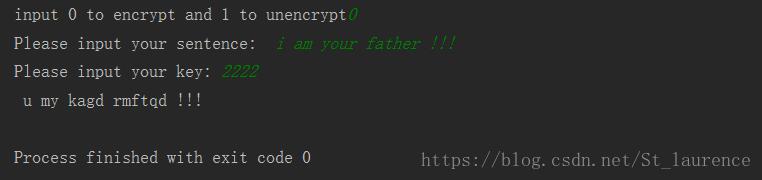
Python Tensor FLow简单使用方法实例详解
本文实例讲述了Python Tensor FLow简单使用方法。分享给大家供大家参考,具体如下:
1、基础概念
Tensor表示张量,是一种多维数组的数据结构。Flow代表流,是指张量之间通过计算而转换的过程。TensorFLow通过一个计算图的形式表示编程过程,数据在每个节点之间流动,经过节点加工之后流向下一个节点。
计算图是一个有向图,其组成如下:节点:代表一个操作。边:代表节点之间的数据传递和控制依赖,其中实线代表两个节点之间的数据传递关系,虚线代表两个节点之间存在控制相关。
张量是所有数据的表示形式,可以将其理解为一个多维数组。零阶张量就是标量(scalar),表示一个数,一阶张量为一维数组,即向量(vector)。n阶张量也就是n维数组。张量并不保存具体数字,它保存的是计算过程。
下面的例子是将节点1、2的值相加得到节点3。
import tensorflow as tf
node1=tf.constant(3.0,tf.float32,name='node1') #创建浮点数节点
node2=tf.constant(4.0,tf.float32,name='node2')
node3=tf.add(node1,node2) #节点三进行相加操作,源于节点1、2
ses=tf.Session()
print(node3) #输出张量:Tensor("Add_3:0", shape=(), dtype=float32)
print(ses.run(node3)) #通过会话运行节点三,将节点1、2相加,输出:7.0
ses.close() #不使用时,关闭会话
直接print(node3)输出的结果不是具体的值,而是张量结构。因为创建计算图只是建立了计算模型,只有会话执行run()才能获得具体结果。
Tensor("Add_3:0", shape=(), dtype=float32)中,Add表示节点名称,3表示这是该节点的第3个输出。shape表示张量的维度信息,()代表标量。dtype表示张量的类型,每个张量的类型唯一,如果不匹配会报错,不带小数点的默认类型为int32,带小数点默认为float35。下面的例子为更复杂的张量类型:
tensor1=tf.constant([[[1,1,1],[1,2,1]],
[[2,1,1],[2,2,1]],
[[3,1,1],[3,2,1]],
[[4,1,1],[4,2,1]]],name='tensor1')
print(tensor1)
ss=tf.Session()
print(ss.run(tensor1)[3,0,0]) #访问tensor1的具体元素
#输出:Tensor("tensor1:0", shape=(4, 2, 3), dtype=int32) 4
其中shape=(4,2,3)表示tensor1的最外层有4个数组,每个数组内有2个子数组,子数组由3个数字构成。可以通过多维数组的方式访问其中的具体元素,[3,0,0]即为第四个数组中第一个子数组的第一个元素,4。
计算图中还有的节点表示操作,例如加减乘除、赋初值等,操作有自己的属性,需要在创建图的时候就确定,操作之间有先后等依赖关系,通过图的边可以直观地看出来。
2、运算
会话
会话(Session)拥有并管理TensorFLow的所有资源,通过Session运行计算才能得到结果,计算完成后记得关闭会话回收资源。下面是使用Session的流程:
#定义计算图 tensor1=tf.constant([1,2,3]) #创建会话 ss=tf.Session() #利用会话进行计算操作 print(ss.run(tensor1)) #关闭会话 ss.close()
也可以通过python上下文管理器来使用Session,当退出上下文时会自动关闭Session并释放资源
tensor1=tf.constant([1,2,3]) with tf.Session() as ss: #上下文管理器 print(ss.run(tensor1))
还可以通过指定默认会话,使用eval()获取张量的值:
tensor1=tf.constant([1,2,3]) ss=tf.Session() with ss.as_default(): #指定默认会话 print(tensor1.eval())
在交互式环境下通过InteractiveSession()自动将生成的会话设为默认:
tensor1=tf.constant([1,2,3]) ss=tf.InteractiveSession() #自动注册默认会话 print(tensor1.eval()) ss.close()
变量、常量
TensorFLow通过constant函数完成对常量的定义,可以为其赋初值与命名
a=tf.constant(10,'int_a')
而变量不仅需要定义,还需要经过初始化后才可以使用,初始化操作不仅需要定义,还需要执行
node1=tf.Variable(3.0,name='node1') #定义变量 node2=tf.Variable(4.0,name='node2') res=tf.add(node1,node2,name='res') ss=tf.Session() init=tf.global_variables_initializer() #定义全部变量的初始化操作 ss.run(init) #执行初始化操作 print(ss.run(res)) ss.close()
TensorFLow的变量一般不需要手动赋值,因为系统会在训练过程中自动调整。如果不希望由模型自动赋值,可以在定义时指定属性trainable=False,并通过assign函数来手动赋值
var1=tf.Variable(0,name='var') one=tf.constant(1) var2=tf.add(var1,one) #变量1加1得到变量2 update=tf.assign(var1,var2) #定义update操作,将变量2赋值给变量1 init=tf.global_variables_initializer() ss=tf.Session() ss.run(init) for _ in range(10): ss.run(update) #执行update操作 print(ss.run(var1)) ss.close() #输出:1 2 3 4 5 6 7 8 9 10
在执行ss.run(update)操作时,由于update需要var1和var2依赖,而得到var2需要执行add操作,因此只需要run一个update就会触发整个计算网络。
占位符
有时在定义变量的时候,并不知道它的具体值,只有在运行的时候才输入对应数值,而tensorflow中变量的定义需要赋初值,这时就需要使用占位符placeholder来进行定义,并在计算时传入具体数值。一个简单的使用例子:
node1=tf.placeholder(tf.float32,name='node1') #定义占位符,规定其类型、结构、名字
node2=tf.placeholder(tf.float32,name='node2')
m=tf.multiply(node1,node2,'multinode')
ss=tf.Session()
res=ss.run(m,feed_dict={node1:1.2,node2:3.4}) #在运行时通过feed_dict为占位符赋值
print(res)
ss.close()
也可以把多个操作放到一次feed操作完成
node1=tf.placeholder(tf.float32,[3],name='node1') #第二个参数规定占位符的类型为3维数组
node2=tf.placeholder(tf.float32,[3],name='node2')
m=tf.multiply(node1,node2,'multinode')
s=tf.subtract(node1,node2,'subnode')
ss=tf.Session()
#将m,s两个操作放到一起,并返回两个结果
resm,ress=ss.run([m,s],feed_dict={node1:[1.0,2.0,4.0],node2:[3.0,5.0,6.0]})
print(resm) #输出:[ 3. 10. 24.]
ss.close()
3、TensorBoard
TensorBoard是TensorFLow的可视化工具,通过程序运行中输出的日志文件可视化地表示TensorFLow的运行状态。其编程如下:
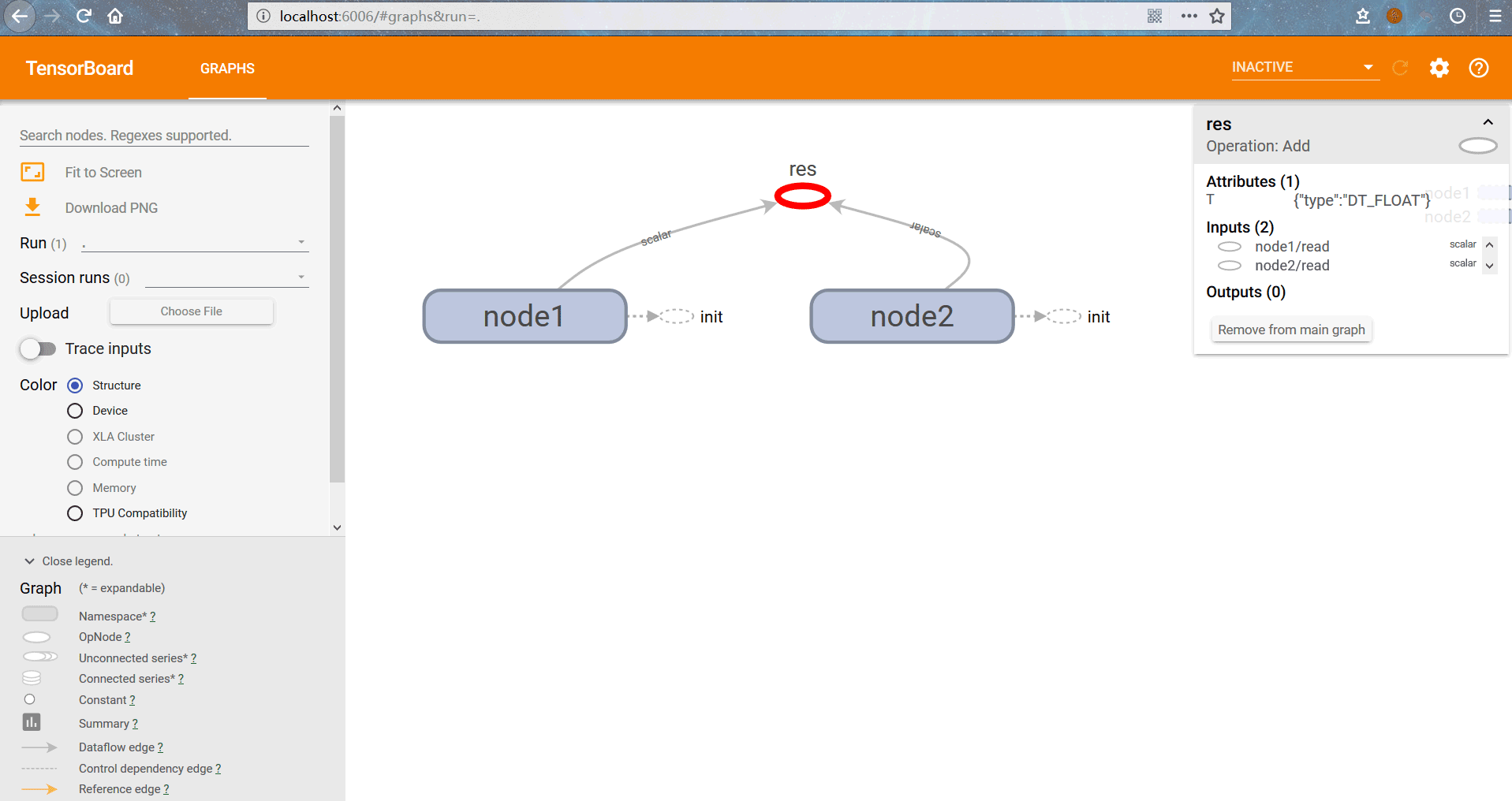
node1=tf.Variable(3.0,name='node1') node2=tf.Variable(4.0,name='node2') res=tf.add(node1,node2,name='res') ss=tf.Session() init=tf.global_variables_initializer() ss.run(init) print(ss.run(res)) ss.close() #清除default graph和其他节点 tf.reset_default_graph() #定义日志存放的默认路径 logdir='D:\Temp\TensorLog' #生成writer将当前的计算图写入日志 writer=tf.summary.FileWriter(logdir,tf.get_default_graph()) writer.close()
TensorBoard已经随Anaconda安装完成,首先通过Anaconda Prompt进入日志文件的存放目录,然后输入tensorboard --logdir=D:\Temp\TensorLog,设定日志的存放路径,完成之后在浏览器的localhost:6006端口就可以看到TensorBoard,也可以通过--port命令修改默认端口。
利用TensorBoard显示图片,通过summary.image()将格式化的图片数据显示,其中输入的image_imput数据是四维格式,第一维表示一次输入几行数据,-1表示不确定。28,28,1表示图片数据为28×28大小,且其色彩通道为1。
通过summary.histogram()可以显示直方图数据。通过summary.scalar()可以显示标量数据。在所有summary定义完成后,可以通过summary.merge_all()函数定义一个汇总操作,将所有summary聚合起来。
在创建session后定义writer用于日志文件的写入,在进行训练时,每批次训练都将执行一次merge操作,并将结果写入日志。
如下为通过多层神经网络解决MNIST手写识别问题的例子,将其中的一些数据通过TensorBoard显示出来:
#TensorBoard使用
#定义日志保存位置
log_dir='D:\Temp\MachineLearning\TensorLog'
#显示图片
image_input=tf.reshape(x,[-1,28,28,1])
tf.summary.image('input',image_input,10) #一次最多显示图片数:10
#显示直方图
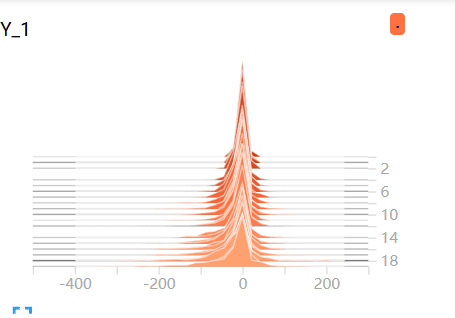
tf.summary.histogram('Y',Y3)
#显示标量loss
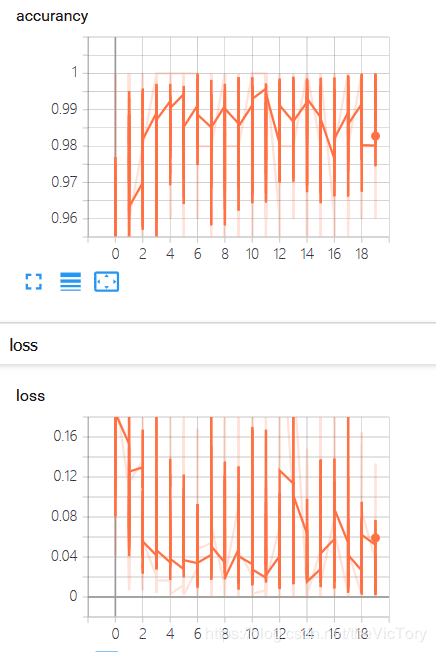
tf.summary.scalar('loss',loss_function)
tf.summary.scalar('accurancy',accuracy)
#定义汇总summary操作
merge_op=tf.summary.merge_all()
ss=tf.Session()
ss.run(tf.global_variables_initializer())
#定义writer
writer=tf.summary.FileWriter(log_dir,ss.graph)
for epoch in range(train_epochs):
for batch in range(batch_num): #分批次读取数据进行训练
xs,ys=mnist.train.next_batch(batch_size)
ss.run(optimizer,feed_dict={x:xs,y:ys})
#执行summary操作并将结果写入日志文件
summary_str=ss.run(merge_op,feed_dict={x:xs,y:ys})
writer.add_summary(summary_str,epoch)
loss,acc=ss.run([loss_function,accuracy],\
feed_dict={x:mnist.validation.images,y:mnist.validation.labels})
print('第%2d轮训练:损失为:%9f,准确率:%.4f'%(epoch+1,loss,acc))
运行结果如下图所示分别为图片、accuracy、loss标量图、Y1直方图以及随之生成的分布图:

更多关于Python相关内容感兴趣的读者可查看本站专题:《Python数据结构与算法教程》、《Python加密解密算法与技巧总结》、《Python编码操作技巧总结》、《Python函数使用技巧总结》、《Python字符串操作技巧汇总》及《Python入门与进阶经典教程》
希望本文所述对大家Python程序设计有所帮助。