打开文件时候,将打开方式从r,换成rb即可 才可以使用seek移动
f = open('data.txt','rb')
#f.tell() #获取指针位置
print("初始位置",f.tell())
# 开头位置偏离3位置
f.seek(3,0)
print("开头位置偏离3位置",f.tell())
print("==",f.readline(),"==")
print("读取一行后位置",f.tell())
# 当前位置偏离5位置
f.seek(5,1)
print("当前位置偏离5位置",f.tell())
print("==",f.readline(),"==")
print("读取一行后位置",f.tell())
# 结尾偏离5位置
f = open('data.txt','rb')
f.seek(0,2)
print("结尾偏离0位置",f.tell())
print("==",f.readline(),"==")
print("读取一行后位置",f.tell())
f.seek(3,2)
print("结尾偏离3位置",f.tell())
print("==",f.readline(),"==")
print("读取一行后位置",f.tell())
内容查找
# 内容查找
import re
f = open('data.txt')
source = f.read()
f.close()
r = 'www'
s = len(re.findall(r,source))
print(s)
import re
f = open("data.txt",'r')
count = 0
for s in f.readlines():
li = re.findall("www",s)
if len(li)>0:
count = count + len(li)
print ("Search",count, "www")
f.close()


替换
#替换
f1 = open('data.txt','r')
f2 = open('data2.txt','w')
for s in f1.readlines():
f2.write(s.replace('www','w')+'\r\n')
f1.close()
f2.close()

#排序 去除空行 注释
f = open('data.txt')
result = list()
for line in f.readlines(): # 逐行读取数据
line = line.strip() #去掉每行头尾空白
if not len(line) or line.startswith('#'): # 判断是否是空行或注释行
continue #是的话,跳过不处理
result.append(line) #保存
f.close()
result.sort() #排序结果
print(result)
f = open('data2.txt','w')
for line in result:
f.write(line+'\r\n')


总结
以上所述是小编给大家介绍的Python 实现文件读写、坐标寻址、查找替换功能,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对【听图阁-专注于Python设计】网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!