python垃圾回收机制(GC)原理解析
这篇文章主要介绍了python垃圾回收机制(GC)原理解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下
今天想跟大家分享的是关于python的垃圾回收机制,虽然本人这会对该机制没有很深入的了解, 但是本着热爱分享的原则,还是囫囵吞枣地坐下记录分享吧, 万一分享的过程中开窍了呢.哈哈哈.
首先还是做一下概述吧: 我们都知道, 在做python的语言编程中, 相较于java, c++, 我们似乎很少去考虑到去做垃圾回收,内存释放的工作, 其实是python内部已经做了相应的回收机制, 不用我们自己操心去做内存释放.但是还是有必要了解一下.可以更加深入的了解python这门优美的语言的魅力.
一、概述:
python的GC模块主要运用了“引用计数(reference counting)”来跟踪和回收垃圾。在引用计数的基础上,还可以通过标记清除(mark and sweep)解决容器(这里的容器值指的不是docker,而是数组,字典,元组这样的对象)对象可能产生的循环引用的问题。通过“分代回收(generation collection)”以空间换取时间来进一步提高垃圾回收的效率。
二、垃圾回收三种机制
1、引用计数
在Python中,大多数对象的生命周期都是通过对象的引用计数来管理的, 广义上讲,它也是一种垃圾回收机制,而且是一种最直观最简单的垃圾回收机制。
原理:当一个对象被创建引用或者被复制的时候,对象的引用计数会加一,当一个对象的引用被销毁时,对象的引用计数会减一,当对象的引用计数减为0的时候,就意味着对象已经没有被任何人使用了,可以将其所占用的内存释放了。
虽然引用计数必须在每次分配和释放内存的时候加入管理引用计数的这个动作,然而与其他主流垃圾收集机制相比, 最大的一个优点是实时性, 及任何内存,一旦没有指向他的引用,就会立即被回收,其他的垃圾回收机制必须在某种特殊条件下(内存分配失败)才能进行无效内存的回收。
执行效率问题: 引用计数机制带来的维护引用计数带来的额外操作与python运行中所运行的内存分配和释放,引用赋值的次数是成正比的。相比其他机制,比如“标记-清除”,“停止-复制”,是一个弱点,因为这些技术所带来的操作基本上只是与待回收的数量有关。
引用计数还存在的一个致命的弱点是循环引用,这使得垃圾回收机制从来没有将引用计数包含在内。这就需要我们用新的方法了, 即标记清除。
2、标记清除
标记清除主要是用来解决循环引用产生的问题的,循环引用只会在容器对象中才会产生,比如数组、字典、元组等,首先是为了追踪对象,需要每个容器对象维护两个额外的指针,用来将容器对象组成一个链表,指针分别指向前后两个容器对象,这样就可以将对象的循环引用环摘除,就可以得出两个对象的有效计数。
问题说明:
循环引用可以使得一组对象的引用计数不是0, 然而这些对象实际上并没有被外部对象所引用,这就意味着不会再有人使用这组对象, 应该回收这组对象所占用的内存空间,然而由于相互引用的存在,每一个对象的引用计数不为0,因为这些对象所占用的内存永远不会被释放。比如下面的代码:
a = [1, 2] b = [3, 4] a.append(b) b.append(a) del a del b # B c = [3, 5] d = [2, 4] c.append(d) d.append(c) del c
OKAY,现在就这个做一下解释,这是个集中营, 一个是root object(链表),另一个是unreachable链表。
对于上面的第一组, 在未执行del语句的时候,a,b的引用计数都是2(init + append= 2),但是在DEL执行完毕之后,a,b的引用次数互相减一。a,b陷入循环引用的圈子中,然后标记清除算法开始出来做事,找到其中一端a,开始拆a,b的引用环(我们从a出发,因为它对B有一个引用,则将B的引用计数减一,然后顺着引用到达B,因为B有一个对A的引用,同样将A的引用减一,这样就完成了循环引用对象之间的对象环摘除), 去掉以后发现a,c循环引用变成了0,所以a,b就被处理到unreachable链表中直接被做掉。
对于第二组,简单一看d取环后引用计数还是1,但是a取环后就是0了这时的c已经进入了unreachable的链表中,被判了死刑,但是此时在root表中还有d,d还在引用着c,如果c被搞掉,世界就没有了正义。root链表中的d会被引用检测引用了c,如果c没了,那么b也就凉凉了,所以c又拉回到了root链表中。
解剖这两个链表的原因是现在在unreachable中可能存在被root链表中的对象,直接或者间接引用的对象,这些对象是不能被回收的,一旦在标记的过程中,发现这样的对象就将其移动到root链表中,完成标记后,unreachable链表中剩下的就是名副其实的垃圾对象了,接下来垃圾回收只需要限制在unreachable链表中即可。
3、分代回收
背景:分代回收技术是上个世纪80年代初发展起来的一种垃圾回收机制,经过研究表明:无论使用何总语言开发无论开发的是何种类型,何种规模的程序,都存在这样一点相同之处, 即:一定比例的内存块的生存周期都比较短,通常是几百万条指令的时间,然而剩下的内存块,生存周期比较长,甚至会从一开始直到程序结束。
从前面的“标记-清除”这样的垃圾回收机制来看,这种垃圾收集机制带来的额外操作实际上与系统中总的内存块的数量是相关的,当要回收的内存块越多时,垃圾检测带来的额外操作就越多,而垃圾回收所带来的额外操作就越少,反值则相反。为了提高垃圾的收集效率,采用“空间换时间”的策略。
原理: 将系统红所有内存块根据其存活时间划分为不同的集合每一个集合就称为一个“代”,垃圾收集的频率随着代的存活时间的增大而减少。也即,活的时间越长的对象就越不可能是垃圾,就应该减少对它的垃圾收集频率,衡量的标准就是这个对象经过的垃圾收集次数越多,该对象存活的时间就越长。
例如:
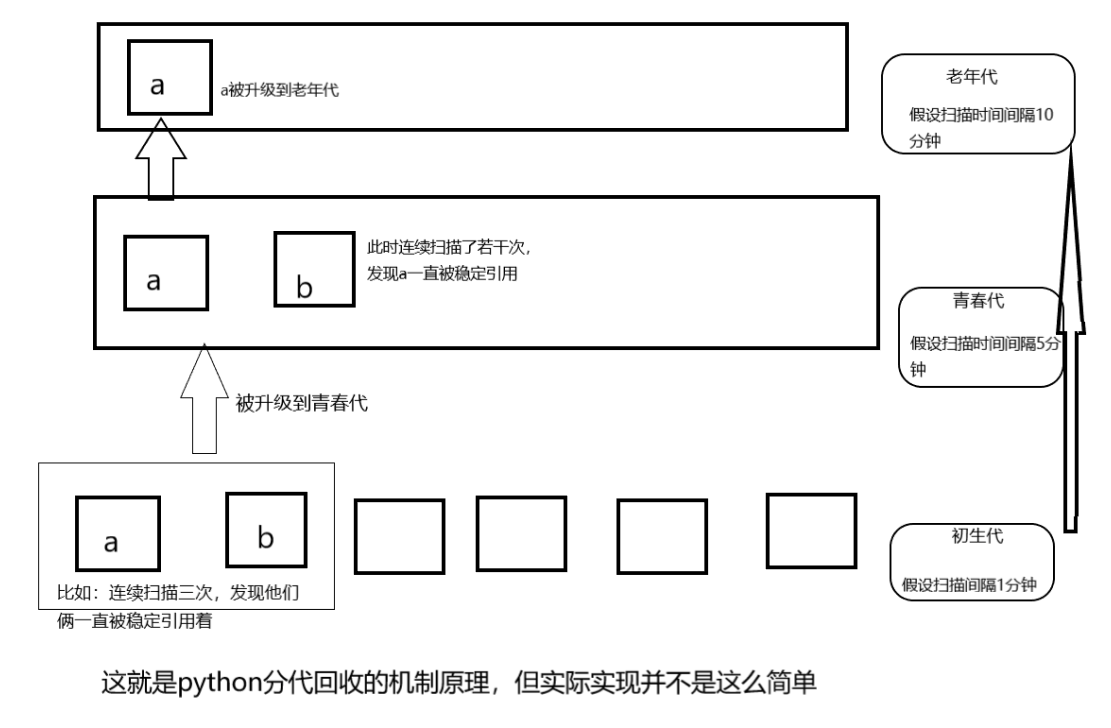
当某些内存块M经过了3次垃圾回收的清洗之后还是存活着的时候,就将内存块M划到一个集合A中去,当垃圾收集开始工作时,大多数情况只是针对集合B进行垃圾回收,而对集合A进行垃圾回收要隔相当长一段时间才进行,这就使得垃圾收集机制要处理的内存少了,效率自然就提高了。这个过程中集合B中的某些内存块由于存活时间长会被转移到A中, 当然A中实际上也存在一些垃圾,这些垃圾回收会因为这种分带机制而延迟。 在python中,一共有三代,也即维护3条链表(generation 0, 1, 2)
- 0代表幼儿对象。
- 1代表青年对象。
- 2代表老年对象。
依据弱代假说(越年轻的越容易死掉)
新生的对象放在0代,对象在0代的第一次垃圾收集机制中活了过来, 那么久将其放到第1代里面了,同理,可能会被放到第2代。GC每代垃圾回收处罚的阈值可以自己设置(目前我不知道怎么设置/苦笑)。
这些就是目前的python的垃圾回收机制了。
下面的是 内存池以及调优手段:
内存池:
python的内存机制呈现金字塔形状,-1, -2层主要由操作系统进行操作。
第0层是C中的malloc, free等内存分配和释放函数进行操作
第一层和第二层是内存池,有python借口函数,PyMem_Malloc函数实现,当对象小于256K时候由该层直接分配内存,
第三层是最上层,也即我们对python对象的直接操作。
调优手段:
1、手动垃圾回收
2、避免循环运用
3、提高垃圾回收阈值
希望上面这些能对大家有所帮助。谢谢支持!!!
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。