Python 导入文件过程图解
1、同级目录下调用
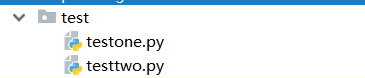
若在程序 testone.py 中导入模块 testtwo.py , 则直接使用
【import testtwo 或 from testtwo import *】
2、调用子目录下的模块
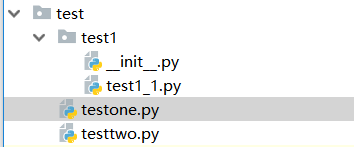
若在程序 testone.py 中导入模块 test1_1.py , 则test1文件夹下必须要有 __init__.py 文件,此时的 test1 就是一个包
导入如下:
【import test1.test1_1 或 from test1.test1_1 import *】
3、调用上级目录下的文件
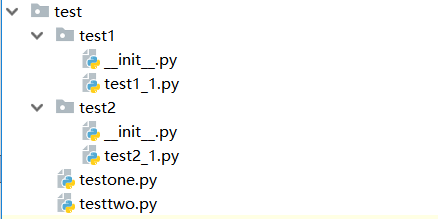
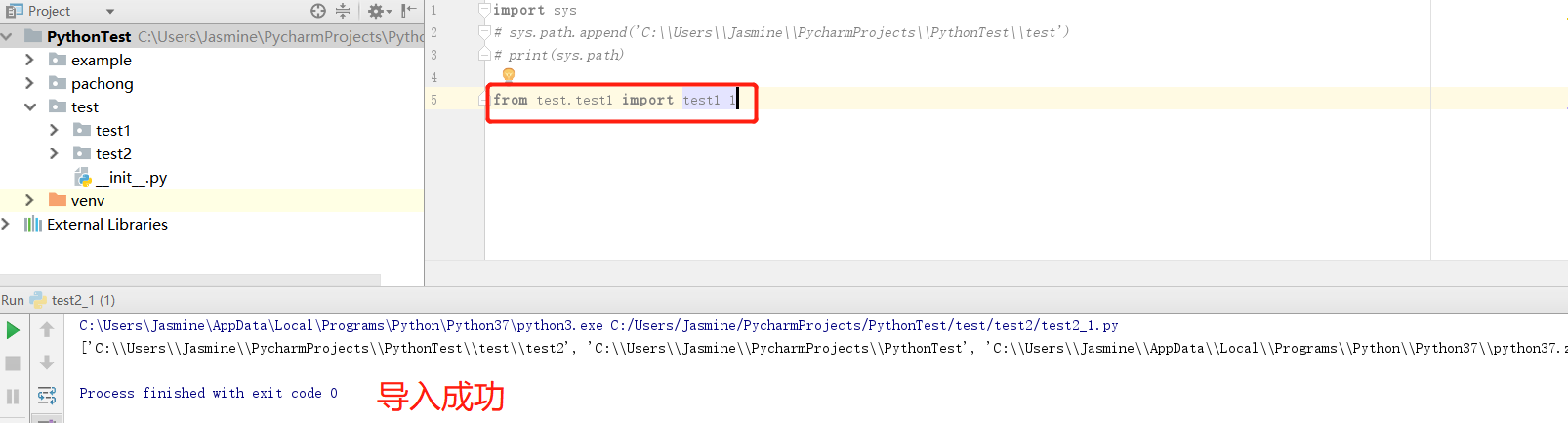
若在程序 test2_1.py 中导入模块 test1_1.py 和 testone.py。做法是我们先跳到test目录下面,直接可以调用 testone.py,然后在 test1 下建一个空文件__init__.py ,就可以像第二步调用子目录下的模块一样,通过 import test1.test1_1进行调用了。
具体代码如下:

普通文件夹与包的区别:
普通文件夹下没有__init__.py文件,而包下面是有一个__init__.py文件的
普通文件夹(Directory)
因为此时test文件下下没有__init__.py文件,所以只是一个普通的文件夹,普通的文件夹是不能作为一个模块导入的
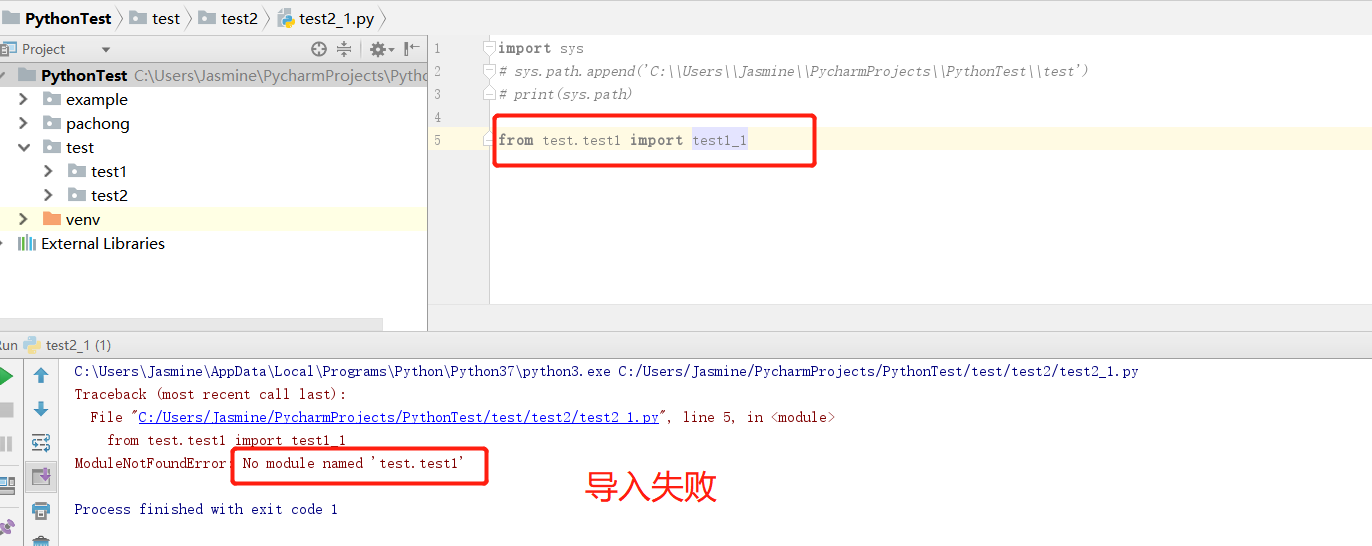
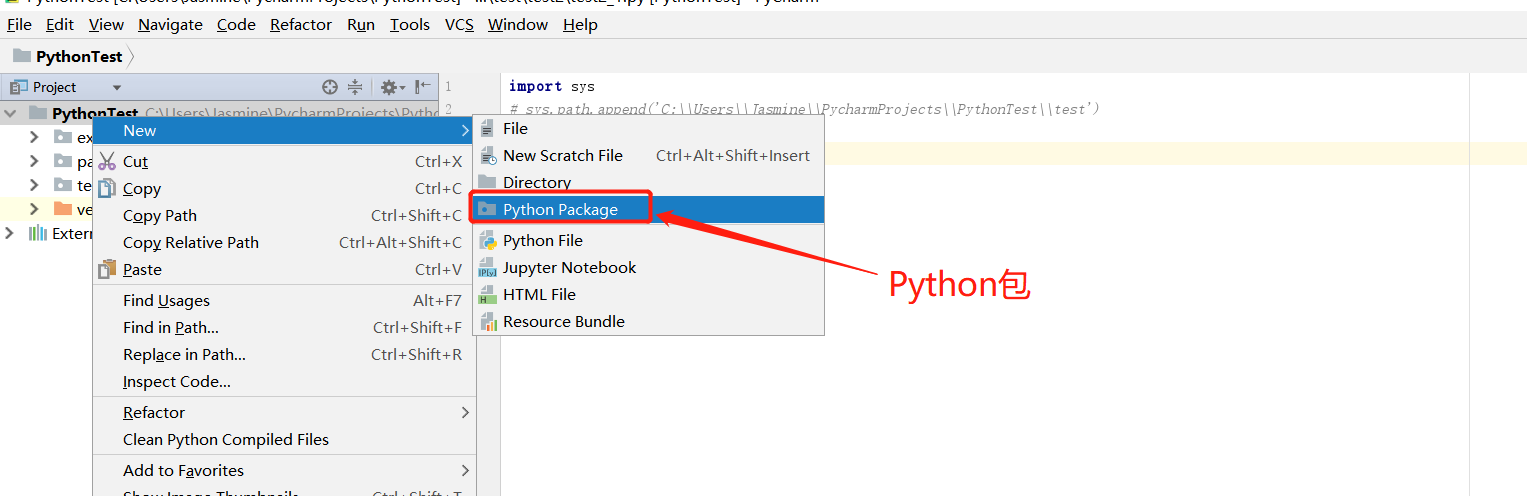
包(Python Package)
新建一个包之后,会自动生成一个__init__.py文件

参考资料:/post/126941.htm
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。