python 微信好友特征数据分析及可视化
一、背景及研究现状
在我国互联网的发展过程中,PC互联网已日趋饱和,移动互联网却呈现井喷式发展。数据显示,截止2013年底,中国手机网民超过5亿,占比达81%。伴随着移动终端价格的下降及wifi的广泛铺设,移动网民呈现爆发趋势。
微信已经成为连接线上与线下、虚拟与现实、消费与产业的重要工具,它提高了O2O类营销用户的转化率。过去开发软件,程序员常要考虑不同开发环境的语言、设备的适配性和成本。现在,开发者可以在一个“类操作底层”去开发应用,打破了过去受限的开发环境。
二、研究意义及目的
随着宽带无线接入技术和移动终端技术的飞速发展,人们迫切希望能够随时随地乃至在移动过程中都能方便地从互联网获取信息和服务,移动互联网应运而生并迅猛发展。然而,移动互联网在移动终端、接入网络、应用服务、安全与隐私保护等方面还面临着一系列的挑战。其基础理论与关键技术的研究,对于国家信息产业整体发展具有重要的现实意义。
三、研究内容及数据获取
普通用户使用手机扫描二维码并在手机上确认后,wxpy自动从用户的网页版微信获取好友列表,包括好友昵称、所在地区、个性签名、性别等信息。
四、python程序设计
#微信好友特征数据分析及可视化
# 1.导包操作
from wxpy import *
import re
import jieba
import numpy as np
from scipy.misc import imread
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from pylab import mpl
import pandas as pd
mpl.rcParams['font.sans-serif'] = ['SimHei']
from pyecharts.charts import Map
from pyecharts import options as opts
# 2.登录操作
bot = Bot()
# 列举登录账号的所有好友
all_friends = bot.friends()
print(all_friends)
# 获取登录账号所关注的所有的公众号
all_maps = bot.mps()
print("所有好友列表", all_maps)
# 获取当前登录账号的群聊列表
all_groups = bot.groups()
print("所有群聊列表", all_groups)
# 根据好友的备注名称搜索好友
#myfriend = bot.friends().search('许宽')[0]
#print("搜索好友:", myfriend)
# 搜索好友并发送信息
# bot.friends().search('许宽')[0].send('你好呀')
# 向文件传输助手发送信息
bot.file_helper.send("hello")
# 3.显示男女比例
sex_dict = {'male': 0, 'female': 0, "no_set": 0}
for friend in all_friends:
print(friend, friend.sex)
if friend.sex == 1:
sex_dict['male'] += 1
elif friend.sex == 2:
sex_dict['female'] += 1
elif friend.sex == 0:
sex_dict['no_set'] += 1
print(sex_dict)
# 4使用matplotlib可视化
slices = [sex_dict["male"], sex_dict["female"], sex_dict["no_set"]]
activities = ["male", "female", "no_set"]
cols = ["r", "m", "g"]
# startangle:开始绘图的角度,逆时针旋转
# shadow:阴影
# %1.1f%%:格式化字符串,整数部分最小1位,小数点后保留一位,%%:转义字符
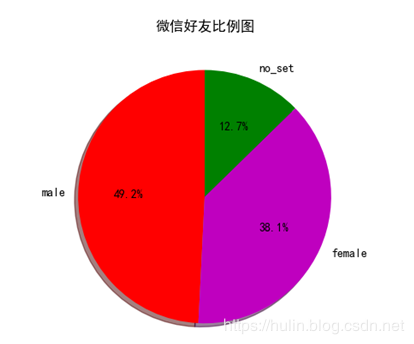
plt.pie(slices, labels=activities, colors=cols, startangle=90, shadow=True, autopct='%1.1f%%')
plt.title("微信好友比例图")
plt.savefig("WeChat_sex.png")
# 统计登录账号好友的各省人数
province_dict = {'河北': 0, '山东': 0, '辽宁': 0, '广西': 0, '吉林': 0,
'甘肃': 0, '青海': 0, '河南': 0, '江苏': 0, '湖北': 0,
'湖南': 0, '江西': 0, '浙江': 0, '广东': 0, '云南': 0,
'福建': 0, '台湾': 0, '海南': 0, '山西': 0, '四川': 0,
'陕西': 0, '贵州': 0, '安徽': 0, '北京': 0, '天津': 0,
'重庆': 0, '上海': 0, '香港': 0, '澳门': 0, '新疆': 0,
'内蒙古': 0, '西藏': 0, '黑龙江': 0, '宁夏': 0}
# 统计省份
for friend in all_friends:
# print(friend.province)
if friend.province in province_dict.keys():
province_dict[friend.province] += 1
print("province_dict")
print(province_dict)
# 为了方便数据呈现,生成JSON Array格式数据
data = []
for key, value in province_dict.items():
data.append({'name': key, 'value': value}) # 在data列表末尾添加一个字典元素
print(data)
data_process = pd.DataFrame(data) # 创建数据框
data_process.columns = ['city', 'popu']
print(data_process)
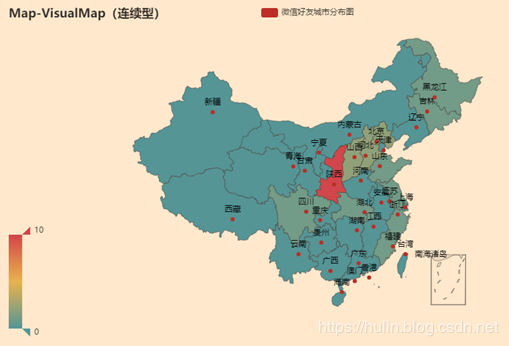
map = Map().add("微信好友城市分布图", [list(z) for z in zip(data_process['city'], data_process['popu'])],
"china").set_global_opts(
title_opts=opts.TitleOpts(title="Map-VisualMap(连续型)"), visualmap_opts=opts.VisualMapOpts(max_=10))
map.render('map.html')
# with...as...语句结束时,自动调用f.close()
# a表示:在文件末尾追加
def write_txt_file(path, txt): # 写文件
with open(path, 'a', encoding='gbk') as f:
return f.write(txt)
# 每次运行程序前,需要删除上一次的文件
# 默认字符编码为GBK
def read_txt_file(path):
with open(path, 'r', encoding='gbk') as f:
return f.read()
# 统计登录账号好友个性签名
for friend in all_friends:
print(friend, friend.signature)
# 对数据进行清洗,将标点符号等对词频率统计造成影响的因素剔除
# [...]:匹配中括号任意一个字符
# r:防止转义
pattern = re.compile(r'[一-龥]+') # 将正则字符串编译成正则表达式对象,以后在后期的匹配中复用
# 对某一个签名进行匹配,只匹配中文汉字,结果是列表
filterdata = re.findall(pattern, friend.signature)
print(filterdata)
write_txt_file('signatures.txt', ''.join(filterdata))
# 读取文件并输出。
content = read_txt_file('signatures.txt')
print(content) # 输出内容,仅汉字
# 输出分词结果,结果为列表
segment = jieba.lcut(content) # 精确模式:不存在冗余数据,适合文本分析
print(segment)
# 生成数据框且有一列元素
word_df = pd.DataFrame({'segment': segment}) # 字典类型
print(word_df)
# index_col=False:第一行不做为索引
# seq=" ":分隔符
# names=['stopword']:列名
# "stopwords.txt":停止词库
stopwords = pd.read_csv("stopwords.txt", index_col=False, sep=" ", names=['stopword'], encoding='gbk')
print(stopwords)
# 查看过滤停止词后的数据框
word_df = word_df[~word_df.segment.isin(stopwords.stopword)]
print("过滤后:")
print(word_df)
# 查看分词的词频
# python中的groupby可以看作是基于行或者是基于index的聚合操作
# agg函数提供基于列的聚合操作,一般与groupby连用
# np.size:numpy库中统计一列中不同值的个数
words_stat = word_df.groupby(by=['segment'])['segment'].agg({"计数": np.size}) # 警告信息
print(words_stat)
# 根据计数这一列降序排列
words_stat = words_stat.reset_index().sort_values(by=["计数"], ascending=False)
print(words_stat)
# 读入背景图片
color_mask = imread("black_mask.png")
# 设置词云属性
wordcloud = WordCloud(font_path="Hiragino.ttf", # 设置字体
background_color="pink", # 设置颜色
max_words=100, # 词云显示的最大词数
mask=color_mask, # 设置背景图片
max_font_size=100 # 字体最大值
)
# 生成词云字典,获取词云最高的前一百词
word_frequence = {x[0]: x[1] for x in words_stat.head(100).values}
print(word_frequence)
# 绘制词云图
wordcloud.generate_from_frequencies(word_frequence)
wordcloud.to_file("wordcloud.png")
# 对图像进行处理
plt.imshow(wordcloud)
plt.axis("off") # 隐藏坐标轴
plt.show()
五、数据分析及可视化
微信好友男女性别比例
微信好友所在省份比例
声明
祖国领土主权神圣不可侵犯!
部分地区未标注,敬请谅解!
微信好友个性签名词云图

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。