Pytorch 搭建分类回归神经网络并用GPU进行加速的例子
分类网络
import torch
import torch.nn.functional as F
from torch.autograd import Variable
import matplotlib.pyplot as plt
# 构造数据
n_data = torch.ones(100, 2)
x0 = torch.normal(3*n_data, 1)
x1 = torch.normal(-3*n_data, 1)
# 标记为y0=0,y1=1两类标签
y0 = torch.zeros(100)
y1 = torch.ones(100)
# 通过.cat连接数据
x = torch.cat((x0, x1), 0).type(torch.FloatTensor)
y = torch.cat((y0, y1), 0).type(torch.LongTensor)
# .cuda()会将Variable数据迁入GPU中
x, y = Variable(x).cuda(), Variable(y).cuda()
# plt.scatter(x.data.cpu().numpy()[:, 0], x.data.cpu().numpy()[:, 1], c=y.data.cpu().numpy(), s=100, lw=0, cmap='RdYlBu')
# plt.show()
# 网络构造方法一
class Net(torch.nn.Module):
def __init__(self, n_feature, n_hidden, n_output):
super(Net, self).__init__()
# 隐藏层的输入和输出
self.hidden1 = torch.nn.Linear(n_feature, n_hidden)
self.hidden2 = torch.nn.Linear(n_hidden, n_hidden)
# 输出层的输入和输出
self.out = torch.nn.Linear(n_hidden, n_output)
def forward(self, x):
x = F.relu(self.hidden2(self.hidden1(x)))
x = self.out(x)
return x
# 初始化一个网络,1个输入层,10个隐藏层,1个输出层
net = Net(2, 10, 2)
# 网络构造方法二
'''
net = torch.nn.Sequential(
torch.nn.Linear(2, 10),
torch.nn.Linear(10, 10),
torch.nn.ReLU(),
torch.nn.Linear(10, 2),
)
'''
# .cuda()将网络迁入GPU中
net.cuda()
# 配置网络优化器
optimizer = torch.optim.SGD(net.parameters(), lr=0.2)
# SGD: torch.optim.SGD(net.parameters(), lr=0.01)
# Momentum: torch.optim.SGD(net.parameters(), lr=0.01, momentum=0.8)
# RMSprop: torch.optim.RMSprop(net.parameters(), lr=0.01, alpha=0.9)
# Adam: torch.optim.Adam(net.parameters(), lr=0.01, betas=(0.9, 0.99))
loss_func = torch.nn.CrossEntropyLoss()
# 动态可视化
plt.ion()
plt.show()
for t in range(300):
print(t)
out = net(x)
loss = loss_func(out, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if t % 5 == 0:
plt.cla()
prediction = torch.max(F.softmax(out, dim=0), 1)[1].cuda()
# GPU中的数据无法被matplotlib利用,需要用.cpu()将数据从GPU中迁出到CPU中
pred_y = prediction.data.cpu().numpy().squeeze()
target_y = y.data.cpu().numpy()
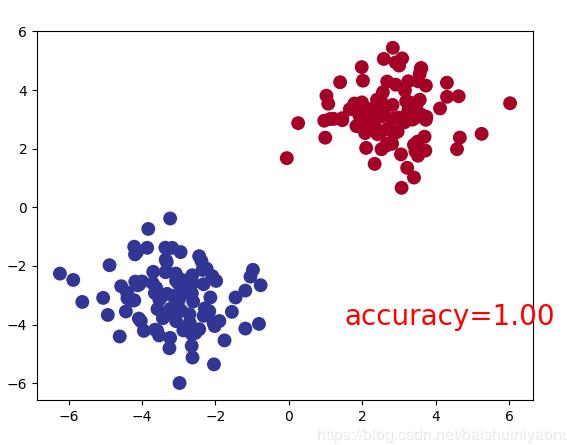
plt.scatter(x.data.cpu().numpy()[:, 0], x.data.cpu().numpy()[:, 1], c=pred_y, s=100, lw=0, cmap='RdYlBu')
accuracy = sum(pred_y == target_y) / 200
plt.text(1.5, -4, 'accuracy=%.2f' % accuracy, fontdict={'size':20, 'color':'red'})
plt.pause(0.1)
plt.ioff()
plt.show()
回归网络
import torch
import torch.nn.functional as F
from torch.autograd import Variable
import matplotlib.pyplot as plt
# 构造数据
x = torch.unsqueeze(torch.linspace(-1,1,100), dim=1)
y = x.pow(2) + 0.2*torch.rand(x.size())
# .cuda()会将Variable数据迁入GPU中
x, y = Variable(x).cuda(), Variable(y).cuda()
# plt.scatter(x.data.numpy(), y.data.numpy())
# plt.show()
# 网络构造方法一
class Net(torch.nn.Module):
def __init__(self, n_feature, n_hidden, n_output):
super(Net, self).__init__()
# 隐藏层的输入和输出
self.hidden = torch.nn.Linear(n_feature, n_hidden)
# 输出层的输入和输出
self.predict = torch.nn.Linear(n_hidden, n_output)
def forward(self, x):
x = F.relu(self.hidden(x))
x = self.predict(x)
return x
# 初始化一个网络,1个输入层,10个隐藏层,1个输出层
net = Net(1, 10, 1)
# 网络构造方法二
'''
net = torch.nn.Sequential(
torch.nn.Linear(1, 10),
torch.nn.ReLU(),
torch.nn.Linear(10, 1),
)
'''
# .cuda()将网络迁入GPU中
net.cuda()
# 配置网络优化器
optimizer = torch.optim.SGD(net.parameters(), lr=0.5)
# SGD: torch.optim.SGD(net.parameters(), lr=0.01)
# Momentum: torch.optim.SGD(net.parameters(), lr=0.01, momentum=0.8)
# RMSprop: torch.optim.RMSprop(net.parameters(), lr=0.01, alpha=0.9)
# Adam: torch.optim.Adam(net.parameters(), lr=0.01, betas=(0.9, 0.99))
loss_func = torch.nn.MSELoss()
# 动态可视化
plt.ion()
plt.show()
for t in range(300):
prediction = net(x)
loss = loss_func(prediction, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if t % 5 == 0 :
plt.cla()
# GPU中的数据无法被matplotlib利用,需要用.cpu()将数据从GPU中迁出到CPU中
plt.scatter(x.data.cpu().numpy(), y.data.cpu().numpy())
plt.plot(x.data.cpu().numpy(), prediction.data.cpu().numpy(), 'r-', lw=5)
plt.text(0.5, 0, 'Loss=%.4f' % loss.item(), fontdict={'size':20, 'color':'red'})
plt.pause(0.1)
plt.ioff()
plt.show()

以上这篇Pytorch 搭建分类回归神经网络并用GPU进行加速的例子就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。