Python搭建代理IP池实现存储IP的方法
上一文写了如何从代理服务网站提取 IP,本文就讲解如何存储 IP,毕竟代理池还是要有一定量的 IP 数量才行。存储的方式有很多,直接一点的可以放在一个文本文件中,但操作起来不太灵活,而我选择的是 MySQL 数据库,因为数据库便于管理而且功能强大,当然你还可以选择其他数据库,比如 MongoDB、Redis 等。
代码地址:https://github.com/Stevengz/Proxy_pool
另外三篇:
Python搭建代理IP池(一)- 获取 IP
Python搭建代理IP池(三)- 检测 IP
Python搭建代理IP池(四)- 接口设置与整体调度
使用的库:pymysql
定义规则
数据库存储的主要对象是各个 IP,首先需要保证不重复,另外还需要标 IP 的可用情况,而且需要动态实时处理每个 IP,因此还需要定义一个分数字段,分数是可以重复的,最好是整数类型,每个 IP 都有一个分数,表现其可用性
对于代理池来说,分数可以作为我们判断一个代理可用不可用的标志,我们将设置一个最高分(满分,值由自己设置),代表可用,0 设为最低分,代表不可用。从代理池中获取代理的时候会先从满分 IP 中随机获取一个,注意这里是随机,这样可以保证每个可用 IP 都会被调用到,如果没有满分的就从所有 IP 从随机选一个
分数规则如下:
- 满分为可用,检测器会定时循环检测每个 IP 的可用情况,一旦检测到有可用的 IP 就立即置为满分,检测到不可用就将分数减 1,减至 0 后移除。
- 新获取的代理添加时将分数置为 10,当测试可行立即置 100,不可行分数减 1,减至 0 后移除
添加设置
先在一个文件中定义一些配置信息,如数据库的设置、一些不变量如满分的数值等
setting.py
# 数据库地址 HOST = '127.0.0.1' # MySql端口 MYSQL_PORT = 3306 # MySQl用户名、密码 MYSQL_USERNAME = '***' MYSQL_PASSWORD = '***' # 数据库名 SQL_NAME = 'test' # 代理等级 MAX_SCORE = 30 MIN_SCORE = 0 INITIAL_SCORE = 10 # 代理池数量界限 POOL_UPPER_THRESHOLD = 1000
MAX_SCORE、MIN_SCORE、INITIAL_SCORE 分别代表最大分数、最小分数、初始分数
定义方法
定义一个类来操作数据库的有序集合,内含一些方法来实现分数的设置、代理的获取等
db.py
import pymysql
from error import PoolEmptyError
from setting import *
from random import choice
import re
class MySqlClient(object):
# 初始化
def __init__(self, host=HOST, port=MYSQL_PORT, username=MYSQL_USERNAME, password=MYSQL_PASSWORD, sqlname=SQL_NAME):
self.db = pymysql.connect(host=host, user=username, password=password, port=port, db=sqlname)
self.cursor = self.db.cursor()
# 添加代理IP
def add(self, ip, score=INITIAL_SCORE):
sql_add = "INSERT INTO PROXY (IP,SCORE) VALUES ('%s', %s)" % (ip, score)
if not re.match('\d+\.\d+\.\d+\.\d+\:\d+', ip):
print('代理不符合规范', ip, '丢弃')
return
if not self.exists(ip):
self.cursor.execute(sql_add)
self.db.commit()
# 减少代理分数
def decrease(self, ip):
sql_get = "SELECT * FROM PROXY WHERE IP='%s'" % (ip)
self.cursor.execute(sql_get)
score = self.cursor.fetchone()[1]
print(score)
if score and score > MIN_SCORE:
print('代理', ip, '当前分数', score, '减1')
sql_change = "UPDATE PROXY SET SCORE = %s WHERE IP = '%s'" % (score-1, ip)
else:
print('代理', ip, '当前分数', score, '移除')
sql_change = "DELETE FROM PROXY WHERE IP = %s" % (ip)
self.cursor.execute(sql_change)
self.db.commit()
# 分数最大化
def max(self, ip):
print('代理', ip, '可用,设置为', MAX_SCORE)
sql_max = "UPDATE PROXY SET SCORE = %s WHERE IP = '%s'" % (MAX_SCORE, ip)
self.cursor.execute(sql_max)
self.db.commit()
# 随机获取有效代理
def random(self):
# 先从满分中随机选一个
sql_max = "SELECT * FROM PROXY WHERE SCORE=%s" % (MAX_SCORE)
if self.cursor.execute(sql_max):
results = self.cursor.fetchall()
return choice(results)[0]
# 没有满分则随机选一个
else:
sql_all = "SELECT * FROM PROXY WHERE SCORE BETWEEN %s AND %s" % (MIN_SCORE, MAX_SCORE)
if self.cursor.execute(sql_all):
results = self.cursor.fetchall()
return choice(results)[0]
else:
raise PoolEmptyError
# 判断是否存在
def exists(self, ip):
sql_exists = "SELECT 1 FROM PROXY WHERE IP='%s' limit 1" % ip
return self.cursor.execute(sql_exists)
# 获取数量
def count(self):
sql_count = "SELECT * FROM PROXY"
return self.cursor.execute(sql_count)
# 获取全部
def all(self):
self.count()
return self.cursor.fetchall()
# 批量获取
def batch(self, start, stop):
sql_batch = "SELECT * FROM PROXY LIMIT %s, %s" % (start, stop - start)
self.cursor.execute(sql_batch)
return self.cursor.fetchall()
方法作用:
- init():初始化的方法,参数是 MySQL 的连接信息,默认的连接信息已经定义为常量,在 init() 方法中初始化建立 MySQL 连接。这样当 MySqlClient 类初始化的时候就建立了 MySQL 的连接
- add():向数据库添加代理并设置分数,默认的分数是 INITIAL_SCORE 也就是 10,返回结果是添加的结果
- decrease():在 检测无效的时候设置分数减 1 的方法,传入代理,然后将此代理的分数减 1,如果达到最低值就删除
- max():将代理的分数设置为 MAX_SCORE,也就是当 IP 有效时的设置
- random():随机获取 IP 的方法,首先获取满分的 IP,然后随机选择一个返回,如果不存在满分的 IP,则随机选择一个返回,否则抛出异常
- exists():判断 IP 是否存在于数据库中
- count():返回当前 IP个数
- all():返回所有的 IP,供检测使用
- batch():返回数据库中从第 start 行开始(从0开始数)的共 stop-start 行数据
抓取保存
当数据库设置好了之后,就可以直接把抓取的 IP 直接放在数据库中了
直接把前面用到的抓取代码更改一下就行了
getter.py
from crawler import Crawler
from db import MySqlClient
from setting import *
import sys
class Getter():
def __init__(self):
self.mysql = MySqlClient()
self.crawler = Crawler()
# 判断数量是否足够
def is_over_threshold(self):
if self.mysql.count() >= POOL_UPPER_THRESHOLD:
return True
else:
return False
def run(self):
print('获取器开始执行')
if not self.is_over_threshold():
for callback_label in range(self.crawler.__CrawlFuncCount__):
callback = self.crawler.__CrawlFunc__[callback_label]
# 获取代理
all_ip = self.crawler.get_proxies(callback)
sys.stdout.flush()
for ip in all_ip:
self.mysql.add(ip)
if __name__ == '__main__':
get = Getter()
get.run()
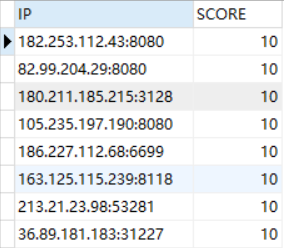
结果:
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。