python KNN算法实现鸢尾花数据集分类
一、knn算法描述
1.基本概述
knn算法,又叫k-近邻算法。属于一个分类算法,主要思想如下:
一个样本在特征空间中的k个最近邻的样本中的大多数都属于某一个类别,则该样本也属于这个类别。其中k表示最近邻居的个数。
用二维的图例,说明knn算法,如下:
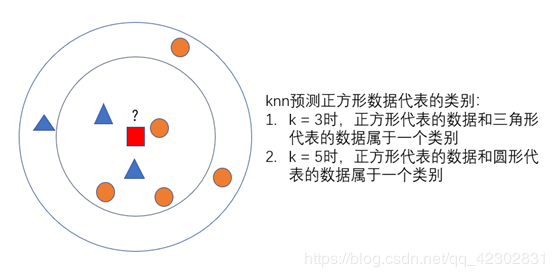
二维空间下数据之间的距离计算:

在n维空间两个数据之间:

2.具体步骤:
(1)计算待测试数据与各训练数据的距离
(2)将计算的距离进行由小到大排序
(3)找出距离最小的k个值
(4)计算找出的值中每个类别的频次
(5)返回频次最高的类别
二、鸢尾花数据集
Iris 鸢尾花数据集内包含 3 类分别为山鸢尾(Iris-setosa)、变色鸢尾(Iris-versicolor)和维吉尼亚鸢尾(Iris-virginica),共 150 条记录,每类各 50 个数据,每条记录都有 4 项特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度,可以通过这4个特征预测鸢尾花卉属于哪一品种。
iris数据集包含在sklearn库当中,具体在sklearn\datasets\data文件夹下,文件名为iris.csv。以本机为例。其路径如下:
D:\python\lib\site-packages\sklearn\datasets\data\iris.csv
其中数据如下格式:
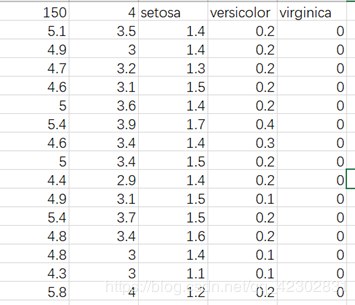
第一行数据意义如下:
150:数据集中数据的总条数
4:特征值的类别数,即花萼长度、花萼宽度、花瓣长度、花瓣宽度。
setosa、versicolor、virginica:三种鸢尾花名
从第二行开始:
第一列为花萼长度值
第二列为花萼宽度值
第三列为花瓣长度值
第四列为花瓣宽度值
第五列对应是种类(三类鸢尾花分别用0,1,2表示)
三、算法实现
1.算法流程图:
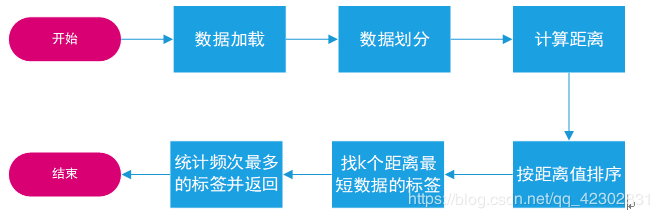
从以上流程图可以看出,knn算法包含后四步操作,所以将整个程序分为三个模块。
2.具体实现
(1)方法一
①利用slearn库中的load_iris()导入iris数据集
②使用train_test_split()对数据集进行划分
③KNeighborsClassifier()设置邻居数
④利用fit()构建基于训练集的模型
⑤使用predict()进行预测
⑥使用score()进行模型评估
说明:本代码来源于《Python机器学习基础教程》在此仅供学习使用。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
# 载入数据集
iris_dataset = load_iris()
# 数据划分
X_train, X_test, y_train, y_test = train_test_split(iris_dataset['data'], iris_dataset['target'], random_state=0)
# 设置邻居数
knn = KNeighborsClassifier(n_neighbors=1)
# 构建基于训练集的模型
knn.fit(X_train, y_train)
# 一条测试数据
X_new = np.array([[5, 2.9, 1, 0.2]])
# 对X_new预测结果
prediction = knn.predict(X_new)
print("预测值%d" % prediction)
# 得出测试集X_test测试集的分数
print("score:{:.2f}".format(knn.score(X_test,y_test)))
(2)方法二
①使用读取文件的方式,使用open、以及csv中的相关方法载入数据
②输入测试集和训练集的比率,对载入的数据使用shuffle()打乱后,计算训练集及测试集个数对特征值数据和对应的标签数据进行分割。
③将分割后的数据,计算测试集数据与每一个训练集的距离,使用norm()函数直接求二范数,或者载入数据使用np.sqrt(sum((test - train) ** 2))求得距离,使用argsort()将距离进行排序,并返回索引值,
④取出值最小的k个,获得其标签值,存进一个字典,标签值为键,出现次数为值,对字典进行按值的大小递减排序,将字典第一个键的值存入预测结果的列表中,计算完所有测试集数据后,返回一个列表。
⑤将预测结果与测试集本身的标签进行对比,得出分数。
import csv
import random
import numpy as np
import operator
def openfile(filename):
"""
打开数据集,进行数据处理
:param filename: 数据集的路径
:return: 返回数据集的数据,标签,以及标签名
"""
with open(filename) as csv_file:
data_file = csv.reader(csv_file)
temp = next(data_file)
# 数据集中数据的总数量
n_samples = int(temp[0])
# 数据集中特征值的种类个数
n_features = int(temp[1])
# 标签名
target_names = np.array(temp[2:])
# empty()函数构造一个未初始化的矩阵,行数为数据集数量,列数为特征值的种类个数
data = np.empty((n_samples, n_features))
# empty()函数构造一个未初始化的矩阵,行数为数据集数量,1列,数据格式为int
target = np.empty((n_samples,), dtype=np.int)
for i, j in enumerate(data_file):
# 将数据集中的将数据转化为矩阵,数据格式为float
# 将数据中从第一列到倒数第二列中的数据保存在data中
data[i] = np.asarray(j[:-1], dtype=np.float64)
# 将数据集中的将数据转化为矩阵,数据格式为int
# 将数据集中倒数第一列中的数据保存在target中
target[i] = np.asarray(j[-1], dtype=np.int)
# 返回 数据,标签 和标签名
return data, target, target_names
def random_number(data_size):
"""
该函数使用shuffle()打乱一个包含从0到数据集大小的整数列表。因此每次运行程序划分不同,导致结果不同
改进:
可使用random设置随机种子,随机一个包含从0到数据集大小的整数列表,保证每次的划分结果相同。
:param data_size: 数据集大小
:return: 返回一个列表
"""
number_set = []
for i in range(data_size):
number_set.append(i)
random.shuffle(number_set)
return number_set
def split_data_set(data_set, target_data, rate=0.25):
"""
说明:分割数据集,默认数据集的25%是测试集
:param data_set: 数据集
:param target_data: 标签数据
:param rate: 测试集所占的比率
:return: 返回训练集数据、训练集标签、训练集数据、训练集标签
"""
# 计算训练集的数据个数
train_size = int((1-rate) * len(data_set))
# 获得数据
data_index = random_number(len(data_set))
# 分割数据集(X表示数据,y表示标签),以返回的index为下标
x_train = data_set[data_index[:train_size]]
x_test = data_set[data_index[train_size:]]
y_train = target_data[data_index[:train_size]]
y_test = target_data[data_index[train_size:]]
return x_train, x_test, y_train, y_test
def data_diatance(x_test, x_train):
"""
:param x_test: 测试集
:param x_train: 训练集
:return: 返回计算的距离
"""
# sqrt_x = np.linalg.norm(test-train) # 使用norm求二范数(距离)
distances = np.sqrt(sum((x_test - x_train) ** 2))
return distances
def knn(x_test, x_train, y_train, k):
"""
:param x_test: 测试集数据
:param x_train: 训练集数据
:param y_train: 测试集标签
:param k: 邻居数
:return: 返回一个列表包含预测结果
"""
# 预测结果列表,用于存储测试集预测出来的结果
predict_result_set=[]
# 训练集的长度
train_set_size = len(x_train)
# 创建一个全零的矩阵,长度为训练集的长度
distances = np.array(np.zeros(train_set_size))
# 计算每一个测试集与每一个训练集的距离
for i in x_test:
for indx in range(train_set_size):
# 计算数据之间的距离
distances[indx] = data_diatance(i, x_train[indx])
# 排序后的距离的下标
sorted_dist = np.argsort(distances)
class_count = {}
# 取出k个最短距离
for i in range(k):
# 获得下标所对应的标签值
sort_label = y_train[sorted_dist[i]]
# 将标签存入字典之中并存入个数
class_count[sort_label]=class_count.get(sort_label, 0) + 1
# 对标签进行排序
sorted_class_count = sorted(class_count.items(), key=operator.itemgetter(1), reverse=True)
# 将出现频次最高的放入预测结果列表
predict_result_set.append(sorted_class_count[0][0])
# 返回预测结果列表
return predict_result_set
def score(predict_result_set, y_test):
"""
:param predict_result_set: 预测结果列表
:param y_test: 测试集标签
:return: 返回测试集精度
"""
count = 0
for i in range(0, len(predict_result_set)):
if predict_result_set[i] == y_test[i]:
count += 1
score = count / len(predict_result_set)
return score
if __name__ == "__main__":
iris_dataset = openfile('iris.csv')
# x_new = np.array([[5, 2.9, 1, 0.2]])
x_train, x_test, y_train, y_test = split_data_set(iris_dataset[0], iris_dataset[1])
result = knn(x_test,x_train, y_train, 6)
print("原有标签:", y_test)
# 为了方便对比查看,此处将预测结果转化为array,可直接打印结果
print("预测结果:", np.array(result))
score = score(result, y_test)
print("测试集的精度:%.2f" % score)
四、运行结果



结果不同,因为每次划分的训练集和测试集不同,具体见random_number()方法。
五、总结
在本次使用python实现knn算法时,遇到了很多困难,如数据集的加载,数据的格式不能满足后续需要,因此阅读了sklearn库中的一部分代码,有选择性的进行了复用。数据与标签无法分离,或是数据与标签排序后后无法对应的情况,查询许多资料后使用argsort()完美解决该问题。出现了n多错误,通过多次调试之后最终完成。
附:本次实验参考 :
①*郑捷《机器学习算法原理与编程实践》
②《Python机器学习基础教程》
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。