详解Python list和numpy array的存储和读取方法
numpy array存储为.npy
存储:
import numpy as np
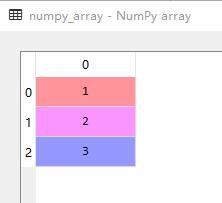
numpy_array = np.array([1,2,3])
np.save('log.npy',numpy_array )
读取:
import numpy as np
numpy_array = np.load('log.npy')
运行结果:
list存储为.txt
存储:
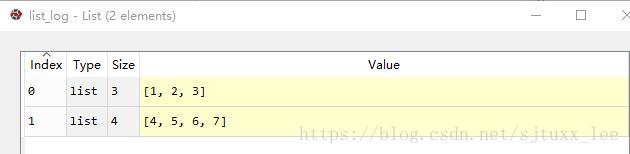
list_log = []
list_log.append([1,2,3])
list_log.append([4,5,6,7])
file= open('log.txt', 'w')
for fp in list_log:
file.write(str(fp))
file.write('\n')
file.close()
这样存储的结果list_log的每一行在txt也是分行的
运行结果:

读取:
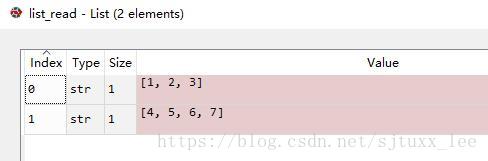
file=open('log.txt', 'r')
list_read = file.readlines()
读出来list_read的结果仍然是一行一行的
运行结果:
.txt文件读取为int
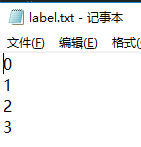
label_path = 'C:/Users/leex/Desktop/label.txt' file = open((label_path),'r') label = [int(x.strip()) for x in file] file.close()
运行结果:
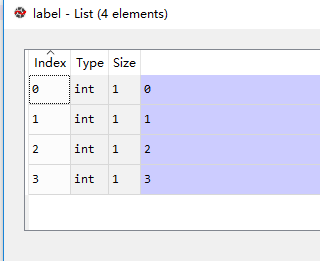
如果不加int(),则读取的为字符串格式
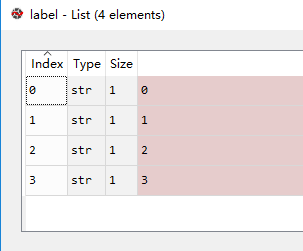
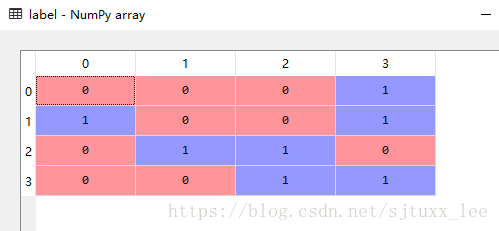
还有一种常见的情况是label是以one-hot编码存储的

可以用np.loadtxt读取
import numpy as np label_path = 'C:/Users/leex/Desktop/label.txt' label = np.loadtxt(label_path, dtype=np.int64)
运行结果
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。
