Python jieba库用法及实例解析
1、jieba库基本介绍
(1)、jieba库概述
jieba是优秀的中文分词第三方库
- - 中文文本需要通过分词获得单个的词语
- - jieba是优秀的中文分词第三方库,需要额外安装
- - jieba库提供三种分词模式,最简单只需掌握一个函数
(2)、jieba分词的原理
Jieba分词依靠中文词库
- 利用一个中文词库,确定汉字之间的关联概率
- 汉字间概率大的组成词组,形成分词结果
- 除了分词,用户还可以添加自定义的词组
jieba库使用说明
(1)、jieba分词的三种模式
精确模式、全模式、搜索引擎模式
- - 精确模式:把文本精确的切分开,不存在冗余单词
- - 全模式:把文本中所有可能的词语都扫描出来,有冗余
- - 搜索引擎模式:在精确模式基础上,对长词再次切分
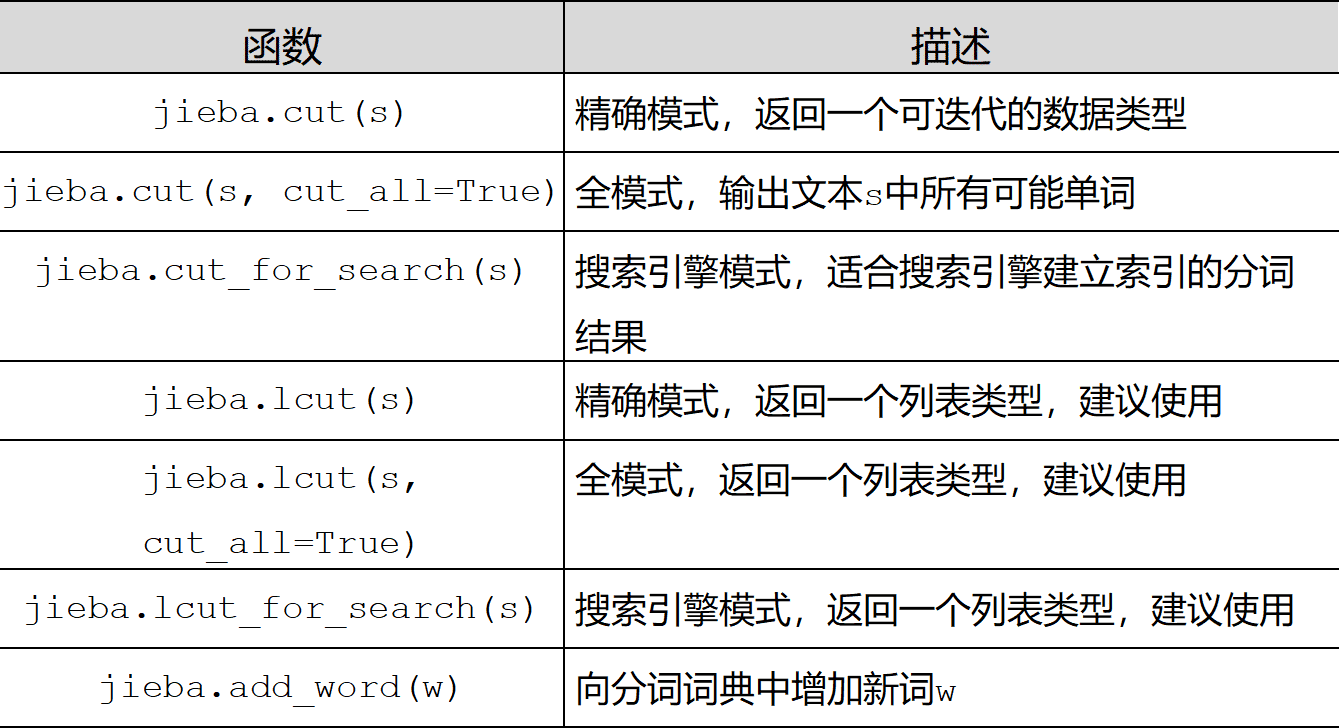
(2)、jieba库常用函数
2.jieba应用实例

3.利用jieba库统计三国演义中任务的出场次数
import jieba
txt = open("D:\\三国演义.txt", "r", encoding='utf-8').read()
words = jieba.lcut(txt) # 使用精确模式对文本进行分词
counts = {} # 通过键值对的形式存储词语及其出现的次数
for word in words:
if len(word) == 1: # 单个词语不计算在内
continue
else:
counts[word] = counts.get(word, 0) + 1 # 遍历所有词语,每出现一次其对应的值加 1
items = list(counts.items())#将键值对转换成列表
items.sort(key=lambda x: x[1], reverse=True) # 根据词语出现的次数进行从大到小排序
for i in range(15):
word, count = items[i]
print("{0:<5}{1:>5}".format(word, count))

统计了次数对多前十五个名词,曹操不愧是一代枭雄,第一名当之无愧,但是我们会发现得到的数据还是需要进一步处理,比如一些无用的词语,一些重复意思的词语。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。