Python3 无重复字符的最长子串的实现
题目:
给定一个字符串,请你找出其中不含有重复字符的 最长子串 的长度。
示例:
示例 1:
输入: “abcabcbb”
输出: 3
解释: 因为无重复字符的最长子串是 “abc”,所以其长度为 3。
示例 2:
输入: “bbbbb”
输出: 1
解释: 因为无重复字符的最长子串是 “b”,所以其长度为 1。
示例 3:
输入: “pwwkew”
输出: 3
解释: 因为无重复字符的最长子串是 “wke”,所以其长度为 3。
请注意,你的答案必须是 子串 的长度,“pwke” 是一个子序列,不是子串。
思路:
这道题会很自然的想到暴力解法,就是按位递增依次检查子串是否重复,并记下目前最大的子串长度,如果重复就从下一位索引处的字符开始重新检查。下面是代码实现:
class Solution:
def lengthOfLongestSubstring(self, s: str) -> int:
# 最长子串的长度
max_len = 0
# 存放字符的字典
char_dict = {}
index = 0
while s[index:].__len__() >= max_len:
# 当前最长子串长度
current_len = 0
for item in s[index:]:
old_index = char_dict.get(item)
if old_index is not None:
index = old_index + 1
char_dict.clear()
break
char_dict[item] = index
index += 1
current_len += 1
if current_len > max_len:
max_len = current_len
return max_len
开始只是想跑通,没想到超出了时间限制。看起来代码显得是有点啰嗦,但是思路应该是没有问题的,我们还是从遍历的角度来优化。
优化:
在上面的代码中,当遇到重复字符时,遍历的起始点就往后挪一位,但其实两个重复字符之间的部分是不会重复的,比如字符串fbacdadfeed,在第一次从 f 开始遍历遇到重复字符即第二个 a 的时候,下一次遍历不应该从 b 开始,而是应该从前一个重复字符的后一个字符即 c 开始。
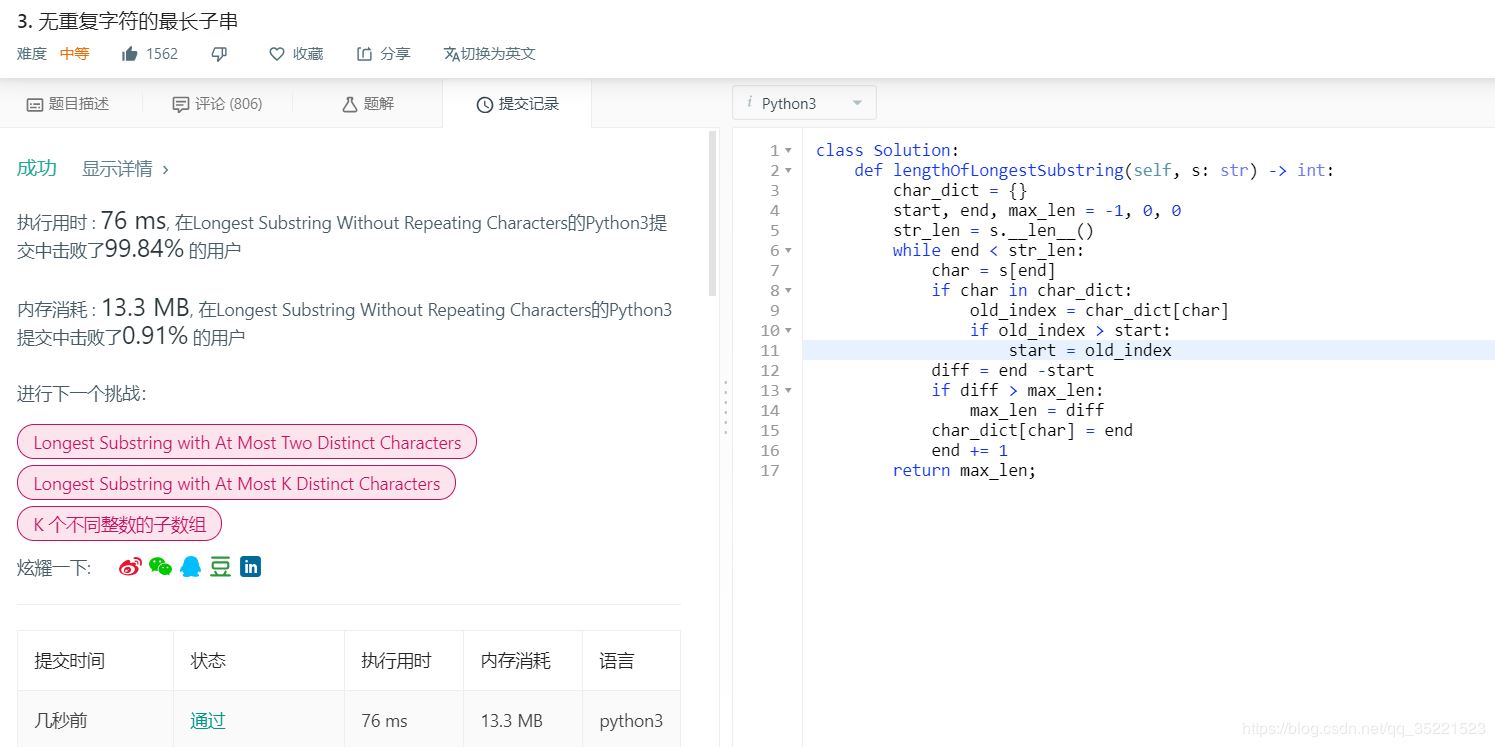
确定思想,并多次优化后的代码如下:
class Solution:
def lengthOfLongestSubstring(self, s: str) -> int:
char_dict = {}
start, end, max_len = -1, 0, 0
str_len = s.__len__()
while end < str_len:
char = s[end]
if char in char_dict:
old_index = char_dict[char]
if old_index > start:
start = old_index
diff = end -start
if diff > max_len:
max_len = diff
char_dict[char] = end
end += 1
return max_len;
这里使用了内置的.__len__()方法来获取字符串长度而不是len(),并且使用了多个看似多此一举的临时变量来存储值,比如char和diff,都是为了节省时间,蚊子小也是肉嘛。
结果也是 ok 的:
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。