python爬虫 Pyppeteer使用方法解析
引言
Selenium 在被使用的时候有个麻烦事,就是环境的相关配置,得安装好相关浏览器,比如 Chrome、Firefox 等等,然后还要到官方网站去下载对应的驱动,最重要的还需要安装对应的 Python Selenium 库,确实是不是很方便,另外如果要做大规模部署的话,环境配置的一些问题也是个头疼的事情。那么本节就介绍另一个类似的替代品,叫做 Pyppeteer。
Pyppeteer简介
注意,本节讲解的模块叫做 Pyppeteer,不是 Puppeteer。Puppeteer 是 Google 基于 Node.js 开发的一个工具,有了它我们可以通过 JavaScript 来控制 Chrome 浏览器的一些操作,当然也可以用作网络爬虫上,其 API 极其完善,功能非常强大。 而 Pyppeteer 又是什么呢?它实际上是 Puppeteer 的 Python 版本的实现,但他不是 Google 开发的,是一位来自于日本的工程师依据 Puppeteer 的一些功能开发出来的非官方版本。
在 Pyppetter 中,实际上它背后也是有一个类似 Chrome 浏览器的 Chromium 浏览器在执行一些动作进行网页渲染,首先说下 Chrome 浏览器和 Chromium 浏览器的渊源。
Chromium 是谷歌为了研发 Chrome 而启动的项目,是完全开源的。二者基于相同的源代码构建,Chrome 所有的新功能都会先在 Chromium 上实现,待验证稳定后才会移植,因此 Chromium 的版本更新频率更高,也会包含很多新的功能,但作为一款独立的浏览器,Chromium 的用户群体要小众得多。两款浏览器“同根同源”,它们有着同样的 Logo,但配色不同,Chrome 由蓝红绿黄四种颜色组成,而 Chromium 由不同深度的蓝色构成。
Pyppeteer 就是依赖于 Chromium 这个浏览器来运行的。那么有了 Pyppeteer 之后,我们就可以免去那些繁琐的环境配置等问题。如果第一次运行的时候,Chromium 浏览器没有安装,那么程序会帮我们自动安装和配置,就免去了繁琐的环境配置等工作。另外 Pyppeteer 是基于 Python 的新特性 async 实现的,所以它的一些执行也支持异步操作,效率相对于 Selenium 来说也提高了。
环境安装
由于 Pyppeteer 采用了 Python 的 async 机制,所以其运行要求的 Python 版本为 3.5 及以上
pip install pyppeteer
快速上手
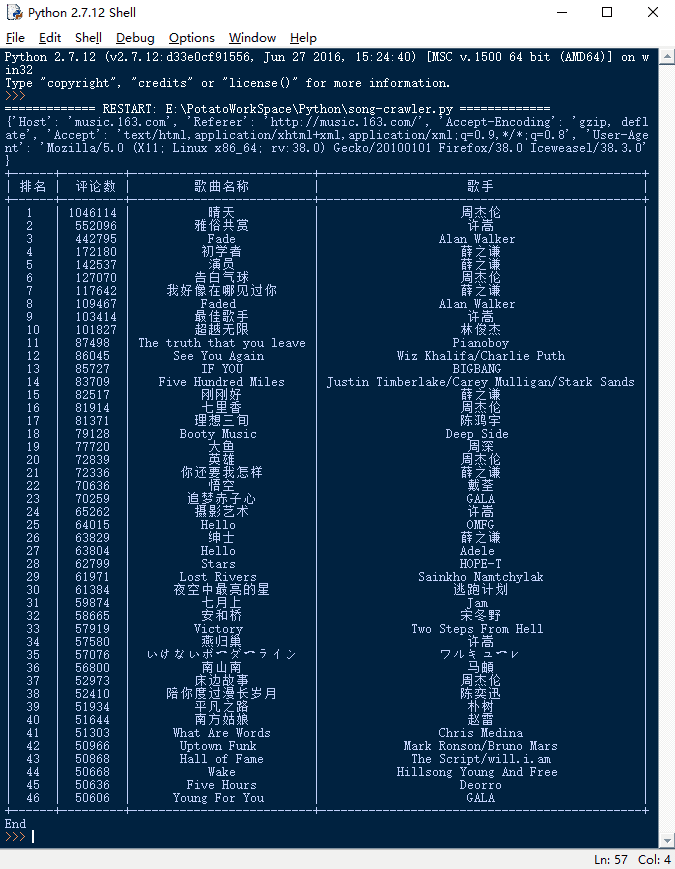
- 爬取http://quotes.toscrape.com/js/ 全部页面数据
import asyncio
from pyppeteer import launch
from lxml import etree
async def main():
browser = await launch()
page = await browser.newPage()
await page.goto('http://quotes.toscrape.com/js/')
page_text = await page.content()
tree = etree.HTML(page_text)
div_list = tree.xpath('//div[@class="quote"]')
print(len(div_list))
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
结合协程
from pyppeteer import launch
import asyncio
from lxml import etree
# 实例化浏览器对象(谷歌测试版)
async def main():
bro = await launch()
# 新建一个空白页
page = bro.newPage()
page.goto('http://quotes.toscrape.com/js/')
# 获取page当前显示页面的源码数据
page_text = await page.content()
return page_text
def parse(task):
page_text = task.result()
tree = etree.HTML(page_text)
div_list = tree.xpath('//div[@class="quote"]')
for div in div_list:
content = div.xpath('./span[1]/text()')
print(content)
c = main()
task = asyncio.ensure_future(c)
task.add_done_callback(parse)
loop = asyncio.get_event_loop()
loop.run_until_complete(c)
解释:
launch 方法会新建一个 Browser 对象,然后赋值给 browser,然后调用 newPage 方法相当于浏览器中新建了一个选项卡,同时新建了一个 Page 对象。然后 Page 对象调用了 goto 方法就相当于在浏览器中输入了这个 URL,浏览器跳转到了对应的页面进行加载,加载完成之后再调用 content 方法,返回当前浏览器页面的源代码。
然后进一步地,我们用 pyquery 进行同样地解析,就可以得到 JavaScript 渲染的结果了。在这个过程中,我们没有配置 Chrome 浏览器,没有配置浏览器驱动,免去了一些繁琐的步骤,同样达到了 Selenium 的效果,还实现了异步抓取。
详细用法
- 开启浏览器
- 调用 launch 方法即可,相关参数介绍:
- ignoreHTTPSErrors (bool): 是否要忽略 HTTPS 的错误,默认是 False。
- headless (bool): 是否启用 Headless 模式,即无界面模式,如果 devtools 这个参数是 True 的话,那么该参数就会被设置为 False,否则为 True,即默认是开启无界面模式的。
- executablePath (str): 可执行文件的路径,如果指定之后就不需要使用默认的 Chromium 了,可以指定为已有的 Chrome 或 Chromium。
- args (List[str]): 在执行过程中可以传入的额外参数。
- devtools (bool): 是否为每一个页面自动开启调试工具,默认是 False。如果这个参数设置为 True,那么 headless 参数就会无效,会被强制设置为 False。
- 关闭提示条:”Chrome 正受到自动测试软件的控制”,这个提示条有点烦,那咋关闭呢?这时候就需要用到 args 参数了,禁用操作如下:
- browser = await launch(headless=False, args=['--disable-infobars'])
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。