tensorflow没有output结点,存储成pb文件的例子
Tensorflow中保存成pb file 需要 使用函数
graph_util.convert_variables_to_constants(sess, sess.graph_def,
output_node_names=[]) []中需要填写你需要保存的结点。如果保存的结点在神经网络中没有被显示定义该怎么办?
例如我使用了tf.contrib.slim或者keras,在tf的高层很多情况下都会这样。
在写神经网络时,只需要简单的一层层传导,一个slim.conv2d层就包含了kernal,bias,activation function,非常的方便,好处是网络结构一目了然,坏处是什么呢?

在尝试保存pb的 output node names时,需要将最后的输出结点保存下来,与这个结点相关的,从输入开始,经过层层传递的嵌套函数或者操作的相关结点,都会被保存,但无效的例如 计算准确率,计算loss等,就可以省略了,因为保存的pb主要是用来做预测的。
在准备查看所有的结点名称并选取保存时,发现scope "local3"里面仅有相关的weights 和biases,这两个是单独存在的,即保存这两个参数并没有任何意义。

那么这时候有两种解决办法:
方法一:
graph_util.convert_variables_to_constants(sess, sess.graph_def, output_node_names=[var.name[:-2] for var in tf.global_variables()])
那么这个的意思是所有的variable的都被保存下来 但函数中要求的是 node name 我们通过 global_variables获得的是 变量名 并不是 节点名
(例如 output:0 就是变量名,又叫tensor name)
output就是 node name了。
在tensorboard中可以一窥究竟
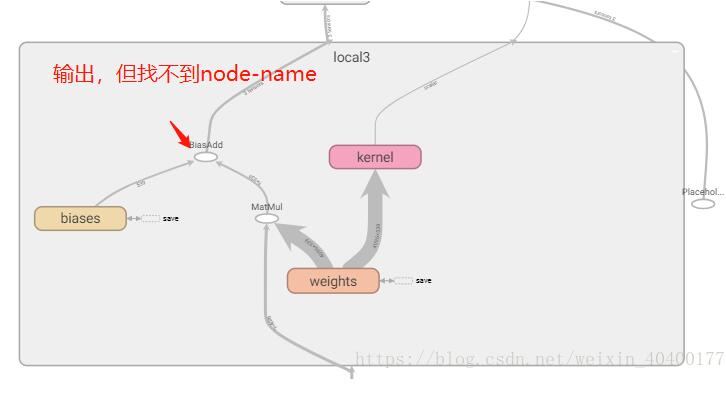
通过这样 也可以将 所有的变量全部保存下来(但是你并不能使用,是因为你的output并没有名字,所以你不可以通过常用的sess.graph.get_tensor_by_name来使用)
方法二:
那就是直接改写神经网络了....当然了还是比较简单的,只要改写最后一个,改写成output即可,tensorflow中无论是 变量、操作op、函数、都可以命名,那么这个地方是一个简单的全连接,仅需要将weights*net(上一层的输出) +bias 即可,我们只要将bias相加的结果命名为 ouput即可:
with tf.name_scope('local3'):
local3_weights = tf.Variable(tf.truncated_normal([4096, self.output_size], stddev=0.1))
local3_bias = tf.Variable(tf.constant(0.1, shape=[self.output_size]))
result = tf.add(tf.matmul(net, local3_weights), local3_bias, name="output")
这样将上述的convert_variables_to_constants中的output_node_names只需要填写一个['output']即可,因为这一个output结点,需要从input开始,将所有的神经网络前向传播的操作和参数全部保存下来,因此保存的结点数量 和 方法一保存的结点数量是一样的(console显示都是 convert 24)。
完整的pb保存为:(我是将ckpt读入进来,然后存成pb的)
from tensorflow.python.platform import gfile
load_ckpt():
path = './data/output/loss1.0/'
print("read from ckpt")
ckpt = tf.train.get_checkpoint_state(path)
saver = tf.train.Saver()
saver.restore(sess, ckpt.model_checkpoint_path)
def write2pb_file():
constant_graph = graph_util.convert_variables_to_constants(sess, sess.graph_def,
output_node_names=["output"])
with tf.gfile.GFile(path+'loss1.0.pb', mode='wb') as f:
f.write(constant_graph.SerializeToString())
print("Model is saved as " + path+'loss1.0.pb')
def main():
load_ckpt()
write2pb_file()
如果是简单的直接保存,那就更简单了。
pb文件的read,很多人会将一个net写成一个类,在引入的时候会将新建这个类,然后读入ckpt文件,这完全没有问题,但是在读取pb时,就会发生问题,因为pb中已经包含了图与参数,引入时会创建一个默认的图,但是net类中自己也会创建一个图,那么这时候你运行程序,参数其实并没有使用.pb的文件。
所以我们不能创建net类,然后直接读入.pb文件,对.pb文件,通过如下代码,获取.pb的graph中的输入和输出。
self.output = self.sess.graph.get_tensor_by_name("output:0")
self.input = self.sess.graph.get_tensor_by_name("images:0")
注意此时要加:0 因为你获取的不再是结点了,而是一个真实的变量,我的理解是,结点相当于一个类,:0是对象,默认初始化值就是对象的初始化。
然后就可以通过self.sess.run(self.output(feed_dict={self.input: your_input})))运行你的网络了!
以上这篇tensorflow没有output结点,存储成pb文件的例子就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。