numpy实现神经网络反向传播算法的步骤
一、任务
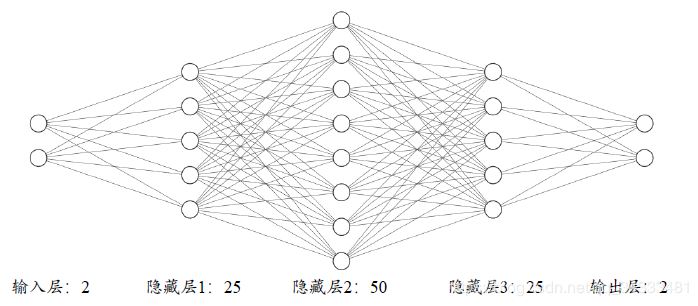
实现一个4 层的全连接网络实现二分类任务,网络输入节点数为2,隐藏层的节点数设计为:25,50,25,输出层2 个节点,分别表示属于类别1 的概率和类别2 的概率,如图所示。我们并没有采用Softmax 函数将网络输出概率值之和进行约束,而是直接利用均方差误差函数计算与One-hot 编码的真实标签之间的误差,所有的网络激活函数全部采用Sigmoid 函数,这些设计都是为了能直接利用梯度推导公式。
二、数据集
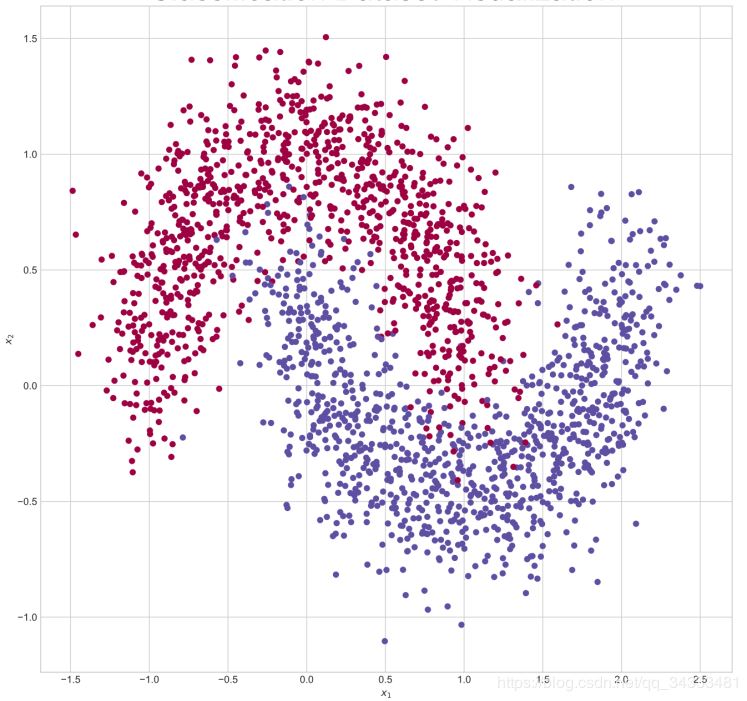
通过scikit-learn 库提供的便捷工具生成2000 个线性不可分的2 分类数据集,数据的特征长度为2,采样出的数据分布如图 所示,所有的红色点为一类,所有的蓝色点为一类,可以看到数据的分布呈月牙状,并且是是线性不可分的,无法用线性网络获得较好效果。为了测试网络的性能,按照7: 3比例切分训练集和测试集,其中2000 ∗ 0 3 =600个样本点用于测试,不参与训练,剩下的1400 个点用于网络的训练。
import matplotlib.pyplot as plt
import seaborn as sns #要注意的是一旦导入了seaborn,matplotlib的默认作图风格就会被覆盖成seaborn的格式
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split
N_SAMPLES = 2000 # 采样点数
TEST_SIZE = 0.3 # 测试数量比率
# 利用工具函数直接生成数据集
X, y = make_moons(n_samples = N_SAMPLES, noise=0.2, random_state=100)
# 将2000 个点按着7:3 分割为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=TEST_SIZE, random_state=42)
print(X.shape, y.shape)
# 绘制数据集的分布,X 为2D 坐标,y 为数据点的标签
def make_plot(X, y, plot_name, file_name=None, XX=None, YY=None, preds=None,dark=False):
if (dark):
plt.style.use('dark_background')
else:
sns.set_style("whitegrid")
plt.figure(figsize=(16,12))
axes = plt.gca()
axes.set(xlabel="$x_1$", ylabel="$x_2$")
plt.title(plot_name, fontsize=30)
plt.subplots_adjust(left=0.20)
plt.subplots_adjust(right=0.80)
if(XX is not None and YY is not None and preds is not None):
plt.contourf(XX, YY, preds.reshape(XX.shape), 25, alpha = 1,cmap=plt.cm.Spectral)
plt.contour(XX, YY, preds.reshape(XX.shape), levels=[.5],cmap="Greys", vmin=0, vmax=.6)
# 绘制散点图,根据标签区分颜色
plt.scatter(X[:, 0], X[:, 1], c=y.ravel(), s=40, cmap=plt.cm.Spectral,edgecolors='none')
plt.savefig('dataset.svg')
plt.close()
# 调用make_plot 函数绘制数据的分布,其中X 为2D 坐标,y 为标签
make_plot(X, y, "Classification Dataset Visualization ")
plt.show()
三、网络层
通过新建类Layer 实现一个网络层,需要传入网络层的数据节点数,输出节点数,激活函数类型等参数,权值weights 和偏置张量bias 在初始化时根据输入、输出节点数自动生成并初始化:
class Layer:
# 全连接网络层
def __init__(self, n_input, n_neurons, activation=None, weights=None,
bias=None):
"""
:param int n_input: 输入节点数
:param int n_neurons: 输出节点数
:param str activation: 激活函数类型
:param weights: 权值张量,默认类内部生成
:param bias: 偏置,默认类内部生成
"""
# 通过正态分布初始化网络权值,初始化非常重要,不合适的初始化将导致网络不收敛
self.weights = weights if weights is not None else
np.random.randn(n_input, n_neurons) * np.sqrt(1 / n_neurons)
self.bias = bias if bias is not None else np.random.rand(n_neurons) *0.1
self.activation = activation # 激活函数类型,如'sigmoid'
self.last_activation = None # 激活函数的输出值o
self.error = None # 用于计算当前层的delta 变量的中间变量
self.delta = None # 记录当前层的delta 变量,用于计算梯度
def activate(self, x):
# 前向传播
r = np.dot(x, self.weights) + self.bias # X@W+b
# 通过激活函数,得到全连接层的输出o
self.last_activation = self._apply_activation(r)
return self.last_activation
# 其中self._apply_activation 实现了不同的激活函数的前向计算过程:
def _apply_activation(self, r):
# 计算激活函数的输出
if self.activation is None:
return r # 无激活函数,直接返回
# ReLU 激活函数
elif self.activation == 'relu':
return np.maximum(r, 0)
# tanh
elif self.activation == 'tanh':
return np.tanh(r)
# sigmoid
elif self.activation == 'sigmoid':
return 1 / (1 + np.exp(-r))
return r
# 针对于不同的激活函数,它们的导数计算实现如下:
def apply_activation_derivative(self, r):
# 计算激活函数的导数
# 无激活函数,导数为1
if self.activation is None:
return np.ones_like(r)
# ReLU 函数的导数实现
elif self.activation == 'relu':
grad = np.array(r, copy=True)
grad[r > 0] = 1.
grad[r <= 0] = 0.
return grad
# tanh 函数的导数实现
elif self.activation == 'tanh':
return 1 - r ** 2
# Sigmoid 函数的导数实现
elif self.activation == 'sigmoid':
return r * (1 - r)
return r
四、网络模型
完成单层网络类后,再实现网络模型的类NeuralNetwork,它内部维护各层的网络层Layer 类对象,可以通过add_layer 函数追加网络层,实现如下:
class NeuralNetwork:
# 神经网络大类
def __init__(self):
self._layers = [] # 网络层对象列表
def add_layer(self, layer):
# 追加网络层
self._layers.append(layer)
# 网络的前向传播只需要循环调用个网络层对象的前向计算函数即可
def feed_forward(self, X):
# 前向传播
for layer in self._layers:
# 依次通过各个网络层
X = layer.activate(X)
return X
#网络模型的反向传播实现稍复杂,需要从最末层开始,计算每层的𝛿变量,根据我们
#推导的梯度公式,将计算出的𝛿变量存储在Layer类的delta变量中
# 因此,在backpropagation 函数中,反向计算每层的𝛿变量,并根据梯度公式计算每层参数的梯度值,
# 按着梯度下降算法完成一次参数的更新。
def backpropagation(self, X, y, learning_rate):
# 反向传播算法实现
# 前向计算,得到输出值
output = self.feed_forward(X)
for i in reversed(range(len(self._layers))): # 反向循环
layer = self._layers[i] # 得到当前层对象
# 如果是输出层
if layer == self._layers[-1]: # 对于输出层
layer.error = y - output # 计算2 分类任务的均方差的导数
# 关键步骤:计算最后一层的delta,参考输出层的梯度公式
layer.delta = layer.error * layer.apply_activation_derivative(output)
else: # 如果是隐藏层
next_layer = self._layers[i + 1] # 得到下一层对象
layer.error = np.dot(next_layer.weights, next_layer.delta)
# 关键步骤:计算隐藏层的delta,参考隐藏层的梯度公式
layer.delta = layer.error * layer.apply_activation_derivative(layer.last_activation)
# 在反向计算完每层的𝛿变量后,只需要按着式计算每层的梯度,并更新网络参数即可。
# 由于代码中的delta 计算的是−𝛿,因此更新时使用了加号。
# 循环更新权值
for i in range(len(self._layers)):
layer = self._layers[i]
# o_i 为上一网络层的输出
o_i = np.atleast_2d(X if i == 0 else self._layers[i-1].last_activation)
# 梯度下降算法,delta 是公式中的负数,故这里用加号
layer.weights += layer.delta * o_i.T * learning_rate
def train(self, X_train, X_test, y_train, y_test, learning_rate,max_epochs):
# 网络训练函数
# one-hot 编码
y_onehot = np.zeros((y_train.shape[0], 2))
y_onehot[np.arange(y_train.shape[0]), y_train] = 1
mses = []
for i in range(max_epochs): # 训练1000 个epoch
for j in range(len(X_train)): # 一次训练一个样本
self.backpropagation(X_train[j], y_onehot[j], learning_rate)
if i % 10 == 0:
# 打印出MSE Loss
mse = np.mean(np.square(y_onehot - self.feed_forward(X_train)))
mses.append(mse)
print('Epoch: #%s, MSE: %f' % (i, float(mse)))
# 统计并打印准确率
print('Accuracy: %.2f%%' % (self.accuracy(self.predict(X_test),y_test.flatten()) * 100))
return mses
def accuracy(self,y_pre,y_true):
return np.mean((np.argmax(y_pre, axis=1) == y_true))
def predict(self,X_test):
return self.feed_forward(X_test)
五、实例化NeuralNetwork类,进行训练
nn = NeuralNetwork() # 实例化网络类 nn.add_layer(Layer(2, 25, 'sigmoid')) # 隐藏层1, 2=>25 nn.add_layer(Layer(25, 50, 'sigmoid')) # 隐藏层2, 25=>50 nn.add_layer(Layer(50, 25, 'sigmoid')) # 隐藏层3, 50=>25 nn.add_layer(Layer(25, 2, 'sigmoid')) # 输出层, 25=>2 learning_rate = 0.01 max_epochs = 1000 nn.train(X_train, X_test, y_train, y_test, learning_rate,max_epochs)
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。