Python使用Opencv实现图像特征检测与匹配的方法
特征检测是计算机对一张图像中最为明显的特征进行识别检测并将其勾画出来。大多数特征检测都会涉及图像的角点、边和斑点的识别、或者是物体的对称轴。
角点检测 是由Opencv的cornerHarris函数实现,其他函数参数说明如下:
cv2.cornerHarris(src=gray, blockSize=9, ksize=23, k=0.04) # cornerHarris参数: # src - 数据类型为 float32 的输入图像。 # blockSize - 角点检测中要考虑的领域大小。 # ksize - Sobel 求导中使用的窗口大小 # k - Harris 角点检测方程中的自由参数,取值参数为 [0,04,0.06].
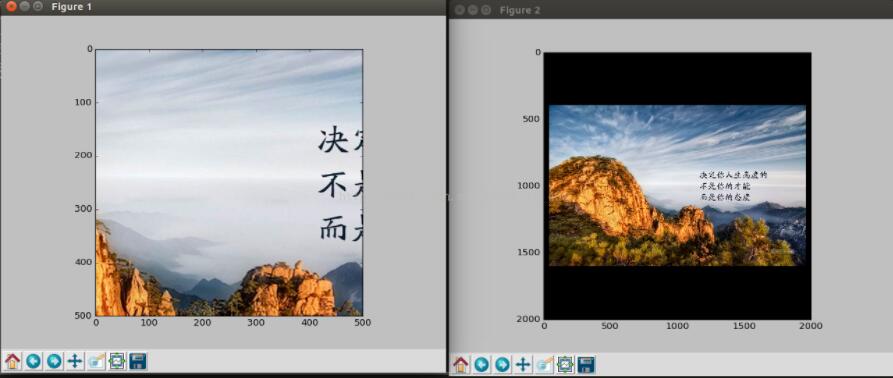
以国际象棋为例,这是计算机视觉最为常见的分析对象,如图所示:
角点检测代码如下:
import cv2
import numpy as np
img = cv2.imread('chess_board.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# cornerHarris函数图像格式为 float32 ,因此需要将图像转换 float32 类型
gray = np.float32(gray)
# cornerHarris参数:
# src - 数据类型为 float32 的输入图像。
# blockSize - 角点检测中要考虑的领域大小。
# ksize - Sobel 求导中使用的窗口大小
# k - Harris 角点检测方程中的自由参数,取值参数为 [0,04,0.06].
dst = cv2.cornerHarris(src=gray, blockSize=9, ksize=23, k=0.04)
# 变量a的阈值为0.01 * dst.max(),如果dst的图像值大于阈值,那么该图像的像素点设为True,否则为False
# 将图片每个像素点根据变量a的True和False进行赋值处理,赋值处理是将图像角点勾画出来
a = dst>0.01 * dst.max()
img[a] = [0, 0, 255]
# 显示图像
while (True):
cv2.imshow('corners', img)
if cv2.waitKey(120) & 0xff == ord("q"):
break
cv2.destroyAllWindows()
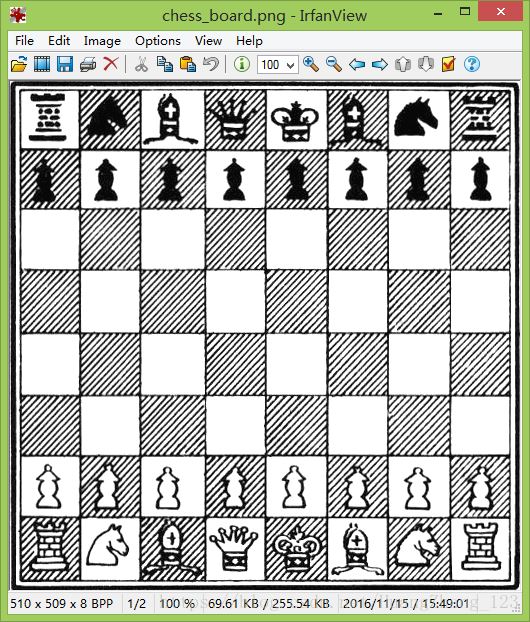
运行代码,结果如图所示:

但有时候,图像的像素大小对角点存在一定的影响。比如图像越小,角点看上去趋向近似一条直线,这样很容易造成角点的丢失。如果按照上述的检测方法,会造成角点检测结果不相符,因此引入DoG和SIFT算法进行检测。Opencv的SIFT类是DoG和SIFT算法组合。
DoG是对同一图像使用不同高斯滤波器所得的结果。
SIFT是通过一个特征向量来描述关键点周围区域的情况。
我们以下图为例:
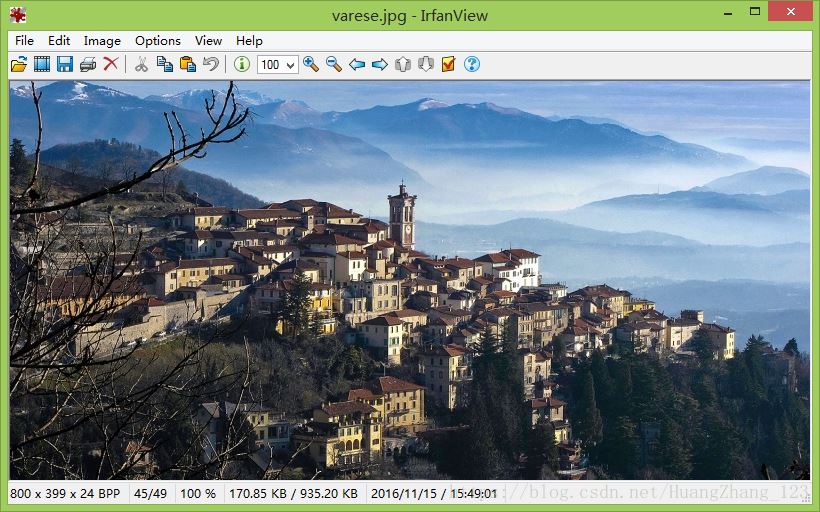
import cv2
# 读取图片并灰度处理
imgpath = 'varese.jpg'
img = cv2.imread(imgpath)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 创建SIFT对象
sift = cv2.xfeatures2d.SIFT_create()
# 将图片进行SURF计算,并找出角点keypoints,keypoints是检测关键点
# descriptor是描述符,这是图像一种表示方式,可以比较两个图像的关键点描述符,可作为特征匹配的一种方法。
keypoints, descriptor = sift.detectAndCompute(gray, None)
# cv2.drawKeypoints() 函数主要包含五个参数:
# image: 原始图片
# keypoints:从原图中获得的关键点,这也是画图时所用到的数据
# outputimage:输出
# color:颜色设置,通过修改(b,g,r)的值,更改画笔的颜色,b=蓝色,g=绿色,r=红色。
# flags:绘图功能的标识设置,标识如下:
# cv2.DRAW_MATCHES_FLAGS_DEFAULT 默认值
# cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS
# cv2.DRAW_MATCHES_FLAGS_DRAW_OVER_OUTIMG
# cv2.DRAW_MATCHES_FLAGS_NOT_DRAW_SINGLE_POINTS
img = cv2.drawKeypoints(image=img, outImage=img, keypoints = keypoints, flags=cv2.DRAW_MATCHES_FLAGS_DEFAULT, color = (51, 163, 236))
# 显示图片
cv2.imshow('sift_keypoints', img)
while (True):
if cv2.waitKey(120) & 0xff == ord("q"):
break
cv2.destroyAllWindows()
运行代码,结果如图所示:

除了SIFT算法检测之外,还有SURF特征检测算法,比SIFT算法快,并吸收了SIFT算法的思想。SURF采用Hessian算法检测关键点,而SURF是提取特征,这个与SIFT很像。Opencv的SURF类是Hessian算法和SURF算法组合。我们根据SIFT的代码进行修改,代码如下:
import cv2
# 读取图片并灰度处理
imgpath = 'varese.jpg'
img = cv2.imread(imgpath)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 创建SURF对象,对象参数float(4000)为阈值,阈值越高,识别的特征越小。
sift = cv2.xfeatures2d.SURF_create(float(4000))
# 将图片进行SURF计算,并找出角点keypoints,keypoints是检测关键点
# descriptor是描述符,这是图像一种表示方式,可以比较两个图像的关键点描述符,可作为特征匹配的一种方法。
keypoints, descriptor = sift.detectAndCompute(gray, None)
# cv2.drawKeypoints() 函数主要包含五个参数:
# image: 原始图片
# keypoints:从原图中获得的关键点,这也是画图时所用到的数据
# outputimage:输出
# color:颜色设置,通过修改(b,g,r)的值,更改画笔的颜色,b=蓝色,g=绿色,r=红色。
# flags:绘图功能的标识设置,标识如下:
# cv2.DRAW_MATCHES_FLAGS_DEFAULT 默认值
# cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS
# cv2.DRAW_MATCHES_FLAGS_DRAW_OVER_OUTIMG
# cv2.DRAW_MATCHES_FLAGS_NOT_DRAW_SINGLE_POINTS
img = cv2.drawKeypoints(image=img, outImage=img, keypoints = keypoints, flags=cv2.DRAW_MATCHES_FLAGS_DEFAULT, color = (51, 163, 236))
# 显示图片
cv2.imshow('sift_keypoints', img)
while (True):
if cv2.waitKey(120) & 0xff == ord("q"):
break
cv2.destroyAllWindows()
上述代码我们只修改sift = cv2.xfeatures2d.SURF_create(float(4000))即可实现SURF特征检测算法。运行结果如图所示:

对比SURF和SIFT算法,ORB算法更处于起步阶段,在2011年才首次发布。但比前两者的速度更快。ORB基于FAST关键点检测和BRIEF的描述符技术相结合,因此我们先了解FAST和BRIEF。
FAST:特征检测算法。
BRIEF:只是一个描述符,这是图像一种表示方式,可以比较两个图像的关键点描述符,可作为特征匹配的一种方法。
暴力匹配:比较两个描述符并产生匹配结果。
在上述的例子中,我们只是将检测的关键点进行勾画,在这例子中,将使用ORB检测关键点之外,还将两图进行匹配,匹配的图像如下:
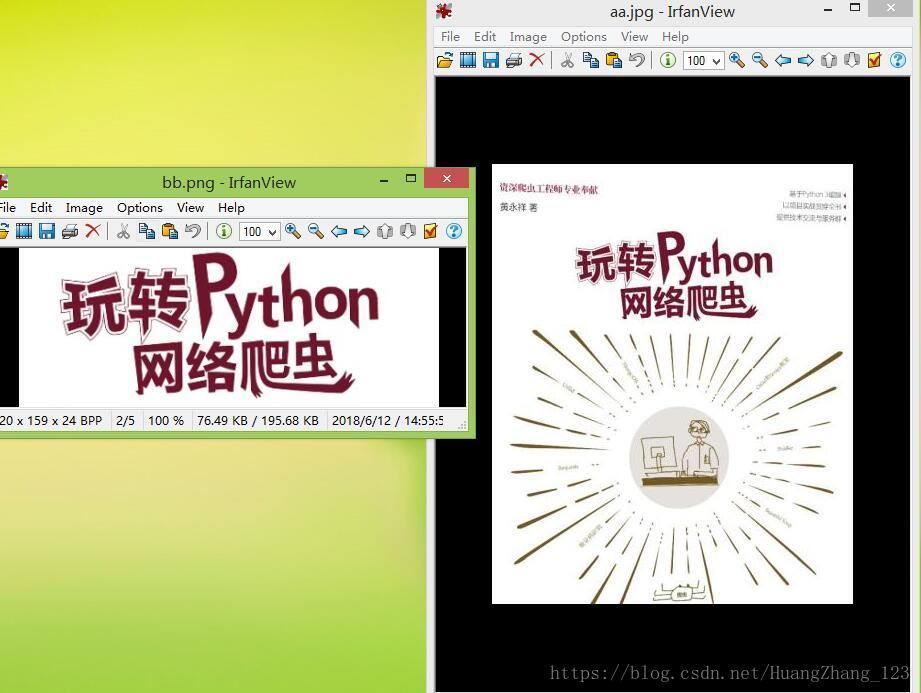
实现方法:首先分别对两图进行ORB处理,然后将两图的关键点进行暴力匹配。具体代码如下:
# ORB算法实现特征检测+暴力匹配
import numpy as np
import cv2
from matplotlib import pyplot as plt
# 读取图片内容
img1 = cv2.imread('aa.jpg',0)
img2 = cv2.imread('bb.png',0)
# 使用ORB特征检测器和描述符,计算关键点和描述符
orb = cv2.ORB_create()
kp1, des1 = orb.detectAndCompute(img1,None)
kp2, des2 = orb.detectAndCompute(img2,None)
# 暴力匹配BFMatcher,遍历描述符,确定描述符是否匹配,然后计算匹配距离并排序
# BFMatcher函数参数:
# normType:NORM_L1, NORM_L2, NORM_HAMMING, NORM_HAMMING2。
# NORM_L1和NORM_L2是SIFT和SURF描述符的优先选择,NORM_HAMMING和NORM_HAMMING2是用于ORB算法
bf = cv2.BFMatcher(normType=cv2.NORM_HAMMING, crossCheck=True)
matches = bf.match(des1,des2)
matches = sorted(matches, key = lambda x:x.distance)
# matches是DMatch对象,具有以下属性:
# DMatch.distance - 描述符之间的距离。 越低越好。
# DMatch.trainIdx - 训练描述符中描述符的索引
# DMatch.queryIdx - 查询描述符中描述符的索引
# DMatch.imgIdx - 训练图像的索引。
# 使用plt将两个图像的匹配结果显示出来
img3 = cv2.drawMatches(img1=img1,keypoints1=kp1,img2=img2,keypoints2=kp2, matches1to2=matches, outImg=img2, flags=2)
plt.imshow(img3),plt.show()
运行结果如图所示:
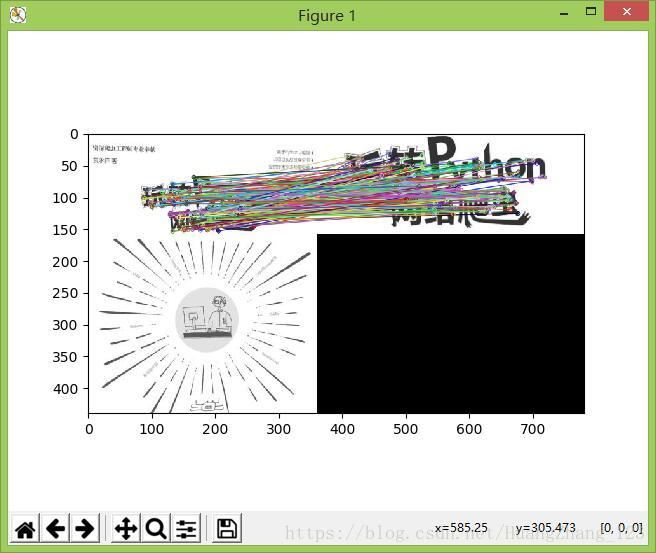
# SURF和SIFT算法+暴力匹配
暴力匹配BFMatcher是一种匹配方法,只要提供两个关键点即可实现匹配。若将上述例子改为SURF和SIFT算法,只需修改以下代码:
将orb = cv2.ORB_create()改为 orb = cv2.xfeatures2d.SURF_create(float(4000)) 将bf = cv2.BFMatcher(normType=cv2.NORM_HAMMING, crossCheck=True)改为 bf = cv2.BFMatcher(normType=cv2.NORM_L1, crossCheck=True)
# 获取匹配关键点的坐标位置
在上述例子中,matches是DMatch对象,DMatch是以列表的形式表示,每个元素代表两图能匹配得上的点。如果想获取某个点的坐标位置,在上述例子添加以下代码:
# 由于匹配顺序是:matches = bf.match(des1,des2),先des1后des2。
# 因此,kp1的索引由DMatch对象属性为queryIdx决定,kp2的索引由DMatch对象属性为trainIdx决定
# 获取aa.jpg的关键点位置
x,y = kp1[matches[0].queryIdx].pt
cv2.rectangle(img1, (int(x),int(y)), (int(x) + 5, int(y) + 5), (0, 255, 0), 2)
cv2.imshow('a', img1)
# 获取bb.png的关键点位置
x,y = kp2[matches[0].trainIdx].pt
cv2.rectangle(img2, (int(x1),int(y1)), (int(x1) + 5, int(y1) + 5), (0, 255, 0), 2)
cv2.imshow('b', img2)
# 使用plt将两个图像的第一个匹配结果显示出来
img3 = cv2.drawMatches(img1=img1,keypoints1=kp1,img2=img2,keypoints2=kp2, matches1to2=matches[:1], outImg=img2, flags=2)
plt.imshow(img3),plt.show()
运行结果如图所示:
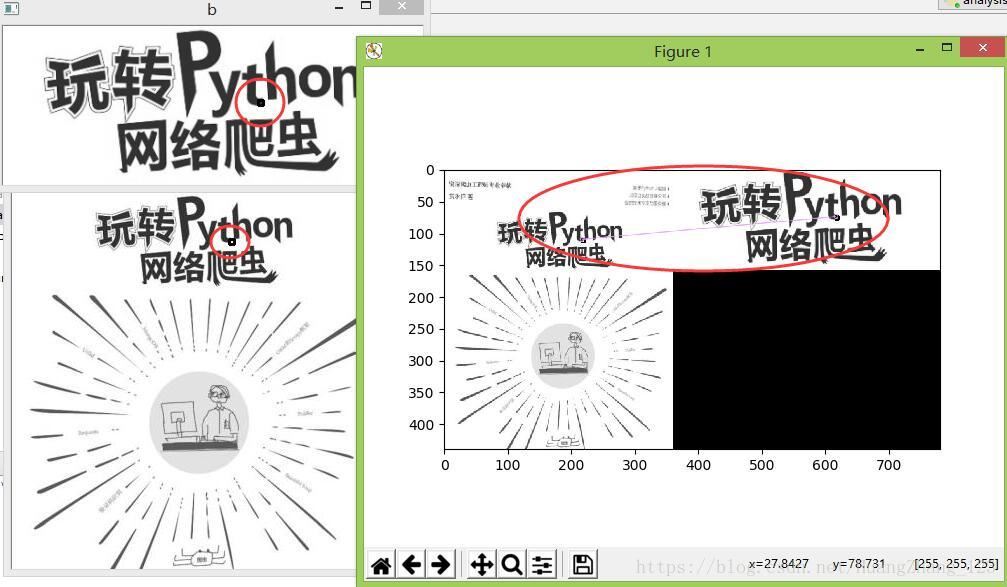
上述讲到的暴力匹配是使用BFMatcher匹配器实现的,然后由match函数实现匹配。接下来讲解K-最近邻匹配(KNN),并在BFMatcher匹配下实现。在所有机器学习的算法中,KNN可能是最为简单的算法。针对上述例子,改为KNN匹配,实现代码如下:
import numpy as np
import cv2
from matplotlib import pyplot as plt
# 读取图片内容
img1 = cv2.imread('aa.jpg',0)
img2 = cv2.imread('bb.png',0)
# 使用ORB特征检测器和描述符,计算关键点和描述符
orb = cv2.ORB_create()
kp1, des1 = orb.detectAndCompute(img1,None)
kp2, des2 = orb.detectAndCompute(img2,None)
# 暴力匹配BFMatcher,遍历描述符,确定描述符是否匹配,然后计算匹配距离并排序
# BFMatcher函数参数:
# normType:NORM_L1, NORM_L2, NORM_HAMMING, NORM_HAMMING2。
# NORM_L1和NORM_L2是SIFT和SURF描述符的优先选择,NORM_HAMMING和NORM_HAMMING2是用于ORB算法
bf = cv2.BFMatcher(normType=cv2.NORM_HAMMING, crossCheck=True)
# knnMatch 函数参数k是返回符合匹配的个数,暴力匹配match只返回最佳匹配结果。
matches = bf.knnMatch(des1,des2,k=1)
# 使用plt将两个图像的第一个匹配结果显示出来
# 若使用knnMatch进行匹配,则需要使用drawMatchesKnn函数将结果显示
img3 = cv2.drawMatchesKnn(img1=img1,keypoints1=kp1,img2=img2,keypoints2=kp2, matches1to2=matches, outImg=img2, flags=2)
plt.imshow(img3),plt.show()
最后是介绍FLANN匹配,相对暴力匹配BFMatcher来讲,这匹配算法比较准确、快速和使用方便。FLANN具有一种内部机制,可以根据数据本身选择最合适的算法来处理数据集。值得注意的是,FLANN匹配器只能使用SURF和SIFT算法。
FLANN实现方式如下:
import numpy as np
import cv2
from matplotlib import pyplot as plt
queryImage = cv2.imread('aa.jpg',0)
trainingImage = cv2.imread('bb.png',0)
# 只使用SIFT 或 SURF 检测角点
sift = cv2.xfeatures2d.SIFT_create()
# sift = cv2.xfeatures2d.SURF_create(float(4000))
kp1, des1 = sift.detectAndCompute(queryImage,None)
kp2, des2 = sift.detectAndCompute(trainingImage,None)
# 设置FLANN匹配器参数
# algorithm设置可参考https://docs.opencv.org/3.1.0/dc/d8c/namespacecvflann.html
indexParams = dict(algorithm=0, trees=5)
searchParams = dict(checks=50)
# 定义FLANN匹配器
flann = cv2.FlannBasedMatcher(indexParams,searchParams)
# 使用 KNN 算法实现匹配
matches = flann.knnMatch(des1,des2,k=2)
# 根据matches生成相同长度的matchesMask列表,列表元素为[0,0]
matchesMask = [[0,0] for i in range(len(matches))]
# 去除错误匹配
for i,(m,n) in enumerate(matches):
if m.distance < 0.7*n.distance:
matchesMask[i] = [1,0]
# 将图像显示
# matchColor是两图的匹配连接线,连接线与matchesMask相关
# singlePointColor是勾画关键点
drawParams = dict(matchColor = (0,255,0),
singlePointColor = (255,0,0),
matchesMask = matchesMask,
flags = 0)
resultImage = cv2.drawMatchesKnn(queryImage,kp1,trainingImage,kp2,matches,None,**drawParams)
plt.imshow(resultImage,),plt.show()
运行结果如图所示:
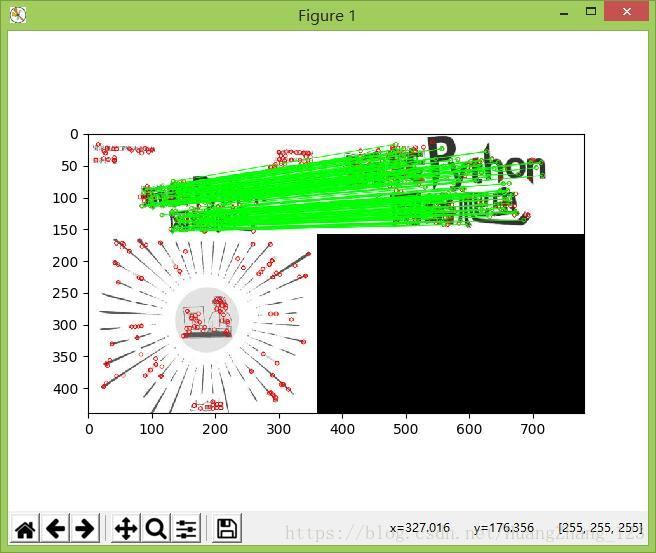
FLANN的单应性匹配,单应性是一个条件,该条件表面当两幅图像中的一副出像投影畸变时,他们还能匹配。FLANN的单应性实现代码如下:
import numpy as np
import cv2
from matplotlib import pyplot as plt
MIN_MATCH_COUNT = 10
img1 = cv2.imread('tattoo_seed.jpg',0)
img2 = cv2.imread('hush.jpg',0)
# 使用SIFT检测角点
sift = cv2.xfeatures2d.SIFT_create()
# 获取关键点和描述符
kp1, des1 = sift.detectAndCompute(img1,None)
kp2, des2 = sift.detectAndCompute(img2,None)
# 定义FLANN匹配器
index_params = dict(algorithm = 1, trees = 5)
search_params = dict(checks = 50)
flann = cv2.FlannBasedMatcher(index_params, search_params)
# 使用KNN算法匹配
matches = flann.knnMatch(des1,des2,k=2)
# 去除错误匹配
good = []
for m,n in matches:
if m.distance < 0.7*n.distance:
good.append(m)
# 单应性
if len(good)>MIN_MATCH_COUNT:
# 改变数组的表现形式,不改变数据内容,数据内容是每个关键点的坐标位置
src_pts = np.float32([ kp1[m.queryIdx].pt for m in good ]).reshape(-1,1,2)
dst_pts = np.float32([ kp2[m.trainIdx].pt for m in good ]).reshape(-1,1,2)
# findHomography 函数是计算变换矩阵
# 参数cv2.RANSAC是使用RANSAC算法寻找一个最佳单应性矩阵H,即返回值M
# 返回值:M 为变换矩阵,mask是掩模
M, mask = cv2.findHomography(src_pts, dst_pts, cv2.RANSAC,5.0)
# ravel方法将数据降维处理,最后并转换成列表格式
matchesMask = mask.ravel().tolist()
# 获取img1的图像尺寸
h,w = img1.shape
# pts是图像img1的四个顶点
pts = np.float32([[0,0],[0,h-1],[w-1,h-1],[w-1,0]]).reshape(-1,1,2)
# 计算变换后的四个顶点坐标位置
dst = cv2.perspectiveTransform(pts,M)
# 根据四个顶点坐标位置在img2图像画出变换后的边框
img2 = cv2.polylines(img2,[np.int32(dst)],True,(255,0,0),3, cv2.LINE_AA)
else:
print("Not enough matches are found - %d/%d") % (len(good),MIN_MATCH_COUNT)
matchesMask = None
# 显示匹配结果
draw_params = dict(matchColor = (0,255,0), # draw matches in green color
singlePointColor = None,
matchesMask = matchesMask, # draw only inliers
flags = 2)
img3 = cv2.drawMatches(img1,kp1,img2,kp2,good,None,**draw_params)
plt.imshow(img3, 'gray'),plt.show()
运行结果如下所示:
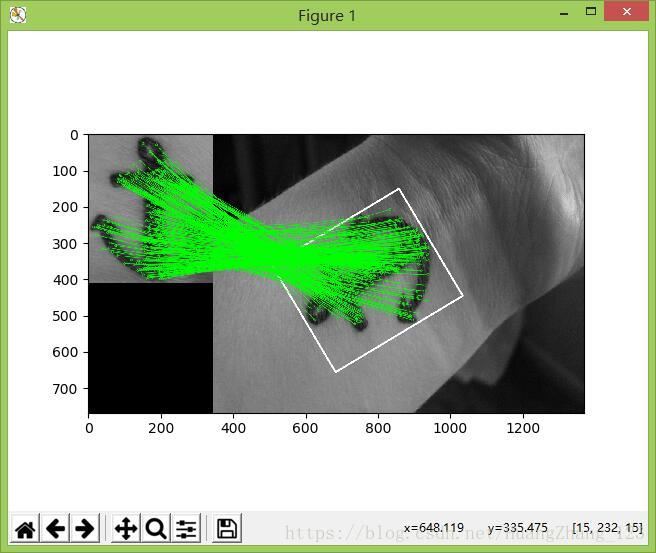
单应性实际应用
从上述的例子可以看到,单应性是在两图片匹配的时候,其中某一图片发生变换处理,变换后图像会呈现一种立体空间的视觉效果,图像发生变换程度称为变换矩阵。以下例子将图像中的书本替换成其他书本,例子中所使用图片如下:
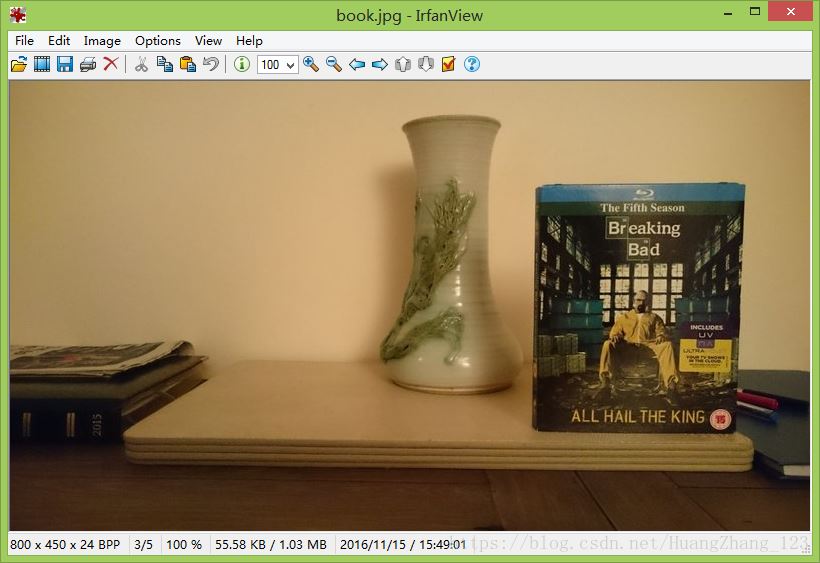


我们根据图1和图2计算变换矩阵,然后通过变换矩阵将图3进行变换,最后将图3加入到图1中,实现图片替换。实现代码如下:
import numpy as np
import cv2
from matplotlib import pyplot as plt
img1 = cv2.imread('logo.jpg',0)
img2 = cv2.imread('book.jpg',0)
# 使用SIFT检测角点
sift = cv2.xfeatures2d.SIFT_create()
# 获取关键点和描述符
kp1, des1 = sift.detectAndCompute(img1,None)
kp2, des2 = sift.detectAndCompute(img2,None)
# 定义FLANN匹配器
index_params = dict(algorithm = 1, trees = 5)
search_params = dict(checks = 50)
flann = cv2.FlannBasedMatcher(index_params, search_params)
# 使用KNN算法匹配
matches = flann.knnMatch(des1,des2,k=2)
# 去除错误匹配
good = []
for m,n in matches:
if m.distance < 0.7*n.distance:
good.append(m)
# 单应性实际应用
# 改变数组的表现形式,不改变数据内容,数据内容是每个关键点的坐标位置
src_pts = np.float32([ kp1[m.queryIdx].pt for m in good ]).reshape(-1,1,2)
dst_pts = np.float32([ kp2[m.trainIdx].pt for m in good ]).reshape(-1,1,2)
# findHomography 函数是计算变换矩阵
# 参数cv2.RANSAC是使用RANSAC算法寻找一个最佳单应性矩阵H,即返回值M
# 返回值:M 为变换矩阵,mask是掩模
M, mask = cv2.findHomography(src_pts, dst_pts, cv2.RANSAC,5.0)
# 获取img1的图像尺寸
h,w = img1.shape
# pts是图像img1的四个顶点
pts = np.float32([[0,0],[0,h-1],[w-1,h-1],[w-1,0]]).reshape(-1,1,2)
# 计算变换后的四个顶点坐标位置
dst = cv2.perspectiveTransform(pts,M)
# 图片替换
img3 = cv2.imread('aa.png',0)
# 降维处理
b = np.int32(dst).reshape(4, 2)
x,y = img2.shape
# 根据变换矩阵将图像img3进行变换处理
res = cv2.warpPerspective(img3, M, (y,x))
img_temp = img2.copy()
# 将图像img2的替换区域进行填充处理
cv2.fillConvexPoly(img_temp, b, 0)
# 将变换后的img3图像替换到图像img2
cv2.imshow('bb',img_temp)
res = img_temp + res
cv2.imshow('aa',res)
plt.imshow(res),plt.show()
运行结果如图所示:
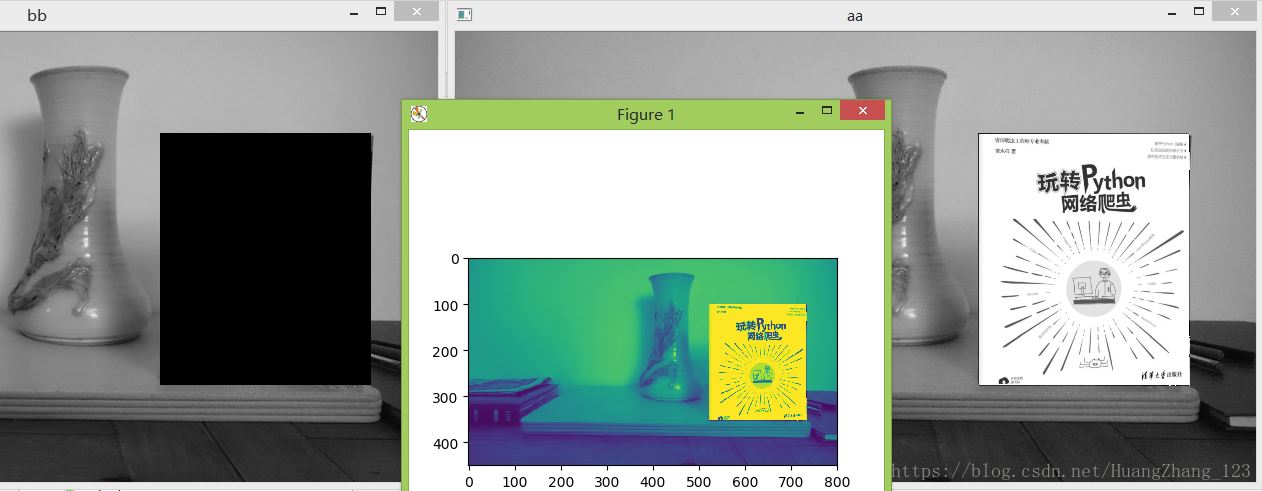
从结果可以看到,替换后的图像周边出现黑色线条,这是正常的现象。在上图最左边的图bb可以看到,黑色区域是由图1和图2检测匹配所得的结果,如果匹配结果会存在一定的误差,这个误差是由多个因素所导致的。
在实际中,我们根据一张图片在众多的图片中查找匹配率最高的图片。如果按照上面的例子,也可以实现,但每次匹配时都需要重新检测图片的特征数据,这样会导致程序运行效率。因此,我们可以将图片的特征数据进行保存,每次匹配时,只需读取特征数据进行匹配即可。我们以下图为例:
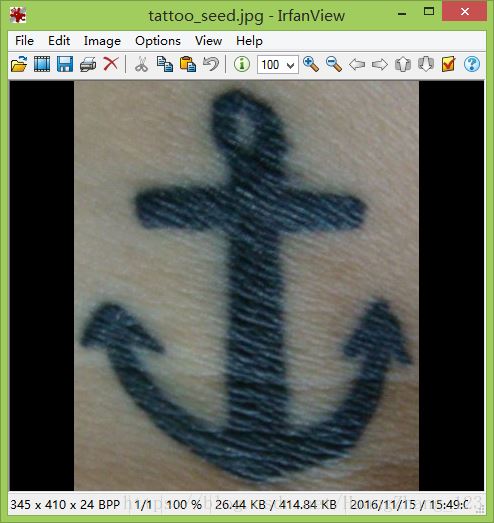

我们根据图1在图2中查找最佳匹配的图片。首先获取图2的全部图片的特征数据,将代码保存在features.py:
import cv2
import numpy as np
from os import walk
from os.path import join
def create_descriptors(folder):
files = []
for (dirpath, dirnames, filenames) in walk(folder):
files.extend(filenames)
for f in files:
if '.jpg' in f:
save_descriptor(folder, f, cv2.xfeatures2d.SIFT_create())
def save_descriptor(folder, image_path, feature_detector):
# 判断图片是否为npy格式
if image_path.endswith("npy"):
return
# 读取图片并检查特征
img = cv2.imread(join(folder,image_path), 0)
keypoints, descriptors = feature_detector.detectAndCompute(img, None)
# 设置文件名并将特征数据保存到npy文件
descriptor_file = image_path.replace("jpg", "npy")
np.save(join(folder, descriptor_file), descriptors)
if __name__=='__main__':
path = 'E:\\anchors'
create_descriptors(path)
运行代码,结果如图所示:
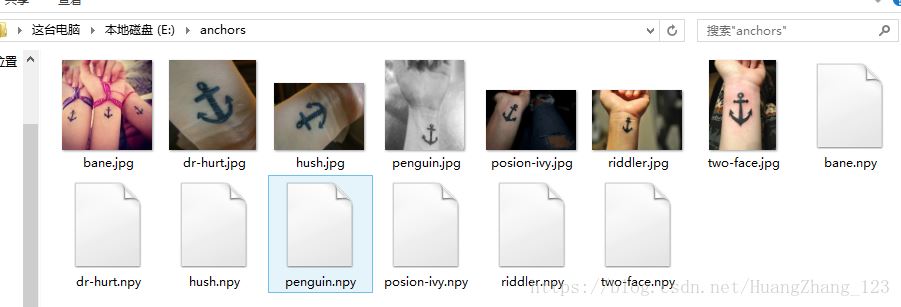
我们将图片的特征数据保存在npy文件。下一步是根据图1与这些特征数据文件进行匹配,从而找出最佳匹配的图片。代码存在matching.py:
from os.path import join
from os import walk
import numpy as np
import cv2
query = cv2.imread('tattoo_seed.jpg', 0)
folder = 'E:\\anchors'
descriptors = []
# 获取特征数据文件名
for (dirpath, dirnames, filenames) in walk(folder):
for f in filenames:
if f.endswith("npy"):
descriptors.append(f)
print(descriptors)
# 使用SIFT算法检查图像的关键点和描述符
sift = cv2.xfeatures2d.SIFT_create()
query_kp, query_ds = sift.detectAndCompute(query, None)
# 创建FLANN匹配器
index_params = dict(algorithm=0, trees=5)
search_params = dict(checks=50)
flann = cv2.FlannBasedMatcher(index_params, search_params)
potential_culprits = {}
for d in descriptors:
# 将图像query与特征数据文件的数据进行匹配
matches = flann.knnMatch(query_ds, np.load(join(folder, d)), k=2)
# 清除错误匹配
good = []
for m, n in matches:
if m.distance < 0.7 * n.distance:
good.append(m)
# 输出每张图片与目标图片的匹配数目
print("img is %s ! matching rate is (%d)" % (d, len(good)))
potential_culprits[d] = len(good)
# 获取最多匹配数目的图片
max_matches = None
potential_suspect = None
for culprit, matches in potential_culprits.items():
if max_matches == None or matches > max_matches:
max_matches = matches
potential_suspect = culprit
print("potential suspect is %s" % potential_suspect.replace("npy", "").upper())
代码运行后,输出结果如图所示:

从输出的结果可以看到,图1与图2的hush.jpg最为匹配,如图所示:
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。