利用pandas合并多个excel的方法示例
具体方法:
1使用panda read_excel 方法加载excel
2使用concat将DataFrame列表进行拼接
3然后使用pd.ExcelWriter对象和to_excel将合并后的DataFrame保存成excel
方法很简单很使用,下面是代码和excel图片
import pandas as pd
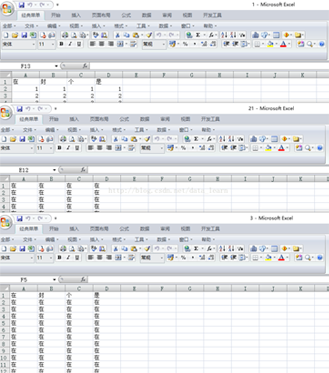
file1='C:/Users/Administrator/Desktop/00/1.xlsx'
file2='C:/Users/Administrator/Desktop/00/3.xlsx'
file3='C:/Users/Administrator/Desktop/00/21.xlsx'
file=[file1,file2,file3]
li=[]
for i in file:
li.append(pd.read_excel(i))
writer = pd.ExcelWriter('C:/Users/Administrator/Desktop/00/output.xlsx')
pd.concat(li).to_excel(writer,'Sheet1',index=False)
writer.save()
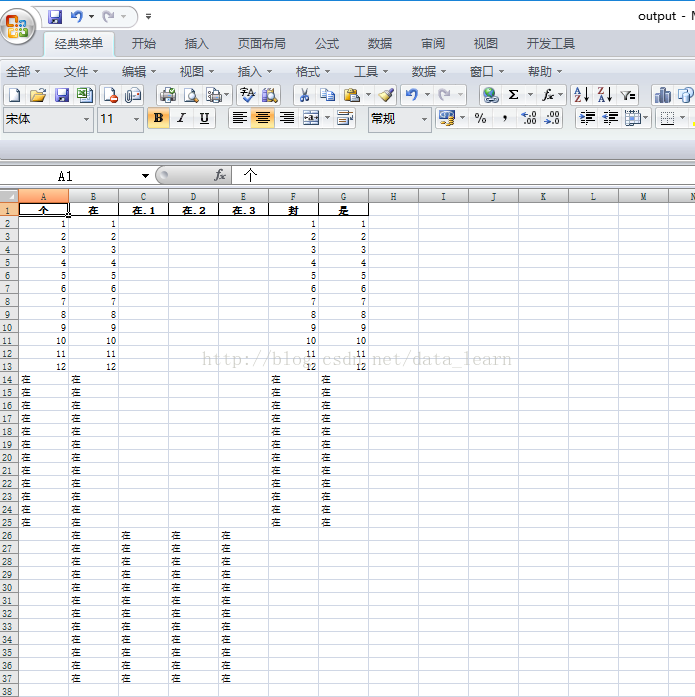
如下图:
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。