python批量处理txt文件的实例代码
通过python对多个txt文件进行处理
- 读取路径,读取文件
- 获取文件名,路径名
- 对响应的文件夹名字进行排序
- 对txt文件内部的数据相应的某一列/某一行进行均值处理
- 写入到事先准备好的Excel文件中
- 关闭Excel文件
#import numpy as np
import pandas as pd
import os
folder = 'D:/log/A190820C31N82'
def all_files_in_a_folder_iter(folder):
import os
for root, dirs, files in os.walk(folder):
for file in files:
# 获取文件路径
yield (os.path.join(root, file))
#对CH1-CH2到CH7-CH8的文件夹进行排序
l = os.listdir('D:/log/A190820C31N82/08 583fF 2.3.10.0 30fps')
dic ={}
n=1
for i in l:
if 'CH' in i:
dic[i] = n
n=n+1
#对电容大小排序
dd = os.listdir('D:/log/A190820C31N82')
dsc = {}
m=1
for j in dd:
if 'fF' in j:
dsc[j] = m
m=m+1
#import xlrd
#import xlwt
from openpyxl import load_workbook
#import openpyxl
#打开Excel文件
wb = load_workbook('D:/log/data_process.xlsx')#生成一个已存在的wookbook对象
wb1 = wb.active#激活sheet
for i in all_files_in_a_folder_iter(folder):
if '.txt' in i and 'ECT' in i:
# print(i)
a = pd.read_table(i,header=None)
s = i.split('\\')[2]
t = i.split('\\')[1]
n = dic[s]
m = dsc[t]
res = a.values[:,n].mean() #做均值处理,保存结果
wb1.cell(t*5+1,n+2,res)#往sheet中的第t*5+1行第n+2列写入均值
wb.save('D:/log/data_process.xlsx')#保存
wb.close()
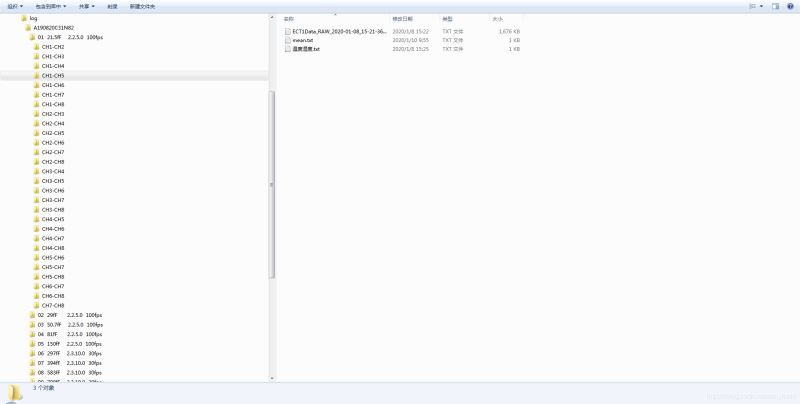
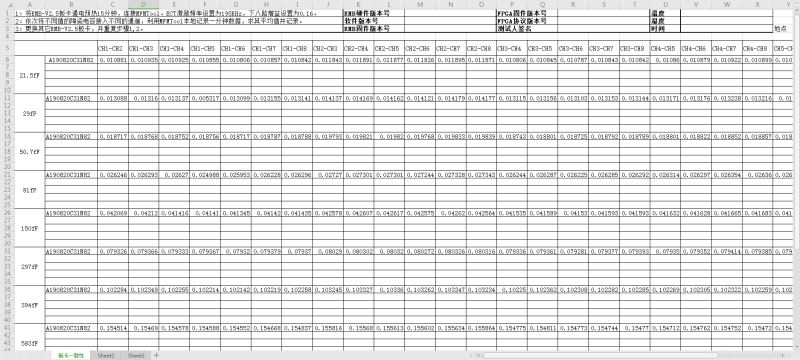
文件结构如下图所示
总结
以上所述是小编给大家介绍的python批量处理txt文件的实例代码,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对【听图阁-专注于Python设计】网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!