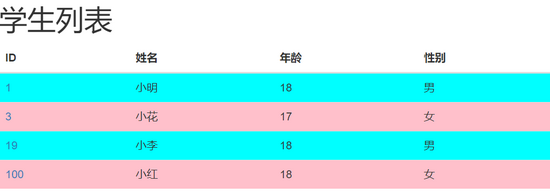
pycharm运行scrapy过程图解
这篇文章主要介绍了pycharm运行scrapy过程图解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下
1.打开pycharm, 点击File>Open找到mySpider项目导入
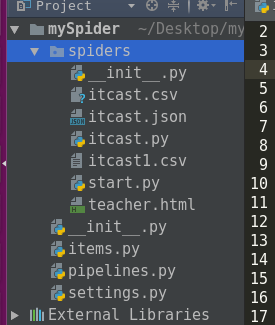
2.打开File>Settings>Project 点击Project Interpreter 右边有个Scrapy, 选中确定.

3.在spiders文件下新建一个启动文件,我命名为start.py
# -*- coding:utf-8 -*-
from scrapy import cmdline
cmdline.execute("scrapy crawl itcast -o itcast1.csv".split())
4.选择configuration路径, 如图下拉点击Edit Configuration, 选择运行的start.py脚本
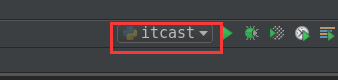
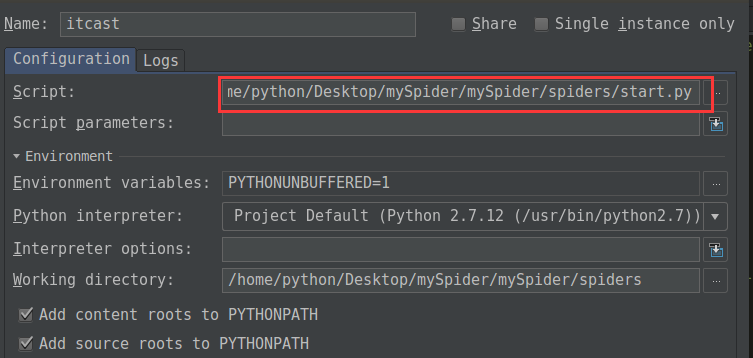
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。