基于pytorch的lstm参数使用详解
lstm(*input, **kwargs)
将多层长短时记忆(LSTM)神经网络应用于输入序列。
参数:
input_size:输入'x'中预期特性的数量
hidden_size:隐藏状态'h'中的特性数量
num_layers:循环层的数量。例如,设置' ' num_layers=2 ' '意味着将两个LSTM堆叠在一起,形成一个'堆叠的LSTM ',第二个LSTM接收第一个LSTM的输出并计算最终结果。默认值:1
bias:如果' False',则该层不使用偏置权重' b_ih '和' b_hh '。默认值:'True'
batch_first:如果' 'True ' ',则输入和输出张量作为(batch, seq, feature)提供。默认值: 'False'
dropout:如果非零,则在除最后一层外的每个LSTM层的输出上引入一个“dropout”层,相当于:attr:'dropout'。默认值:0
bidirectional:如果‘True',则成为双向LSTM。默认值:'False'
输入:input,(h_0, c_0)
**input**of shape (seq_len, batch, input_size):包含输入序列特征的张量。输入也可以是一个压缩的可变长度序列。
see:func:'torch.nn.utils.rnn.pack_padded_sequence' 或:func:'torch.nn.utils.rnn.pack_sequence' 的细节。
**h_0** of shape (num_layers * num_directions, batch, hidden_size):张量包含批处理中每个元素的初始隐藏状态。
如果RNN是双向的,num_directions应该是2,否则应该是1。
**c_0** of shape (num_layers * num_directions, batch, hidden_size):张量包含批处理中每个元素的初始单元格状态。
如果没有提供' (h_0, c_0) ',则**h_0**和**c_0**都默认为零。
输出:output,(h_n, c_n)
**output**of shape (seq_len, batch, num_directions * hidden_size) :包含LSTM最后一层输出特征' (h_t) '张量,
对于每个t. If a:class: 'torch.nn.utils.rnn.PackedSequence' 已经给出,输出也将是一个打包序列。
对于未打包的情况,可以使用'output.view(seq_len, batch, num_directions, hidden_size)',正向和反向分别为方向' 0 '和' 1 '。
同样,在包装的情况下,方向可以分开。
**h_n** of shape (num_layers * num_directions, batch, hidden_size):包含' t = seq_len '隐藏状态的张量。
与*output*类似, the layers可以使用以下命令分隔
h_n.view(num_layers, num_directions, batch, hidden_size) 对于'c_n'相似
**c_n** (num_layers * num_directions, batch, hidden_size):张量包含' t = seq_len '的单元状态
所有的权重和偏差都初始化自: 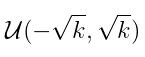 where:
where: 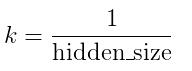
include:: cudnn_persistent_rnn.rst
import torch import torch.nn as nn # 双向rnn例子 # rnn = nn.RNN(10, 20, 2) # input = torch.randn(5, 3, 10) # h0 = torch.randn(2, 3, 20) # output, hn = rnn(input, h0) # print(output.shape,hn.shape) # torch.Size([5, 3, 20]) torch.Size([2, 3, 20]) # 双向lstm例子 rnn = nn.LSTM(10, 20, 2) #(input_size,hidden_size,num_layers) input = torch.randn(5, 3, 10) #(seq_len, batch, input_size) h0 = torch.randn(2, 3, 20) #(num_layers * num_directions, batch, hidden_size) c0 = torch.randn(2, 3, 20) #(num_layers * num_directions, batch, hidden_size) # output:(seq_len, batch, num_directions * hidden_size) # hn,cn(num_layers * num_directions, batch, hidden_size) output, (hn, cn) = rnn(input, (h0, c0)) print(output.shape,hn.shape,cn.shape) >>>torch.Size([5, 3, 20]) torch.Size([2, 3, 20]) torch.Size([2, 3, 20])
以上这篇基于pytorch的lstm参数使用详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。