pytorch中交叉熵损失(nn.CrossEntropyLoss())的计算过程详解
公式
首先需要了解CrossEntropyLoss的计算过程,交叉熵的函数是这样的:
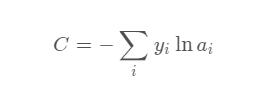
其中,其中yi表示真实的分类结果。这里只给出公式,关于CrossEntropyLoss的其他详细细节请参照其他博文。
测试代码(一维)
import torch
import torch.nn as nn
import math
criterion = nn.CrossEntropyLoss()
output = torch.randn(1, 5, requires_grad=True)
label = torch.empty(1, dtype=torch.long).random_(5)
loss = criterion(output, label)
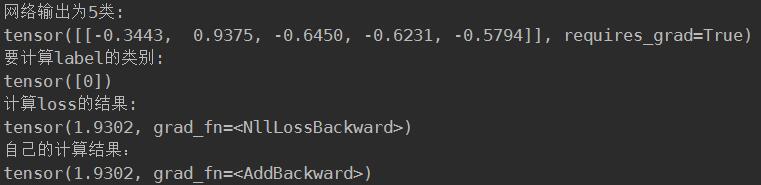
print("网络输出为5类:")
print(output)
print("要计算label的类别:")
print(label)
print("计算loss的结果:")
print(loss)
first = 0
for i in range(1):
first = -output[i][label[i]]
second = 0
for i in range(1):
for j in range(5):
second += math.exp(output[i][j])
res = 0
res = (first + math.log(second))
print("自己的计算结果:")
print(res)

测试代码(多维)
import torch
import torch.nn as nn
import math
criterion = nn.CrossEntropyLoss()
output = torch.randn(3, 5, requires_grad=True)
label = torch.empty(3, dtype=torch.long).random_(5)
loss = criterion(output, label)
print("网络输出为3个5类:")
print(output)
print("要计算loss的类别:")
print(label)
print("计算loss的结果:")
print(loss)
first = [0, 0, 0]
for i in range(3):
first[i] = -output[i][label[i]]
second = [0, 0, 0]
for i in range(3):
for j in range(5):
second[i] += math.exp(output[i][j])
res = 0
for i in range(3):
res += (first[i] + math.log(second[i]))
print("自己的计算结果:")
print(res/3)
nn.CrossEntropyLoss()中的计算方法
注意:在计算CrossEntropyLosss时,真实的label(一个标量)被处理成onehot编码的形式。
在pytorch中,CrossEntropyLoss计算公式为:
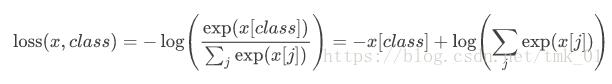
CrossEntropyLoss带权重的计算公式为(默认weight=None):
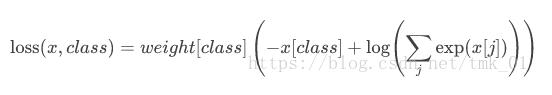
以上这篇pytorch中交叉熵损失(nn.CrossEntropyLoss())的计算过程详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。