pandas-resample按时间聚合实例
如下所示:
import pandas as pd
#如果需要的话,需将df中的date列转为datetime
df.date = pd.to_datetime(df.date,format="%Y%m%d")
#将改好格式的date列,设置为df的index
df.set_index('date',drop=True)
#按年来提数据 (因为此时的datetime已经为index了,可以直接[]取行内容)
df['2018']
df['2018':'2021']
#按月来提数据
df['2018-01']
df['2018-01':'2018-05']
#按天来提出数据
df['2018-05-24':'2018-09-27']
#按日期汇总数据
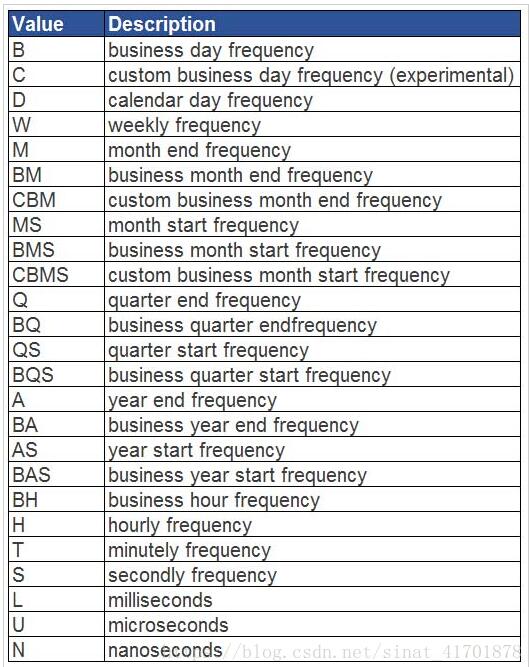
#将数据以W星期,M月,Q季度,QS季度的开始第一天开始,A年,10A十年,10AS十年聚合日期第一天开始.的形式进行聚合
df.resample('W').sum()
df.resample('M').sum()
#具体某列的数据聚合
df.price.resample('W').sum().fillna(0) #星期聚合,以0填充NaN值
#某两列
df[['price','num']].resample('W').sum().fillna(0)
#某个时间段内,以W聚合,
df["2018-5":"2018-9"].resample("M").sum().fillna(0)
还有以下方式聚合
以上这篇pandas-resample按时间聚合实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。