python使用sklearn实现决策树的方法示例
1. 基本环境
安装 anaconda 环境, 由于国内登陆不了他的官网 https://www.continuum.io/downloads, 不过可以使用国内的镜像站点: https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/
添加绘图工具 Graphviz http://www.graphviz.org/Download_windows.php
安装后, 将bin 目录内容添加到环境变量path 即可
参考blog : /post/169878.htm
官网技术文档 : http://scikit-learn.org/stable/modules/tree.html
2. 遇到的一些问题
csv 文件读取 https://docs.python.org/3.5/library/csv.html?highlight=csv
https://docs.python.org/2/library/csv.html?highlight=csv
3. 实现
数据文件:

这是一个给定 4 个属性, age, income, student, credit_rating 以及 一个 标记属性 class_buys_computer 的数据集, 我们需要根据这个数据集进行分析并构建一颗决策树
代码实现:
核心就是调用 tree 的 DecisionTreeClassifier 方法对数据进行 训练得到一颗决策树
# -*- coding: utf-8 -*-
"""
Created on Sun Dec 25 11:25:40 2016
@author: Administrator
"""
from sklearn.feature_extraction import DictVectorizer
import csv
from sklearn import tree
from sklearn import preprocessing
from sklearn.externals.six import StringIO
import pydotplus
from IPython.display import Image
# Read in the csv file and put features into list of dict and list of class label
allElectornicsData = open('AllElectronics.csv', 'r')
reader = csv.reader(allElectornicsData)
# headers = reader.next() python2.7 supported 本质获取csv 文件的第一行数据
#headers = reader.__next__() python 3.5.2
headers = next(reader)
print(headers)
featureList = []
labelList = []
for row in reader:
labelList.append(row[len(row) - 1])
rowDict = {}
for i in range(1, len(row) - 1):
rowDict[headers[i]] = row[i]
featureList.append(rowDict)
print(featureList)
print(labelList)
# Vetorize features
vec = DictVectorizer()
dummyX = vec.fit_transform(featureList).toarray()
print("dummyX: " + str(dummyX))
print(vec.get_feature_names())
print("labelList: " + str(labelList))
# vectorize class labels
lb = preprocessing.LabelBinarizer()
dummyY = lb.fit_transform(labelList)
print("dummyY: ", str(dummyY))
# Using decision tree for classification ===========【此处调用为算法核心】============
#clf = tree.DecisionTreeClassifier(criterion='entropy')
clf = tree.DecisionTreeClassifier(criterion='gini')
clf = clf.fit(dummyX, dummyY)
print("clf: ", str(clf))
# Visualize model
# dot -Tpdf iris.dot -o ouput.pdf
with open("allElectronicInformationGainOri.dot", 'w') as f:
f = tree.export_graphviz(clf, feature_names = vec.get_feature_names(), out_file = f)
# predict
oneRowX = dummyX[0, :]
print("oneRowX: " + str(oneRowX))
newRowX = oneRowX
newRowX[0] = 1
newRowX[2] = 0
print("newRowX: " + str(newRowX))
predictedY = clf.predict(newRowX)
print("predictedY: " + str(predictedY))
输出结果:
ID3 算法
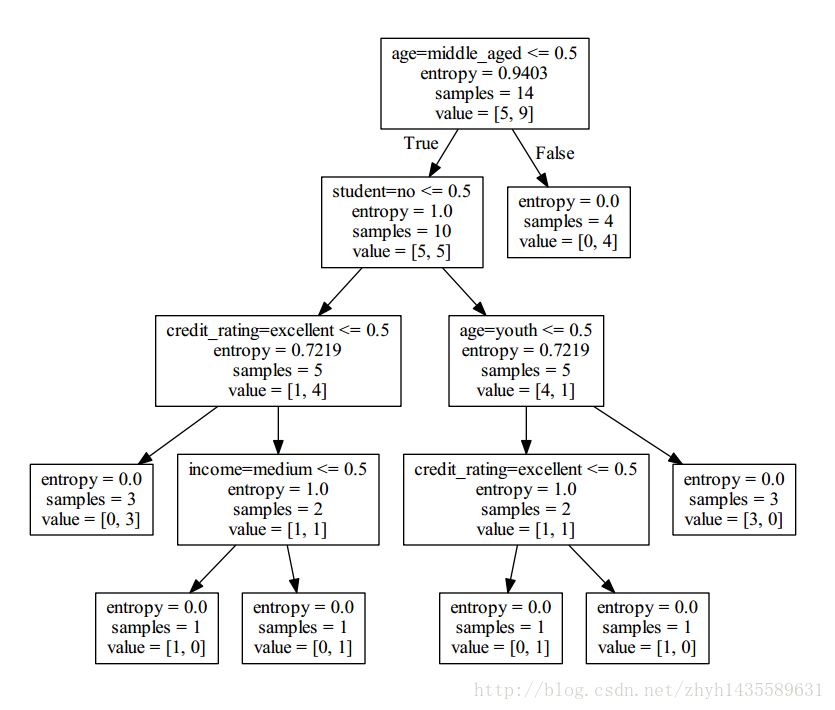
CART 算法
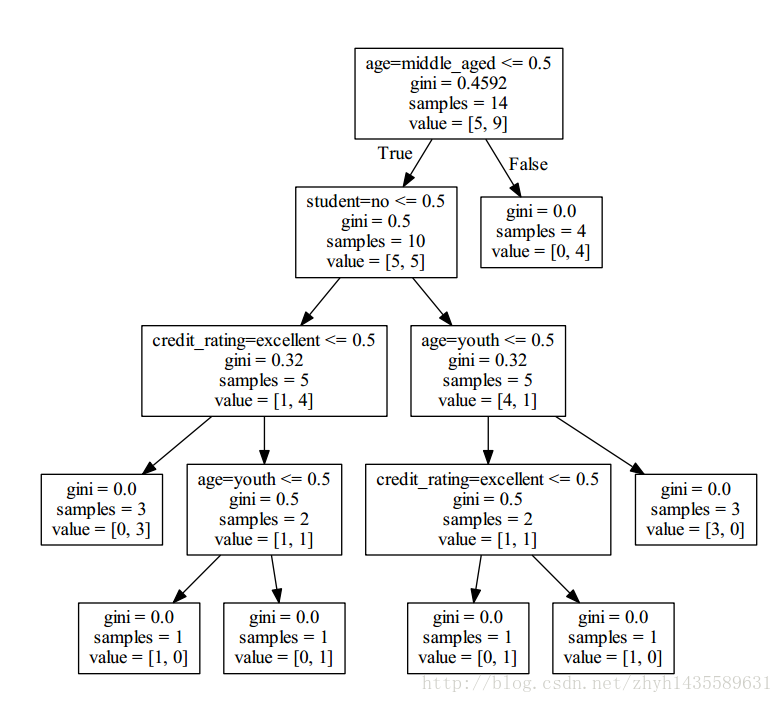
4. 决策树的优缺点
决策树的优势
- 简单易用,而且输出的结果易于解释,树能够被图形化,加深了直观的理解。
- 几乎不需要对数据进行预处理。
- 算法的开销不大,而且决策树一旦建立,对于未知样本的分类十分快,最坏情况下的时间复杂度是O(w),w是树的最大深度。
- 能够用于多类的分类。
- 能够容忍噪点。
决策树的劣势
- 容易过拟合。
- 容易被类别中占多数的类影响而产生bias,所以推荐在送入算法之间先平衡下数据中各个类别所占的比例。
- 决策树采用的是自顶向下的递归划分法,因此自定而下到了末端枝叶包含的数据量会很少,我们会依据很少的数据量取做决策,这样的决策是不具有统计意义的,这就是数据碎片的问题。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。