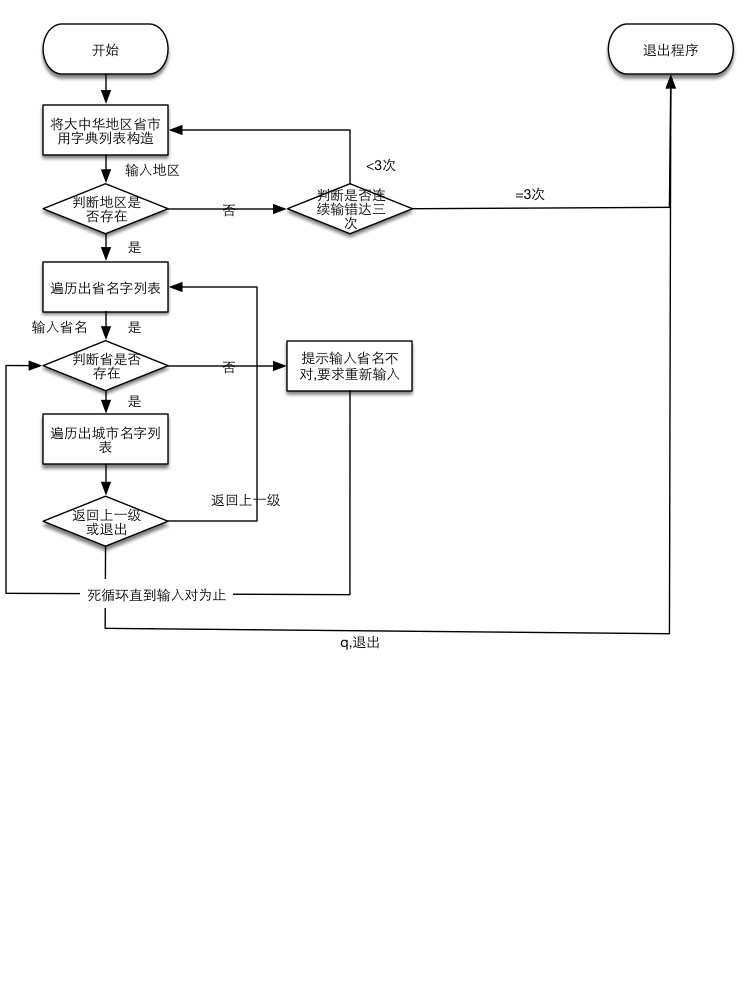
tensorflow中tf.slice和tf.gather切片函数的使用
tf.slice(input_, begin, size, name=None):按照指定的下标范围抽取连续区域的子集
tf.gather(params, indices, validate_indices=None, name=None):按照指定的下标集合从axis=0中抽取子集,适合抽取不连续区域的子集
输出:
input = [[[1, 1, 1], [2, 2, 2]],
[[3, 3, 3], [4, 4, 4]],
[[5, 5, 5], [6, 6, 6]]]
tf.slice(input, [1, 0, 0], [1, 1, 3]) ==> [[[3, 3, 3]]]
tf.slice(input, [1, 0, 0], [1, 2, 3]) ==> [[[3, 3, 3],
[4, 4, 4]]]
tf.slice(input, [1, 0, 0], [2, 1, 3]) ==> [[[3, 3, 3]],
[[5, 5, 5]]]
tf.gather(input, [0, 2]) ==> [[[1, 1, 1], [2, 2, 2]],
[[5, 5, 5], [6, 6, 6]]]
假设我们要从input中抽取[[[3, 3, 3]]],这个输出在inputaxis=0的下标是1,axis=1的下标是0,axis=2的下标是0-2,所以begin=[1,0,0],size=[1,1,3]。
假设我们要从input中抽取[[[3, 3, 3], [4, 4, 4]]],这个输出在inputaxis=0的下标是1,axis=1的下标是0-1,axis=2的下标是0-2,所以begin=[1,0,0],size=[1,2,3]。
假设我们要从input中抽取[[[3, 3, 3], [5, 5, 5]]],这个输出在inputaxis=0的下标是1-2,axis=1的下标是0,axis=2的下标是0-2,所以begin=[1,0,0],size=[2,1,3]。
假设我们要从input中抽取[[[1, 1, 1], [2, 2, 2]],[[5, 5, 5], [6, 6, 6]]],这个输出在input的axis=0的下标是[0, 2],不连续,可以用tf.gather抽取。input[0]和input[2]
以上这篇tensorflow中tf.slice和tf.gather切片函数的使用就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。